 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCascaded Multi-Modal Mixing Transformers for Alzheimer's Disease Classification with Incomplete Data
Oct 01, 2022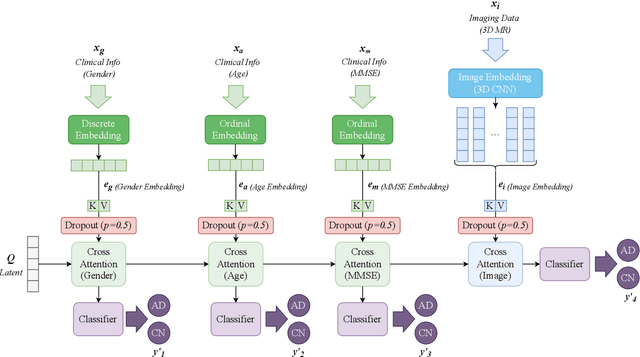
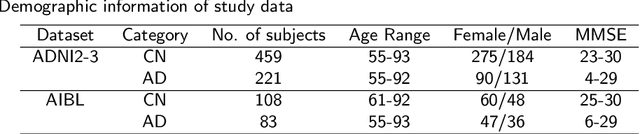
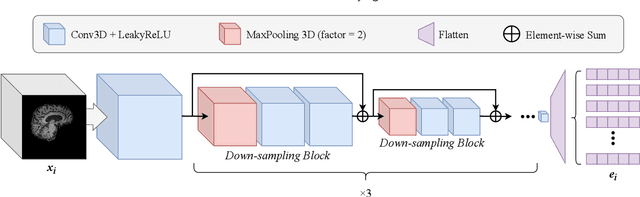
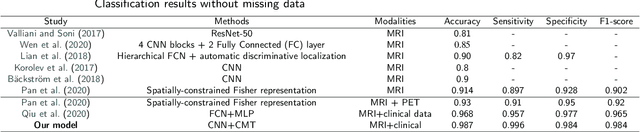
Accurate medical classification requires a large number of multi-modal data, and in many cases, in different formats. Previous studies have shown promising results when using multi-modal data, outperforming single-modality models on when classifying disease such as AD. However, those models are usually not flexible enough to handle missing modalities. Currently, the most common workaround is excluding samples with missing modalities which leads to considerable data under-utilisation. Adding to the fact that labelled medical images are already scarce, the performance of data-driven methods like deep learning is severely hampered. Therefore, a multi-modal method that can gracefully handle missing data in various clinical settings is highly desirable. In this paper, we present the Multi-Modal Mixing Transformer (3MT), a novel Transformer for disease classification based on multi-modal data. In this work, we test it for \ac{AD} or \ac{CN} classification using neuroimaging data, gender, age and MMSE scores. The model uses a novel Cascaded Modality Transformers architecture with cross-attention to incorporate multi-modal information for more informed predictions. Auxiliary outputs and a novel modality dropout mechanism were incorporated to ensure an unprecedented level of modality independence and robustness. The result is a versatile network that enables the mixing of an unlimited number of modalities with different formats and full data utilization. 3MT was first tested on the ADNI dataset and achieved state-of-the-art test accuracy of $0.987\pm0.0006$. To test its generalisability, 3MT was directly applied to the AIBL after training on the ADNI dataset, and achieved a test accuracy of $0.925\pm0.0004$ without fine-tuning. Finally, we show that Grad-CAM visualizations are also possible with our model for explainable results.