 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeADAPT: An Autonomous Forklift for Construction Site Operation
Mar 18, 2025

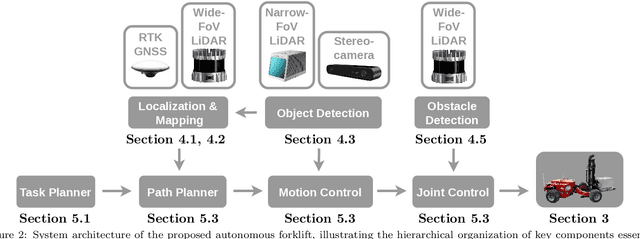

Efficient material logistics play a critical role in controlling costs and schedules in the construction industry. However, manual material handling remains prone to inefficiencies, delays, and safety risks. Autonomous forklifts offer a promising solution to streamline on-site logistics, reducing reliance on human operators and mitigating labor shortages. This paper presents the development and evaluation of the Autonomous Dynamic All-terrain Pallet Transporter (ADAPT), a fully autonomous off-road forklift designed for construction environments. Unlike structured warehouse settings, construction sites pose significant challenges, including dynamic obstacles, unstructured terrain, and varying weather conditions. To address these challenges, our system integrates AI-driven perception techniques with traditional approaches for decision making, planning, and control, enabling reliable operation in complex environments. We validate the system through extensive real-world testing, comparing its long-term performance against an experienced human operator across various weather conditions. We also provide a comprehensive analysis of challenges and key lessons learned, contributing to the advancement of autonomous heavy machinery. Our findings demonstrate that autonomous outdoor forklifts can operate near human-level performance, offering a viable path toward safer and more efficient construction logistics.
TalkWithMachines: Enhancing Human-Robot Interaction for Interpretable Industrial Robotics Through Large/Vision Language Models
Dec 19, 2024TalkWithMachines aims to enhance human-robot interaction by contributing to interpretable industrial robotic systems, especially for safety-critical applications. The presented paper investigates recent advancements in Large Language Models (LLMs) and Vision Language Models (VLMs), in combination with robotic perception and control. This integration allows robots to understand and execute commands given in natural language and to perceive their environment through visual and/or descriptive inputs. Moreover, translating the LLM's internal states and reasoning into text that humans can easily understand ensures that operators gain a clearer insight into the robot's current state and intentions, which is essential for effective and safe operation. Our paper outlines four LLM-assisted simulated robotic control workflows, which explore (i) low-level control, (ii) the generation of language-based feedback that describes the robot's internal states, (iii) the use of visual information as additional input, and (iv) the use of robot structure information for generating task plans and feedback, taking the robot's physical capabilities and limitations into account. The proposed concepts are presented in a set of experiments, along with a brief discussion. Project description, videos, and supplementary materials will be available on the project website: https://talk-machines.github.io.
RGB-D Railway Platform Monitoring and Scene Understanding for Enhanced Passenger Safety
Feb 23, 2021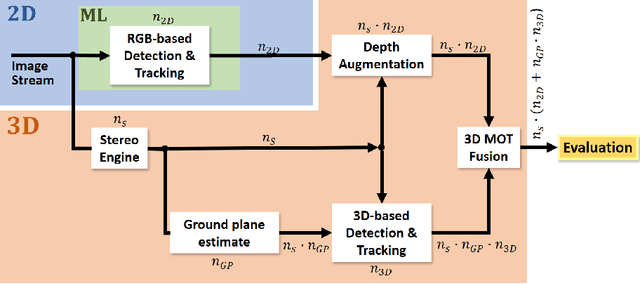

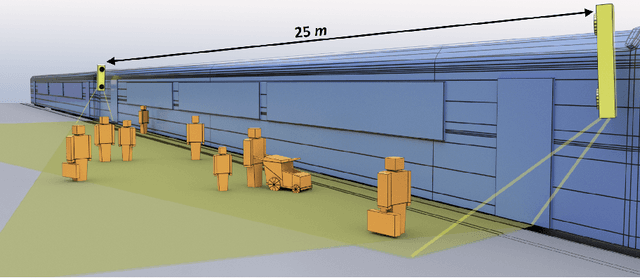

Automated monitoring and analysis of passenger movement in safety-critical parts of transport infrastructures represent a relevant visual surveillance task. Recent breakthroughs in visual representation learning and spatial sensing opened up new possibilities for detecting and tracking humans and objects within a 3D spatial context. This paper proposes a flexible analysis scheme and a thorough evaluation of various processing pipelines to detect and track humans on a ground plane, calibrated automatically via stereo depth and pedestrian detection. We consider multiple combinations within a set of RGB- and depth-based detection and tracking modalities. We exploit the modular concepts of Meshroom [2] and demonstrate its use as a generic vision processing pipeline and scalable evaluation framework. Furthermore, we introduce a novel open RGB-D railway platform dataset with annotations to support research activities in automated RGB-D surveillance. We present quantitative results for multiple object detection and tracking for various algorithmic combinations on our dataset. Results indicate that the combined use of depth-based spatial information and learned representations yields substantially enhanced detection and tracking accuracies. As demonstrated, these enhancements are especially pronounced in adverse situations when occlusions and objects not captured by learned representations are present.
* The final authenticated version is available online at https://doi.org/10.1007/978-3-030-68787-8_47