 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Computational Approach to Visual Metonymy
Jan 25, 2026Images often communicate more than they literally depict: a set of tools can suggest an occupation and a cultural artifact can suggest a tradition. This kind of indirect visual reference, known as visual metonymy, invites viewers to recover a target concept via associated cues rather than explicit depiction. In this work, we present the first computational investigation of visual metonymy. We introduce a novel pipeline grounded in semiotic theory that leverages large language models and text-to-image models to generate metonymic visual representations. Using this framework, we construct ViMET, the first visual metonymy dataset comprising 2,000 multiple-choice questions to evaluate the cognitive reasoning abilities in multimodal language models. Experimental results on our dataset reveal a significant gap between human performance (86.9%) and state-of-the-art vision-language models (65.9%), highlighting limitations in machines' ability to interpret indirect visual references. Our dataset is publicly available at: https://github.com/cincynlp/ViMET.
Evaluating the Impact of Verbal Multiword Expressions on Machine Translation
Aug 24, 2025Verbal multiword expressions (VMWEs) present significant challenges for natural language processing due to their complex and often non-compositional nature. While machine translation models have seen significant improvement with the advent of language models in recent years, accurately translating these complex linguistic structures remains an open problem. In this study, we analyze the impact of three VMWE categories -- verbal idioms, verb-particle constructions, and light verb constructions -- on machine translation quality from English to multiple languages. Using both established multiword expression datasets and sentences containing these language phenomena extracted from machine translation datasets, we evaluate how state-of-the-art translation systems handle these expressions. Our experimental results consistently show that VMWEs negatively affect translation quality. We also propose an LLM-based paraphrasing approach that replaces these expressions with their literal counterparts, demonstrating significant improvement in translation quality for verbal idioms and verb-particle constructions.
Preference Discerning with LLM-Enhanced Generative Retrieval
Dec 11, 2024



Sequential recommendation systems aim to provide personalized recommendations for users based on their interaction history. To achieve this, they often incorporate auxiliary information, such as textual descriptions of items and auxiliary tasks, like predicting user preferences and intent. Despite numerous efforts to enhance these models, they still suffer from limited personalization. To address this issue, we propose a new paradigm, which we term preference discerning. In preference dscerning, we explicitly condition a generative sequential recommendation system on user preferences within its context. To this end, we generate user preferences using Large Language Models (LLMs) based on user reviews and item-specific data. To evaluate preference discerning capabilities of sequential recommendation systems, we introduce a novel benchmark that provides a holistic evaluation across various scenarios, including preference steering and sentiment following. We assess current state-of-the-art methods using our benchmark and show that they struggle to accurately discern user preferences. Therefore, we propose a new method named Mender ($\textbf{M}$ultimodal Prefer$\textbf{en}$ce $\textbf{d}$iscern$\textbf{er}$), which improves upon existing methods and achieves state-of-the-art performance on our benchmark. Our results show that Mender can be effectively guided by human preferences even though they have not been observed during training, paving the way toward more personalized sequential recommendation systems. We will open-source the code and benchmarks upon publication.
Async Learned User Embeddings for Ads Delivery Optimization
Jun 09, 2024



User representation is crucial for recommendation systems as it helps to deliver personalized recommendations by capturing user preferences and behaviors in low-dimensional vectors. High-quality user embeddings can capture subtle preferences, enable precise similarity calculations, and adapt to changing preferences over time to maintain relevance. The effectiveness of recommendation systems depends significantly on the quality of user embedding. We propose to asynchronously learn high fidelity user embeddings for billions of users each day from sequence based multimodal user activities in Meta platforms through a Transformer-like large scale feature learning module. The async learned user representations embeddings (ALURE) are further converted to user similarity graphs through graph learning and then combined with user realtime activities to retrieval highly related ads candidates for the entire ads delivery system. Our method shows significant gains in both offline and online experiments.
Empower Nested Boolean Logic via Self-Supervised Curriculum Learning
Oct 09, 2023Beyond the great cognitive powers showcased by language models, it is crucial to scrutinize whether their reasoning capabilities stem from strong generalization or merely exposure to relevant data. As opposed to constructing increasingly complex logic, this paper probes into the boolean logic, the root capability of a logical reasoner. We find that any pre-trained language models even including large language models only behave like a random selector in the face of multi-nested boolean logic, a task that humans can handle with ease. To empower language models with this fundamental capability, this paper proposes a new self-supervised learning method \textit{Curriculum Logical Reasoning} (\textsc{Clr}), where we augment the training data with nested boolean logic chain step-by-step, and program the training from simpler logical patterns gradually to harder ones. This new training paradigm allows language models to effectively generalize to much harder and longer-hop logic, which can hardly be learned through naive training. Furthermore, we show that boolean logic is a great foundation for improving the subsequent general logical tasks.
Chinese Spelling Correction as Rephrasing Language Model
Aug 17, 2023
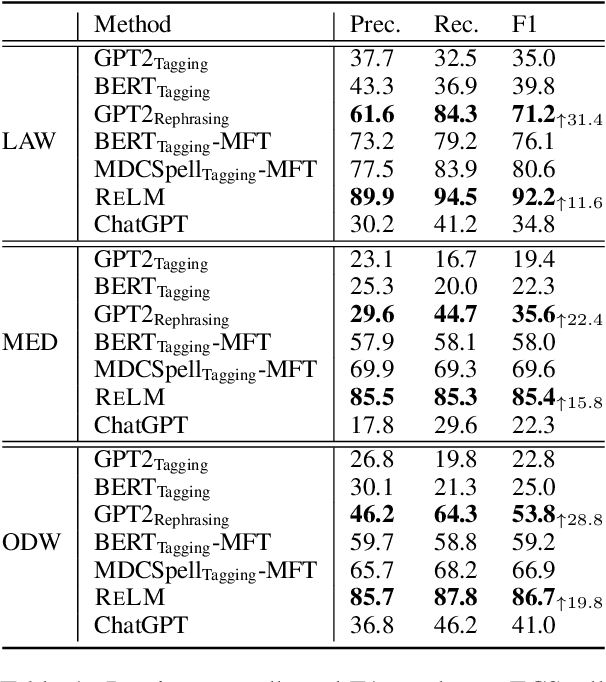

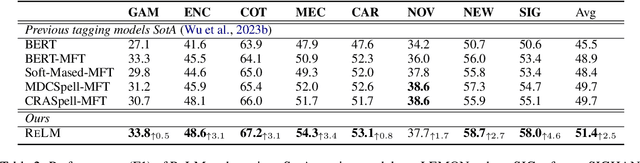
This paper studies Chinese Spelling Correction (CSC), which aims to detect and correct potential spelling errors in a given sentence. Current state-of-the-art methods regard CSC as a sequence tagging task and fine-tune BERT-based models on sentence pairs. However, we note a critical flaw in the process of tagging one character to another, that the correction is excessively conditioned on the error. This is opposite from human mindset, where individuals rephrase the complete sentence based on its semantics, rather than solely on the error patterns memorized before. Such a counter-intuitive learning process results in the bottleneck of generalizability and transferability of machine spelling correction. To address this, we propose $Rephrasing Language Modeling$ (ReLM), where the model is trained to rephrase the entire sentence by infilling additional slots, instead of character-to-character tagging. This novel training paradigm achieves the new state-of-the-art results across fine-tuned and zero-shot CSC benchmarks, outperforming previous counterparts by a large margin. Our method also learns transferable language representation when CSC is jointly trained with other tasks.
Diff-CAPTCHA: An Image-based CAPTCHA with Security Enhanced by Denoising Diffusion Model
Aug 16, 2023To enhance the security of text CAPTCHAs, various methods have been employed, such as adding the interference lines on the text, randomly distorting the characters, and overlapping multiple characters. These methods partly increase the difficulty of automated segmentation and recognition attacks. However, facing the rapid development of the end-to-end breaking algorithms, their security has been greatly weakened. The diffusion model is a novel image generation model that can generate the text images with deep fusion of characters and background images. In this paper, an image-click CAPTCHA scheme called Diff-CAPTCHA is proposed based on denoising diffusion models. The background image and characters of the CAPTCHA are treated as a whole to guide the generation process of a diffusion model, thus weakening the character features available for machine learning, enhancing the diversity of character features in the CAPTCHA, and increasing the difficulty of breaking algorithms. To evaluate the security of Diff-CAPTCHA, this paper develops several attack methods, including end-to-end attacks based on Faster R-CNN and two-stage attacks, and Diff-CAPTCHA is compared with three baseline schemes, including commercial CAPTCHA scheme and security-enhanced CAPTCHA scheme based on style transfer. The experimental results show that diffusion models can effectively enhance CAPTCHA security while maintaining good usability in human testing.
TriFormer: A Multi-modal Transformer Framework For Mild Cognitive Impairment Conversion Prediction
Jul 14, 2023The prediction of mild cognitive impairment (MCI) conversion to Alzheimer's disease (AD) is important for early treatment to prevent or slow the progression of AD. To accurately predict the MCI conversion to stable MCI or progressive MCI, we propose Triformer, a novel transformer-based framework with three specialized transformers to incorporate multi-model data. Triformer uses I) an image transformer to extract multi-view image features from medical scans, II) a clinical transformer to embed and correlate multi-modal clinical data, and III) a modality fusion transformer that produces an accurate prediction based on fusing the outputs from the image and clinical transformers. Triformer is evaluated on the Alzheimer's Disease Neuroimaging Initiative (ANDI)1 and ADNI2 datasets and outperforms previous state-of-the-art single and multi-modal methods.
Kriging Convolutional Networks
Jun 15, 2023

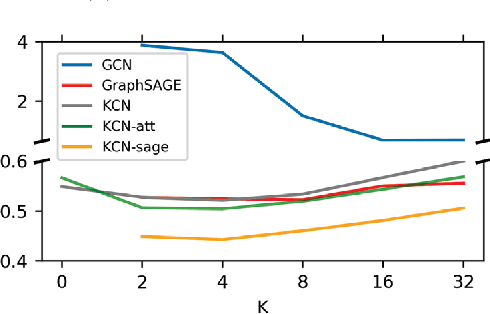

Spatial interpolation is a class of estimation problems where locations with known values are used to estimate values at other locations, with an emphasis on harnessing spatial locality and trends. Traditional Kriging methods have strong Gaussian assumptions, and as a result, often fail to capture complexities within the data. Inspired by the recent progress of graph neural networks, we introduce Kriging Convolutional Networks (KCN), a method of combining the advantages of Graph Convolutional Networks (GCN) and Kriging. Compared to standard GCNs, KCNs make direct use of neighboring observations when generating predictions. KCNs also contain the Kriging method as a specific configuration. We further improve the model's performance by adding attention. Empirically, we show that this model outperforms GCNs and Kriging in several applications. The implementation of KCN using PyTorch is publicized at the GitHub repository: https://github.com/tufts-ml/kcn-torch.
Towards Accurate Subgraph Similarity Computation via Neural Graph Pruning
Oct 19, 2022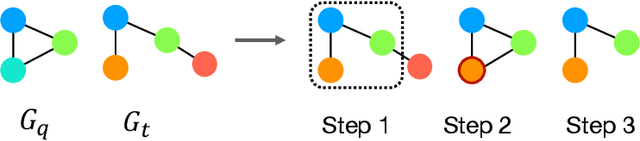
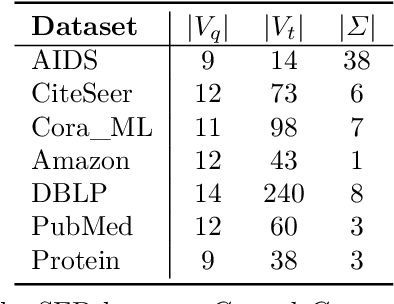
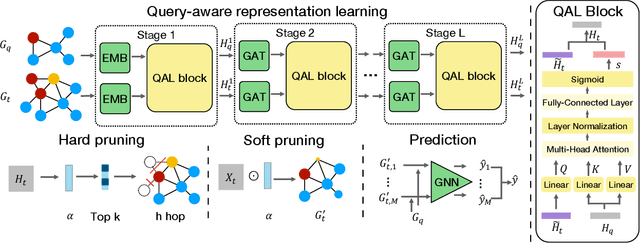
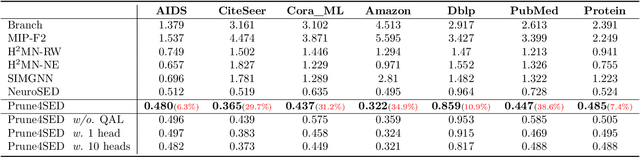
Subgraph similarity search, one of the core problems in graph search, concerns whether a target graph approximately contains a query graph. The problem is recently touched by neural methods. However, current neural methods do not consider pruning the target graph, though pruning is critically important in traditional calculations of subgraph similarities. One obstacle to applying pruning in neural methods is {the discrete property of pruning}. In this work, we convert graph pruning to a problem of node relabeling and then relax it to a differentiable problem. Based on this idea, we further design a novel neural network to approximate a type of subgraph distance: the subgraph edit distance (SED). {In particular, we construct the pruning component using a neural structure, and the entire model can be optimized end-to-end.} In the design of the model, we propose an attention mechanism to leverage the information about the query graph and guide the pruning of the target graph. Moreover, we develop a multi-head pruning strategy such that the model can better explore multiple ways of pruning the target graph. The proposed model establishes new state-of-the-art results across seven benchmark datasets. Extensive analysis of the model indicates that the proposed model can reasonably prune the target graph for SED computation. The implementation of our algorithm is released at our Github repo: https://github.com/tufts-ml/Prune4SED.