 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemanticSugarBeets: A Multi-Task Framework and Dataset for Inspecting Harvest and Storage Characteristics of Sugar Beets
Apr 23, 2025While sugar beets are stored prior to processing, they lose sugar due to factors such as microorganisms present in adherent soil and excess vegetation. Their automated visual inspection promises to aide in quality assurance and thereby increase efficiency throughout the processing chain of sugar production. In this work, we present a novel high-quality annotated dataset and two-stage method for the detection, semantic segmentation and mass estimation of post-harvest and post-storage sugar beets in monocular RGB images. We conduct extensive ablation experiments for the detection of sugar beets and their fine-grained semantic segmentation regarding damages, rot, soil adhesion and excess vegetation. For these tasks, we evaluate multiple image sizes, model architectures and encoders, as well as the influence of environmental conditions. Our experiments show an mAP50-95 of 98.8 for sugar-beet detection and an mIoU of 64.0 for the best-performing segmentation model.
TimberVision: A Multi-Task Dataset and Framework for Log-Component Segmentation and Tracking in Autonomous Forestry Operations
Jan 13, 2025



Timber represents an increasingly valuable and versatile resource. However, forestry operations such as harvesting, handling and measuring logs still require substantial human labor in remote environments posing significant safety risks. Progressively automating these tasks has the potential of increasing their efficiency as well as safety, but requires an accurate detection of individual logs as well as live trees and their context. Although initial approaches have been proposed for this challenging application domain, specialized data and algorithms are still too scarce to develop robust solutions. To mitigate this gap, we introduce the TimberVision dataset, consisting of more than 2k annotated RGB images containing a total of 51k trunk components including cut and lateral surfaces, thereby surpassing any existing dataset in this domain in terms of both quantity and detail by a large margin. Based on this data, we conduct a series of ablation experiments for oriented object detection and instance segmentation and evaluate the influence of multiple scene parameters on model performance. We introduce a generic framework to fuse the components detected by our models for both tasks into unified trunk representations. Furthermore, we automatically derive geometric properties and apply multi-object tracking to further enhance robustness. Our detection and tracking approach provides highly descriptive and accurate trunk representations solely from RGB image data, even under challenging environmental conditions. Our solution is suitable for a wide range of application scenarios and can be readily combined with other sensor modalities.
RGB-D Railway Platform Monitoring and Scene Understanding for Enhanced Passenger Safety
Feb 23, 2021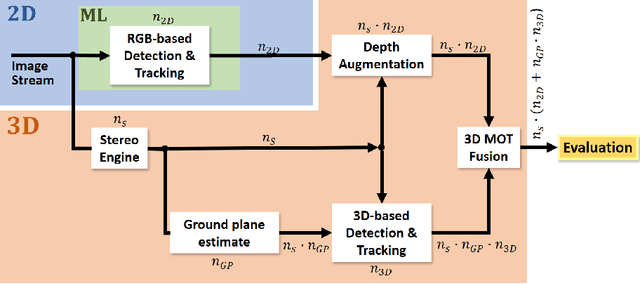

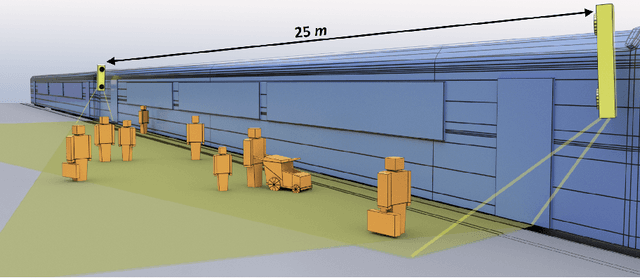

Automated monitoring and analysis of passenger movement in safety-critical parts of transport infrastructures represent a relevant visual surveillance task. Recent breakthroughs in visual representation learning and spatial sensing opened up new possibilities for detecting and tracking humans and objects within a 3D spatial context. This paper proposes a flexible analysis scheme and a thorough evaluation of various processing pipelines to detect and track humans on a ground plane, calibrated automatically via stereo depth and pedestrian detection. We consider multiple combinations within a set of RGB- and depth-based detection and tracking modalities. We exploit the modular concepts of Meshroom [2] and demonstrate its use as a generic vision processing pipeline and scalable evaluation framework. Furthermore, we introduce a novel open RGB-D railway platform dataset with annotations to support research activities in automated RGB-D surveillance. We present quantitative results for multiple object detection and tracking for various algorithmic combinations on our dataset. Results indicate that the combined use of depth-based spatial information and learned representations yields substantially enhanced detection and tracking accuracies. As demonstrated, these enhancements are especially pronounced in adverse situations when occlusions and objects not captured by learned representations are present.
* The final authenticated version is available online at https://doi.org/10.1007/978-3-030-68787-8_47