 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpecialized Deep Residual Policy Safe Reinforcement Learning-Based Controller for Complex and Continuous State-Action Spaces
Paper and Code
Oct 15, 2023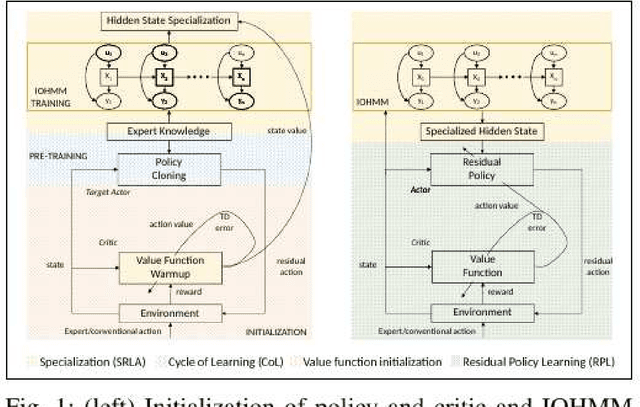
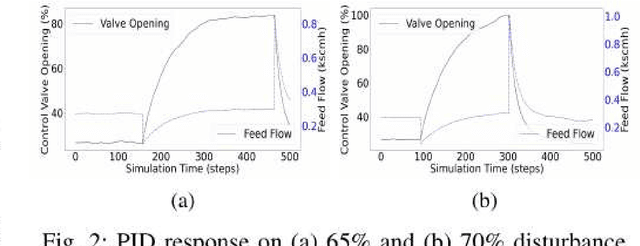
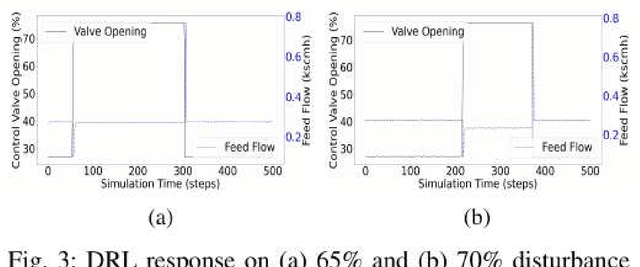
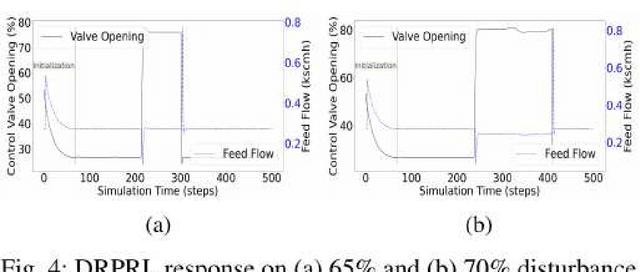
Traditional controllers have limitations as they rely on prior knowledge about the physics of the problem, require modeling of dynamics, and struggle to adapt to abnormal situations. Deep reinforcement learning has the potential to address these problems by learning optimal control policies through exploration in an environment. For safety-critical environments, it is impractical to explore randomly, and replacing conventional controllers with black-box models is also undesirable. Also, it is expensive in continuous state and action spaces, unless the search space is constrained. To address these challenges we propose a specialized deep residual policy safe reinforcement learning with a cycle of learning approach adapted for complex and continuous state-action spaces. Residual policy learning allows learning a hybrid control architecture where the reinforcement learning agent acts in synchronous collaboration with the conventional controller. The cycle of learning initiates the policy through the expert trajectory and guides the exploration around it. Further, the specialization through the input-output hidden Markov model helps to optimize policy that lies within the region of interest (such as abnormality), where the reinforcement learning agent is required and is activated. The proposed solution is validated on the Tennessee Eastman process control.