 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Competition Outperform Collaboration? The Role of Malicious Agents
Jul 04, 2022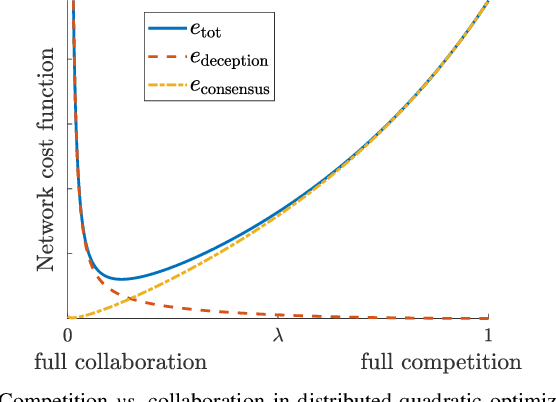
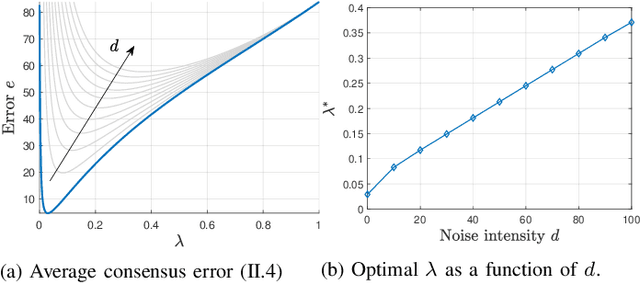
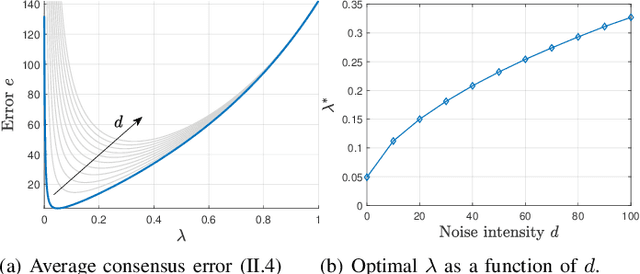

We investigate a novel approach to resilient distributed optimization with quadratic costs in a Networked Control System prone to exogenous attacks that make agents misbehave. In contrast with commonly adopted filtering strategies, we draw inspiration from a game-theoretic formulation of the consensus problem and argue that adding competition to the mix can improve resilience in the presence of malicious agents. Our intuition is corroborated by analytical and numerical results showing that (i) our strategy reveals a nontrivial performance trade-off between full collaboration and full competition, and (ii) such competitionbased approach can outperform state-of-the-art algorithms based on Mean Subsequence Reduced. Finally, we study impact of communication topology and connectivity on performance, pointing out insights to robust network design.
RISCuer: A Reliable Multi-UAV Search and Rescue Testbed
Jun 12, 2020


We present the RISC Lab multi-agent testbed for reliable search and rescue and aerial transport in outdoor environments. The system consists of a team of three multi-rotor Unmanned Aerial Vehicles (UAVs), which are capable of autonomously searching, picking, and transporting randomly distributed objects in an outdoor field. The method involves vision based object detection and localization, passive aerial grasping with our novel design, GPS based UAV navigation, and safe release of the objects at the drop zone. Our cooperative strategy ensures safe spatial separation between UAVs at all times and we prevent any conflicts at the drop zone using communication enabled consensus. All computation is performed onboard each UAV. We describe the complete software and hardware architecture for the system and demonstrate its reliable performance using comprehensive outdoor experiments and by comparing our results with some recent, similar works.
usBot: A Modular Robotic Testbed for Programmable Self-Assembly
Feb 27, 2019
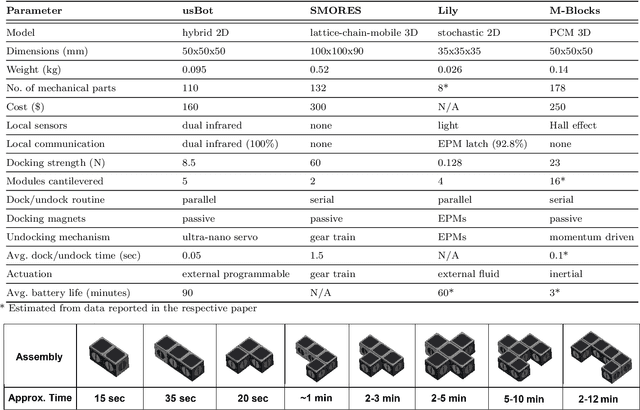
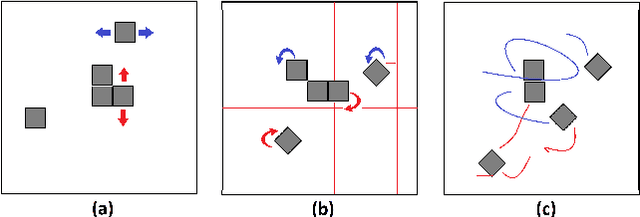
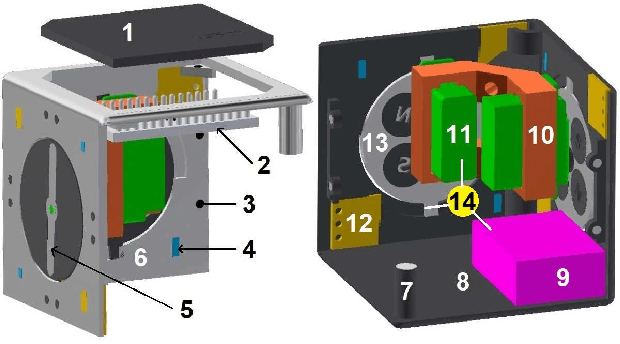
We present the design, characterization, and experimental results for a new modular robotic system for programmable self-assembly. The proposed system uses the Hybrid Cube Model (HCM), which integrates classical features from both deterministic and stochastic self-organization models. Thus, for instance, the modules are passive as far as their locomotion is concerned (stochastic), and yet they possess an active undocking routine (deterministic). The robots are constructed entirely from readily accessible components, and unlike many existing robots, their excitation is not fluid mediated. Instead, the actuation setup is a solid state, independently programmable, and highly portable platform. The system is capable of demonstrating fully autonomous and distributed stochastic self-assembly in two dimensions. It is shown to emulate the performance of several existing modular systems and promises to be a substantial effort towards developing a universal testbed for programmable self-assembly algorithms.
Infrastructure-free Localization of Aerial Robots with Ultrawideband Sensors
Sep 21, 2018



Robots in a swarm take advantage of a motion capture system or GPS sensors to obtain their global position. However, motion capture systems are environment-dependent and GPS sensors are not reliable in occluded environments. For a reliable and versatile operation in a swarm, robots must sense each other and interact locally. Motivated by this requirement, here we propose an on-board localization framework for multi-robot systems. Our framework consists of an anchor robot with three ultrawideband (UWB) sensors and a tag robot with a single UWB sensor. The anchor robot utilizes the three UWB sensors as a localization infrastructure and estimates the tag robot's location by using its on-board sensing and computational capabilities solely, without explicit inter-robot communication. We utilize a dual Monte-Carlo localization approach to capture the agile maneuvers of the tag robot with an acceptable precision. We validate the effectiveness of our algorithm with simulations and indoor and outdoor experiments on a two-drone setup. The proposed dual MCL algorithm yields highly accurate estimates for various speed profiles of the tag robot and demonstrates a superior performance over the standard particle filter and the extended Kalman Filter.
Path to Stochastic Stability: Comparative Analysis of Stochastic Learning Dynamics in Games
Apr 08, 2018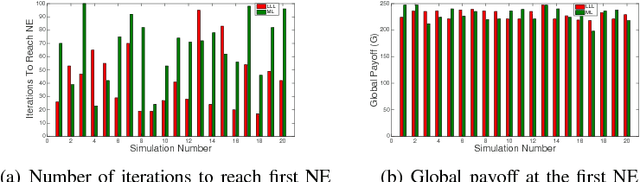
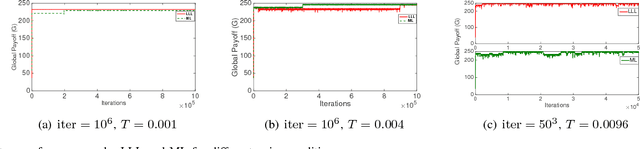
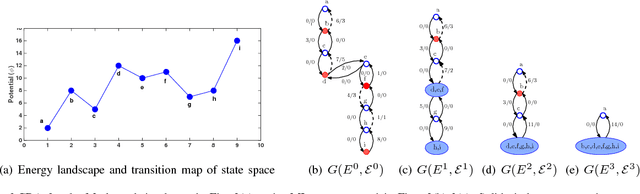
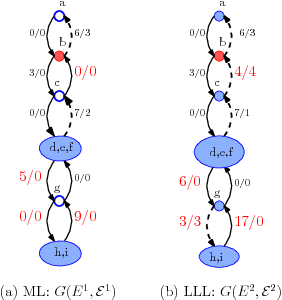
Stochastic stability is a popular solution concept for stochastic learning dynamics in games. However, a critical limitation of this solution concept is its inability to distinguish between different learning rules that lead to the same steady-state behavior. We address this limitation for the first time and develop a framework for the comparative analysis of stochastic learning dynamics with different update rules but same steady-state behavior. We present the framework in the context of two learning dynamics: Log-Linear Learning (LLL) and Metropolis Learning (ML). Although both of these dynamics have the same stochastically stable states, LLL and ML correspond to different behavioral models for decision making. Moreover, we demonstrate through an example setup of sensor coverage game that for each of these dynamics, the paths to stochastically stable states exhibit distinctive behaviors. Therefore, we propose multiple criteria to analyze and quantify the differences in the short and medium run behavior of stochastic learning dynamics. We derive and compare upper bounds on the expected hitting time to the set of Nash equilibria for both LLL and ML. For the medium to long-run behavior, we identify a set of tools from the theory of perturbed Markov chains that result in a hierarchical decomposition of the state space into collections of states called cycles. We compare LLL and ML based on the proposed criteria and develop invaluable insights into the comparative behavior of the two dynamics.
Communication-Free Distributed Coverage for Networked Systems
May 23, 2015



In this paper, we present a communication-free algorithm for distributed coverage of an arbitrary network by a group of mobile agents with local sensing capabilities. The network is represented as a graph, and the agents are arbitrarily deployed on some nodes of the graph. Any node of the graph is covered if it is within the sensing range of at least one agent. The agents are mobile devices that aim to explore the graph and to optimize their locations in a decentralized fashion by relying only on their sensory inputs. We formulate this problem in a game theoretic setting and propose a communication-free learning algorithm for maximizing the coverage.
Aspiration Learning in Coordination Games
Oct 19, 2011



We consider the problem of distributed convergence to efficient outcomes in coordination games through dynamics based on aspiration learning. Under aspiration learning, a player continues to play an action as long as the rewards received exceed a specified aspiration level. Here, the aspiration level is a fading memory average of past rewards, and these levels also are subject to occasional random perturbations. A player becomes dissatisfied whenever a received reward is less than the aspiration level, in which case the player experiments with a probability proportional to the degree of dissatisfaction. Our first contribution is the characterization of the asymptotic behavior of the induced Markov chain of the iterated process in terms of an equivalent finite-state Markov chain. We then characterize explicitly the behavior of the proposed aspiration learning in a generalized version of coordination games, examples of which include network formation and common-pool games. In particular, we show that in generic coordination games the frequency at which an efficient action profile is played can be made arbitrarily large. Although convergence to efficient outcomes is desirable, in several coordination games, such as common-pool games, attainability of fair outcomes, i.e., sequences of plays at which players experience highly rewarding returns with the same frequency, might also be of special interest. To this end, we demonstrate through analysis and simulations that aspiration learning also establishes fair outcomes in all symmetric coordination games, including common-pool games.