 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTalkWithMachines: Enhancing Human-Robot Interaction for Interpretable Industrial Robotics Through Large/Vision Language Models
Dec 19, 2024TalkWithMachines aims to enhance human-robot interaction by contributing to interpretable industrial robotic systems, especially for safety-critical applications. The presented paper investigates recent advancements in Large Language Models (LLMs) and Vision Language Models (VLMs), in combination with robotic perception and control. This integration allows robots to understand and execute commands given in natural language and to perceive their environment through visual and/or descriptive inputs. Moreover, translating the LLM's internal states and reasoning into text that humans can easily understand ensures that operators gain a clearer insight into the robot's current state and intentions, which is essential for effective and safe operation. Our paper outlines four LLM-assisted simulated robotic control workflows, which explore (i) low-level control, (ii) the generation of language-based feedback that describes the robot's internal states, (iii) the use of visual information as additional input, and (iv) the use of robot structure information for generating task plans and feedback, taking the robot's physical capabilities and limitations into account. The proposed concepts are presented in a set of experiments, along with a brief discussion. Project description, videos, and supplementary materials will be available on the project website: https://talk-machines.github.io.
Safety-Driven Deep Reinforcement Learning Framework for Cobots: A Sim2Real Approach
Jul 02, 2024This study presents a novel methodology incorporating safety constraints into a robotic simulation during the training of deep reinforcement learning (DRL). The framework integrates specific parts of the safety requirements, such as velocity constraints, as specified by ISO 10218, directly within the DRL model that becomes a part of the robot's learning algorithm. The study then evaluated the efficiency of these safety constraints by subjecting the DRL model to various scenarios, including grasping tasks with and without obstacle avoidance. The validation process involved comprehensive simulation-based testing of the DRL model's responses to potential hazards and its compliance. Also, the performance of the system is carried out by the functional safety standards IEC 61508 to determine the safety integrity level. The study indicated a significant improvement in the safety performance of the robotic system. The proposed DRL model anticipates and mitigates hazards while maintaining operational efficiency. This study was validated in a testbed with a collaborative robotic arm with safety sensors and assessed with metrics such as the average number of safety violations, obstacle avoidance, and the number of successful grasps. The proposed approach outperforms the conventional method by a 16.5% average success rate on the tested scenarios in the simulations and 2.5% in the testbed without safety violations. The project repository is available at https://github.com/ammar-n-abbas/sim2real-ur-gym-gazebo.
Analyzing Operator States and the Impact of AI-Enhanced Decision Support in Control Rooms: A Human-in-the-Loop Specialized Reinforcement Learning Framework for Intervention Strategies
Feb 20, 2024In complex industrial and chemical process control rooms, effective decision-making is crucial for safety and efficiency. The experiments in this paper evaluate the impact and applications of an AI-based decision support system integrated into an improved human-machine interface, using dynamic influence diagrams, a hidden Markov model, and deep reinforcement learning. The enhanced support system aims to reduce operator workload, improve situational awareness, and provide different intervention strategies to the operator adapted to the current state of both the system and human performance. Such a system can be particularly useful in cases of information overload when many alarms and inputs are presented all within the same time window, or for junior operators during training. A comprehensive cross-data analysis was conducted, involving 47 participants and a diverse range of data sources such as smartwatch metrics, eye-tracking data, process logs, and responses from questionnaires. The results indicate interesting insights regarding the effectiveness of the approach in aiding decision-making, decreasing perceived workload, and increasing situational awareness for the scenarios considered. Additionally, the results provide valuable insights to compare differences between styles of information gathering when using the system by individual participants. These findings are particularly relevant when predicting the overall performance of the individual participant and their capacity to successfully handle a plant upset and the alarms connected to it using process and human-machine interaction logs in real-time. These predictions enable the development of more effective intervention strategies.
Hierarchical Framework for Interpretable and Probabilistic Model-Based Safe Reinforcement Learning
Oct 28, 2023
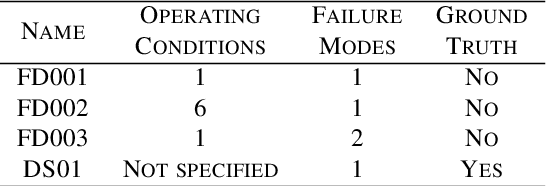


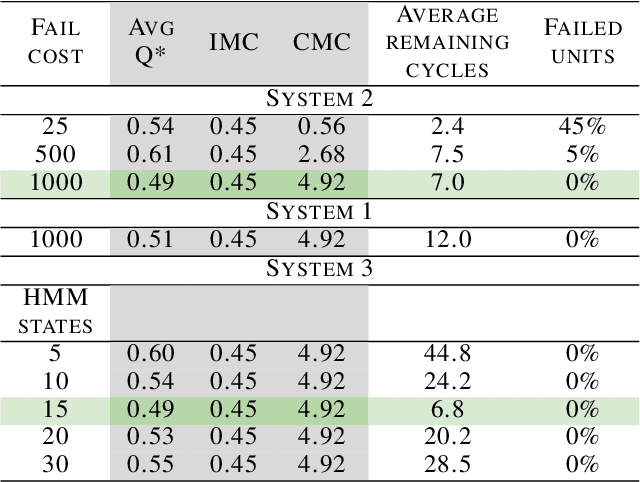
The difficulty of identifying the physical model of complex systems has led to exploring methods that do not rely on such complex modeling of the systems. Deep reinforcement learning has been the pioneer for solving this problem without the need for relying on the physical model of complex systems by just interacting with it. However, it uses a black-box learning approach that makes it difficult to be applied within real-world and safety-critical systems without providing explanations of the actions derived by the model. Furthermore, an open research question in deep reinforcement learning is how to focus the policy learning of critical decisions within a sparse domain. This paper proposes a novel approach for the use of deep reinforcement learning in safety-critical systems. It combines the advantages of probabilistic modeling and reinforcement learning with the added benefits of interpretability and works in collaboration and synchronization with conventional decision-making strategies. The BC-SRLA is activated in specific situations which are identified autonomously through the fused information of probabilistic model and reinforcement learning, such as abnormal conditions or when the system is near-to-failure. Further, it is initialized with a baseline policy using policy cloning to allow minimum interactions with the environment to address the challenges associated with using RL in safety-critical industries. The effectiveness of the BC-SRLA is demonstrated through a case study in maintenance applied to turbofan engines, where it shows superior performance to the prior art and other baselines.
* arXiv admin note: text overlap with arXiv:2206.13433
Specialized Deep Residual Policy Safe Reinforcement Learning-Based Controller for Complex and Continuous State-Action Spaces
Oct 15, 2023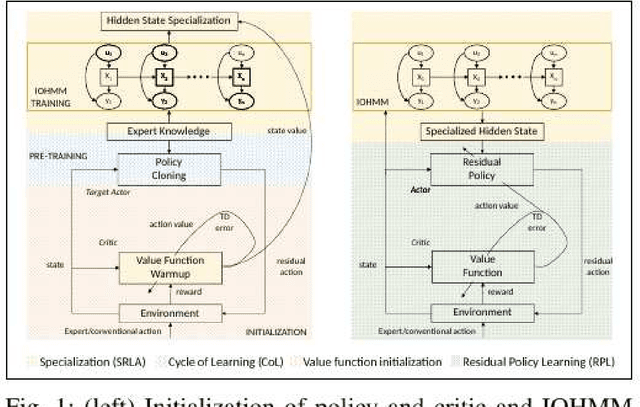
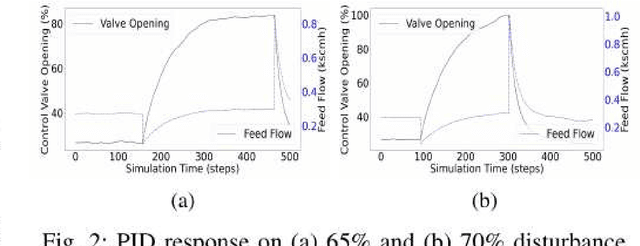
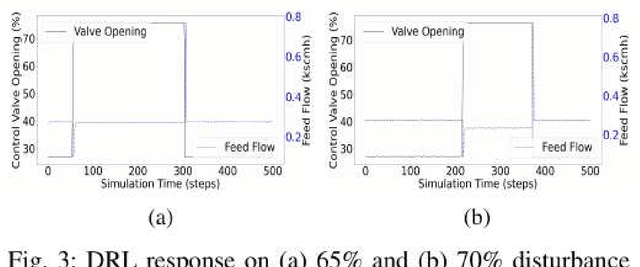
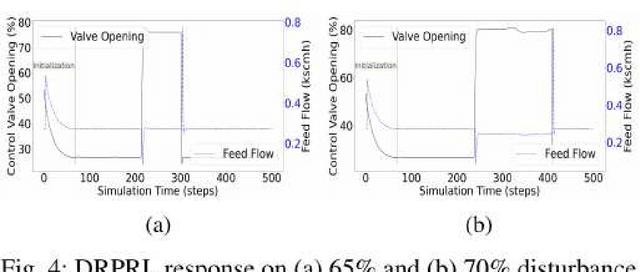
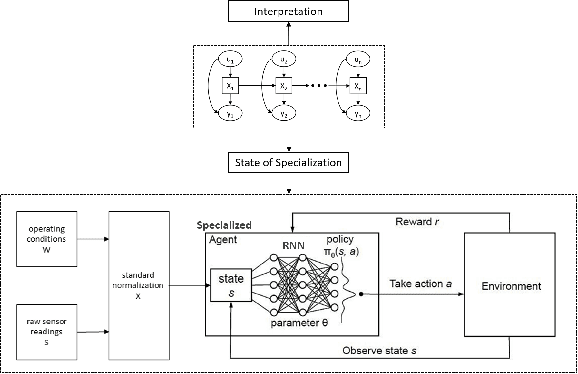
Traditional controllers have limitations as they rely on prior knowledge about the physics of the problem, require modeling of dynamics, and struggle to adapt to abnormal situations. Deep reinforcement learning has the potential to address these problems by learning optimal control policies through exploration in an environment. For safety-critical environments, it is impractical to explore randomly, and replacing conventional controllers with black-box models is also undesirable. Also, it is expensive in continuous state and action spaces, unless the search space is constrained. To address these challenges we propose a specialized deep residual policy safe reinforcement learning with a cycle of learning approach adapted for complex and continuous state-action spaces. Residual policy learning allows learning a hybrid control architecture where the reinforcement learning agent acts in synchronous collaboration with the conventional controller. The cycle of learning initiates the policy through the expert trajectory and guides the exploration around it. Further, the specialization through the input-output hidden Markov model helps to optimize policy that lies within the region of interest (such as abnormality), where the reinforcement learning agent is required and is activated. The proposed solution is validated on the Tennessee Eastman process control.
Interpretable Hidden Markov Model-Based Deep Reinforcement Learning Hierarchical Framework for Predictive Maintenance of Turbofan Engines
Jun 27, 2022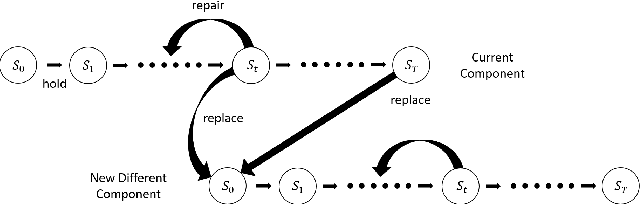
An open research question in deep reinforcement learning is how to focus the policy learning of key decisions within a sparse domain. This paper emphasizes combining the advantages of inputoutput hidden Markov models and reinforcement learning towards interpretable maintenance decisions. We propose a novel hierarchical-modeling methodology that, at a high level, detects and interprets the root cause of a failure as well as the health degradation of the turbofan engine, while, at a low level, it provides the optimal replacement policy. It outperforms the baseline performance of deep reinforcement learning methods applied directly to the raw data or when using a hidden Markov model without such a specialized hierarchy. It also provides comparable performance to prior work, however, with the additional benefit of interpretability.
Siamese Network Training Using Sampled Triplets and Image Transformation
Jun 13, 2021

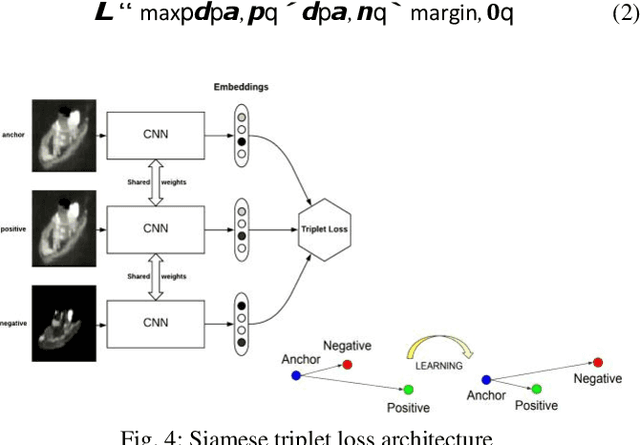

The device used in this work detects the objects over the surface of the water using two thermal cameras which aid the users to detect and avoid the objects in scenarios where the human eyes cannot (night, fog, etc.). To avoid the obstacle collision autonomously, it is required to track the objects in real-time and assign a specific identity to each object to determine its dynamics (trajectory, velocity, etc.) for making estimated collision predictions. In the following work, a Machine Learning (ML) approach for Computer Vision (CV) called Convolutional Neural Network (CNN) was used using TensorFlow as the high-level programming environment in Python. To validate the algorithm a test set was generated using an annotation tool that was created during the work for proper evaluation. Once validated, the algorithm was deployed on the platform and tested with the sequence generated by the test boat.
Experimental Analysis of Trajectory Control Using Computer Vision and Artificial Intelligence for Autonomous Vehicles
Jun 13, 2021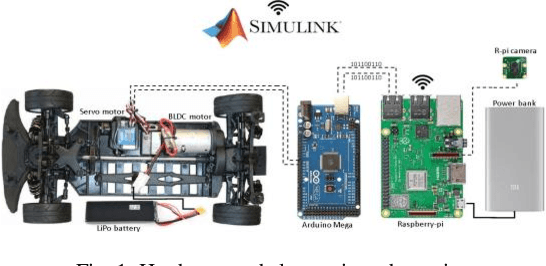
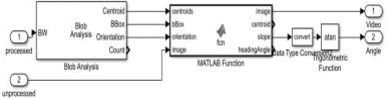

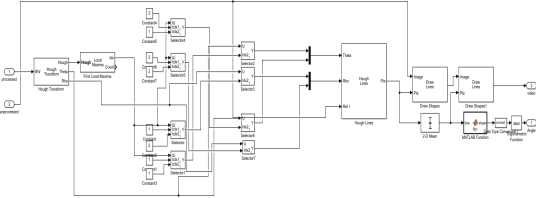
Perception of the lane boundaries is crucial for the tasks related to autonomous trajectory control. In this paper, several methodologies for lane detection are discussed with an experimental illustration: Hough transformation, Blob analysis, and Bird's eye view. Following the abstraction of lane marks from the boundary, the next approach is applying a control law based on the perception to control steering and speed control. In the following, a comparative analysis is made between an open-loop response, PID control, and a neural network control law through graphical statistics. To get the perception of the surrounding a wireless streaming camera connected to Raspberry Pi is used. After pre-processing the signal received by the camera the output is sent back to the Raspberry Pi that processes the input and communicates the control to the motors through Arduino via serial communication.