 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePIRATR: Parametric Object Inference for Robotic Applications with Transformers in 3D Point Clouds
Feb 05, 2026We present PIRATR, an end-to-end 3D object detection framework for robotic use cases in point clouds. Extending PI3DETR, our method streamlines parametric 3D object detection by jointly estimating multi-class 6-DoF poses and class-specific parametric attributes directly from occlusion-affected point cloud data. This formulation enables not only geometric localization but also the estimation of task-relevant properties for parametric objects, such as a gripper's opening, where the 3D model is adjusted according to simple, predefined rules. The architecture employs modular, class-specific heads, making it straightforward to extend to novel object types without re-designing the pipeline. We validate PIRATR on an automated forklift platform, focusing on three structurally and functionally diverse categories: crane grippers, loading platforms, and pallets. Trained entirely in a synthetic environment, PIRATR generalizes effectively to real outdoor LiDAR scans, achieving a detection mAP of 0.919 without additional fine-tuning. PIRATR establishes a new paradigm of pose-aware, parameterized perception. This bridges the gap between low-level geometric reasoning and actionable world models, paving the way for scalable, simulation-trained perception systems that can be deployed in dynamic robotic environments. Code available at https://github.com/swingaxe/piratr.
ADAPT: An Autonomous Forklift for Construction Site Operation
Mar 18, 2025

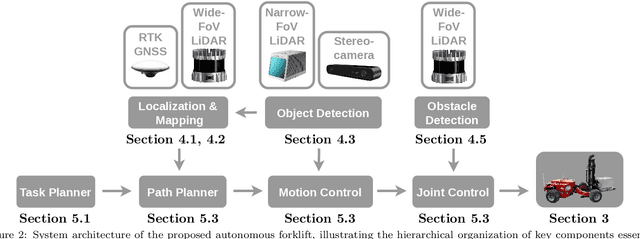

Efficient material logistics play a critical role in controlling costs and schedules in the construction industry. However, manual material handling remains prone to inefficiencies, delays, and safety risks. Autonomous forklifts offer a promising solution to streamline on-site logistics, reducing reliance on human operators and mitigating labor shortages. This paper presents the development and evaluation of the Autonomous Dynamic All-terrain Pallet Transporter (ADAPT), a fully autonomous off-road forklift designed for construction environments. Unlike structured warehouse settings, construction sites pose significant challenges, including dynamic obstacles, unstructured terrain, and varying weather conditions. To address these challenges, our system integrates AI-driven perception techniques with traditional approaches for decision making, planning, and control, enabling reliable operation in complex environments. We validate the system through extensive real-world testing, comparing its long-term performance against an experienced human operator across various weather conditions. We also provide a comprehensive analysis of challenges and key lessons learned, contributing to the advancement of autonomous heavy machinery. Our findings demonstrate that autonomous outdoor forklifts can operate near human-level performance, offering a viable path toward safer and more efficient construction logistics.
Few-shot Structure-Informed Machinery Part Segmentation with Foundation Models and Graph Neural Networks
Jan 17, 2025This paper proposes a novel approach to few-shot semantic segmentation for machinery with multiple parts that exhibit spatial and hierarchical relationships. Our method integrates the foundation models CLIPSeg and Segment Anything Model (SAM) with the interest point detector SuperPoint and a graph convolutional network (GCN) to accurately segment machinery parts. By providing 1 to 25 annotated samples, our model, evaluated on a purely synthetic dataset depicting a truck-mounted loading crane, achieves effective segmentation across various levels of detail. Training times are kept under five minutes on consumer GPUs. The model demonstrates robust generalization to real data, achieving a qualitative synthetic-to-real generalization with a $J\&F$ score of 92.2 on real data using 10 synthetic support samples. When benchmarked on the DAVIS 2017 dataset, it achieves a $J\&F$ score of 71.5 in semi-supervised video segmentation with three support samples. This method's fast training times and effective generalization to real data make it a valuable tool for autonomous systems interacting with machinery and infrastructure, and illustrate the potential of combined and orchestrated foundation models for few-shot segmentation tasks.
TimberVision: A Multi-Task Dataset and Framework for Log-Component Segmentation and Tracking in Autonomous Forestry Operations
Jan 13, 2025



Timber represents an increasingly valuable and versatile resource. However, forestry operations such as harvesting, handling and measuring logs still require substantial human labor in remote environments posing significant safety risks. Progressively automating these tasks has the potential of increasing their efficiency as well as safety, but requires an accurate detection of individual logs as well as live trees and their context. Although initial approaches have been proposed for this challenging application domain, specialized data and algorithms are still too scarce to develop robust solutions. To mitigate this gap, we introduce the TimberVision dataset, consisting of more than 2k annotated RGB images containing a total of 51k trunk components including cut and lateral surfaces, thereby surpassing any existing dataset in this domain in terms of both quantity and detail by a large margin. Based on this data, we conduct a series of ablation experiments for oriented object detection and instance segmentation and evaluate the influence of multiple scene parameters on model performance. We introduce a generic framework to fuse the components detected by our models for both tasks into unified trunk representations. Furthermore, we automatically derive geometric properties and apply multi-object tracking to further enhance robustness. Our detection and tracking approach provides highly descriptive and accurate trunk representations solely from RGB image data, even under challenging environmental conditions. Our solution is suitable for a wide range of application scenarios and can be readily combined with other sensor modalities.