 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnsuring the Robustness and Reliability of Data-Driven Knowledge Discovery Models in Production and Manufacturing
Paper and Code
Jul 28, 2020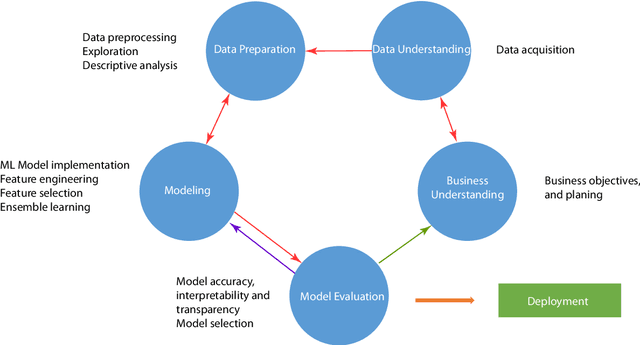
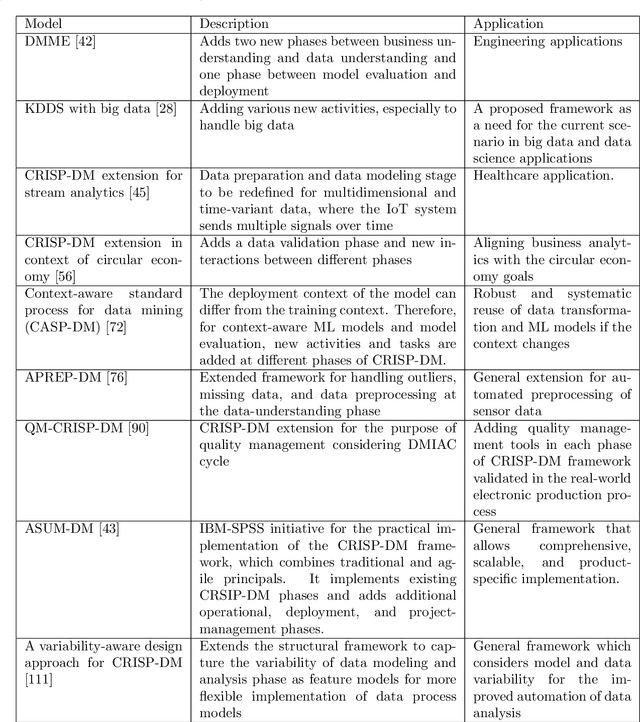
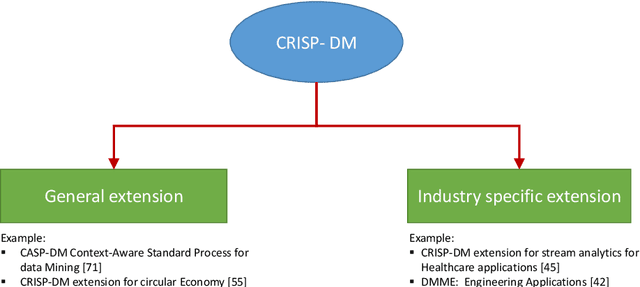
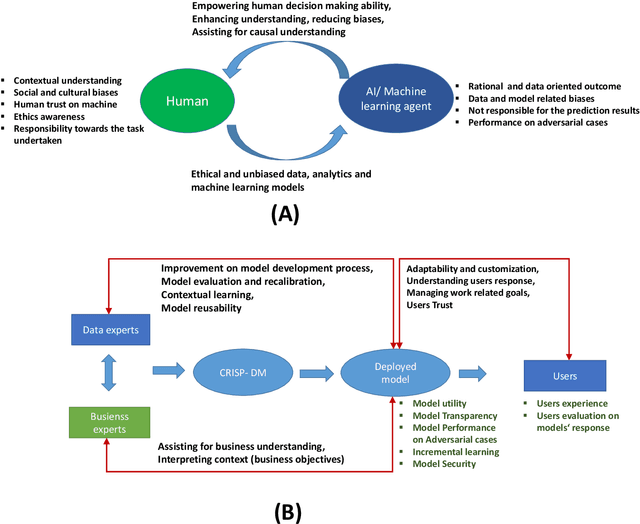
The implementation of robust, stable, and user-centered data analytics and machine learning models is confronted by numerous challenges in production and manufacturing. Therefore, a systematic approach is required to develop, evaluate, and deploy such models. The data-driven knowledge discovery framework provides an orderly partition of the data-mining processes to ensure the practical implementation of data analytics and machine learning models. However, the practical application of robust industry-specific data-driven knowledge discovery models faces multiple data-- and model-development--related issues. These issues should be carefully addressed by allowing a flexible, customized, and industry-specific knowledge discovery framework; in our case, this takes the form of the cross-industry standard process for data mining (CRISP-DM). This framework is designed to ensure active cooperation between different phases to adequately address data- and model-related issues. In this paper, we review several extensions of CRISP-DM models and various data-robustness-- and model-robustness--related problems in machine learning, which currently lacks proper cooperation between data experts and business experts because of the limitations of data-driven knowledge discovery models.