 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTCLeaf-Net: a transformer-convolution framework with global-local attention for robust in-field lesion-level plant leaf disease detection
Dec 13, 2025Timely and accurate detection of foliar diseases is vital for safeguarding crop growth and reducing yield losses. Yet, in real-field conditions, cluttered backgrounds, domain shifts, and limited lesion-level datasets hinder robust modeling. To address these challenges, we release Daylily-Leaf, a paired lesion-level dataset comprising 1,746 RGB images and 7,839 lesions captured under both ideal and in-field conditions, and propose TCLeaf-Net, a transformer-convolution hybrid detector optimized for real-field use. TCLeaf-Net is designed to tackle three major challenges. To mitigate interference from complex backgrounds, the transformer-convolution module (TCM) couples global context with locality-preserving convolution to suppress non-leaf regions. To reduce information loss during downsampling, the raw-scale feature recalling and sampling (RSFRS) block combines bilinear resampling and convolution to preserve fine spatial detail. To handle variations in lesion scale and feature shifts, the deformable alignment block with FPN (DFPN) employs offset-based alignment and multi-receptive-field perception to strengthen multi-scale fusion. Experimental results show that on the in-field split of the Daylily-Leaf dataset, TCLeaf-Net improves mAP@50 by 5.4 percentage points over the baseline model, reaching 78.2\%, while reducing computation by 7.5 GFLOPs and GPU memory usage by 8.7\%. Moreover, the model outperforms recent YOLO and RT-DETR series in both precision and recall, and demonstrates strong performance on the PlantDoc, Tomato-Leaf, and Rice-Leaf datasets, validating its robustness and generalizability to other plant disease detection scenarios.
AnyEnhance: A Unified Generative Model with Prompt-Guidance and Self-Critic for Voice Enhancement
Jan 26, 2025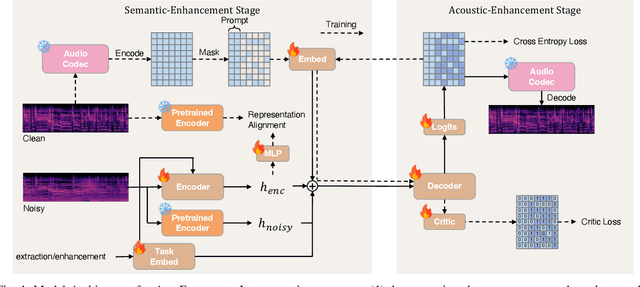
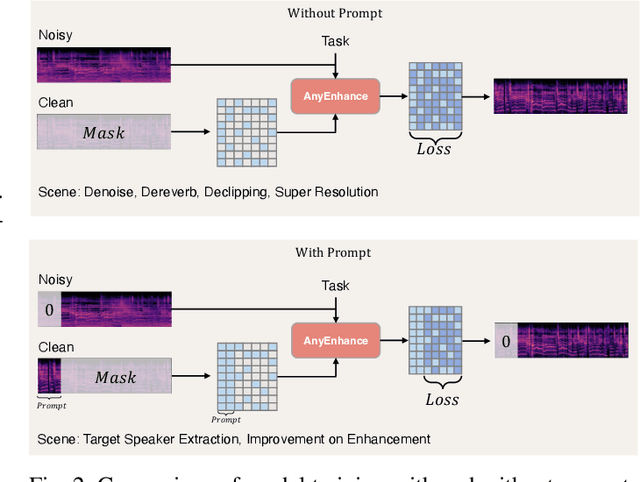
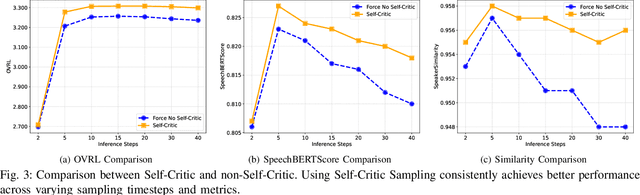

We introduce AnyEnhance, a unified generative model for voice enhancement that processes both speech and singing voices. Based on a masked generative model, AnyEnhance is capable of handling both speech and singing voices, supporting a wide range of enhancement tasks including denoising, dereverberation, declipping, super-resolution, and target speaker extraction, all simultaneously and without fine-tuning. AnyEnhance introduces a prompt-guidance mechanism for in-context learning, which allows the model to natively accept a reference speaker's timbre. In this way, it could boost enhancement performance when a reference audio is available and enable the target speaker extraction task without altering the underlying architecture. Moreover, we also introduce a self-critic mechanism into the generative process for masked generative models, yielding higher-quality outputs through iterative self-assessment and refinement. Extensive experiments on various enhancement tasks demonstrate AnyEnhance outperforms existing methods in terms of both objective metrics and subjective listening tests. Demo audios are publicly available at https://amphionspace.github.io/anyenhance/.
Embracing Events and Frames with Hierarchical Feature Refinement Network for Object Detection
Jul 17, 2024



In frame-based vision, object detection faces substantial performance degradation under challenging conditions due to the limited sensing capability of conventional cameras. Event cameras output sparse and asynchronous events, providing a potential solution to solve these problems. However, effectively fusing two heterogeneous modalities remains an open issue. In this work, we propose a novel hierarchical feature refinement network for event-frame fusion. The core concept is the design of the coarse-to-fine fusion module, denoted as the cross-modality adaptive feature refinement (CAFR) module. In the initial phase, the bidirectional cross-modality interaction (BCI) part facilitates information bridging from two distinct sources. Subsequently, the features are further refined by aligning the channel-level mean and variance in the two-fold adaptive feature refinement (TAFR) part. We conducted extensive experiments on two benchmarks: the low-resolution PKU-DDD17-Car dataset and the high-resolution DSEC dataset. Experimental results show that our method surpasses the state-of-the-art by an impressive margin of $\textbf{8.0}\%$ on the DSEC dataset. Besides, our method exhibits significantly better robustness (\textbf{69.5}\% versus \textbf{38.7}\%) when introducing 15 different corruption types to the frame images. The code can be found at the link (https://github.com/HuCaoFighting/FRN).
Async Learned User Embeddings for Ads Delivery Optimization
Jun 09, 2024



User representation is crucial for recommendation systems as it helps to deliver personalized recommendations by capturing user preferences and behaviors in low-dimensional vectors. High-quality user embeddings can capture subtle preferences, enable precise similarity calculations, and adapt to changing preferences over time to maintain relevance. The effectiveness of recommendation systems depends significantly on the quality of user embedding. We propose to asynchronously learn high fidelity user embeddings for billions of users each day from sequence based multimodal user activities in Meta platforms through a Transformer-like large scale feature learning module. The async learned user representations embeddings (ALURE) are further converted to user similarity graphs through graph learning and then combined with user realtime activities to retrieval highly related ads candidates for the entire ads delivery system. Our method shows significant gains in both offline and online experiments.
Enhancing LLM Factual Accuracy with RAG to Counter Hallucinations: A Case Study on Domain-Specific Queries in Private Knowledge-Bases
Mar 15, 2024
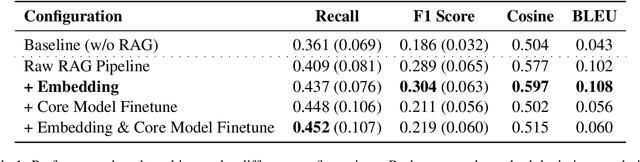


We proposed an end-to-end system design towards utilizing Retrieval Augmented Generation (RAG) to improve the factual accuracy of Large Language Models (LLMs) for domain-specific and time-sensitive queries related to private knowledge-bases. Our system integrates RAG pipeline with upstream datasets processing and downstream performance evaluation. Addressing the challenge of LLM hallucinations, we finetune models with a curated dataset which originates from CMU's extensive resources and annotated with the teacher model. Our experiments demonstrate the system's effectiveness in generating more accurate answers to domain-specific and time-sensitive inquiries. The results also revealed the limitations of fine-tuning LLMs with small-scale and skewed datasets. This research highlights the potential of RAG systems in augmenting LLMs with external datasets for improved performance in knowledge-intensive tasks. Our code and models are available on Github.
Pretraining Strategy for Neural Potentials
Feb 24, 2024We propose a mask pretraining method for Graph Neural Networks (GNNs) to improve their performance on fitting potential energy surfaces, particularly in water systems. GNNs are pretrained by recovering spatial information related to masked-out atoms from molecules, then transferred and finetuned on atomic forcefields. Through such pretraining, GNNs learn meaningful prior about structural and underlying physical information of molecule systems that are useful for downstream tasks. From comprehensive experiments and ablation studies, we show that the proposed method improves the accuracy and convergence speed compared to GNNs trained from scratch or using other pretraining techniques such as denoising. On the other hand, our pretraining method is suitable for both energy-centric and force-centric GNNs. This approach showcases its potential to enhance the performance and data efficiency of GNNs in fitting molecular force fields.
Line Graph Contrastive Learning for Link Prediction
Oct 25, 2022



Link prediction task aims to predict the connection of two nodes in the network. Existing works mainly predict links by node pairs similarity measurements. However, if the local structure doesn't meet such measurement assumption, the algorithms' performance will deteriorate rapidly. To overcome these limitations, we propose a Line Graph Contrastive Learning (LGCL) method to obtain multiview information. Our framework obtains a subgraph view by h-hop subgraph sampling with target node pairs as the center. After transforming the sampled subgraph into a line graph, the edge embedding information is directly accessible, and the link prediction task is converted into a node classification task. Then, different graph convolution operators learn representations from double perspectives. Finally, contrastive learning is adopted to balance the subgraph representations of these perspectives via maximizing mutual information. With experiments on six public datasets, LGCL outperforms current benchmarks on link prediction tasks and shows better generalization performance and robustness.
FB-MSTCN: A Full-Band Single-Channel Speech Enhancement Method Based on Multi-Scale Temporal Convolutional Network
Mar 15, 2022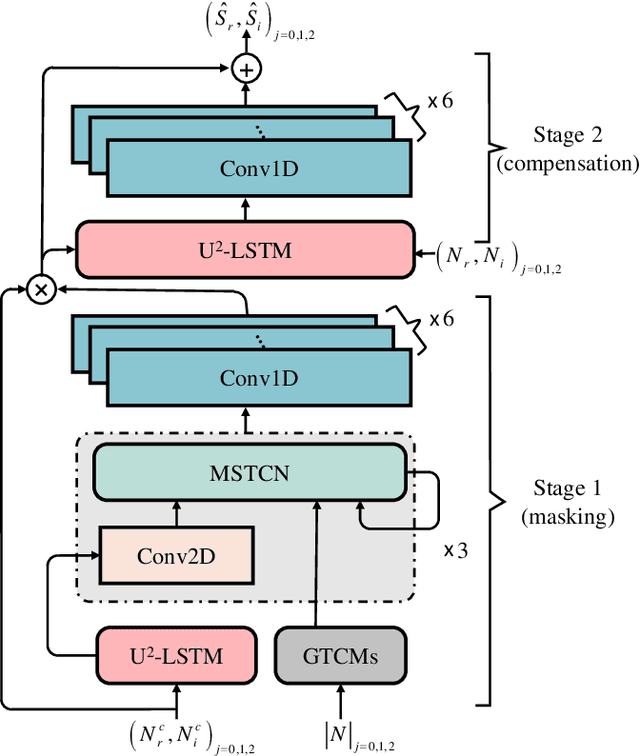
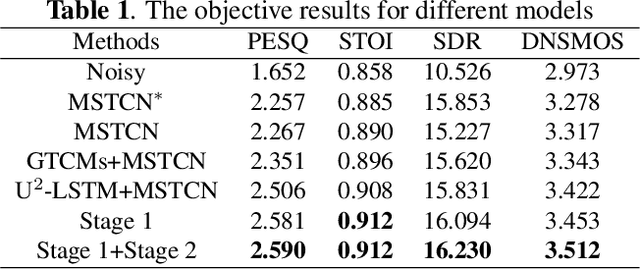
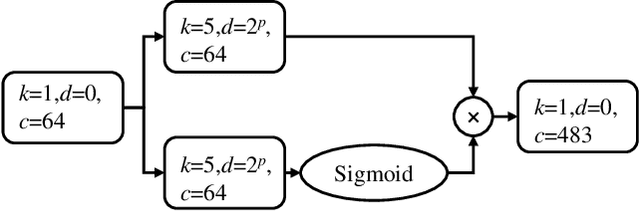
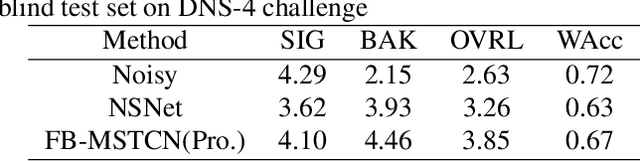
In recent years, deep learning-based approaches have significantly improved the performance of single-channel speech enhancement. However, due to the limitation of training data and computational complexity, real-time enhancement of full-band (48 kHz) speech signals is still very challenging. Because of the low energy of spectral information in the high-frequency part, it is more difficult to directly model and enhance the full-band spectrum using neural networks. To solve this problem, this paper proposes a two-stage real-time speech enhancement model with extraction-interpolation mechanism for a full-band signal. The 48 kHz full-band time-domain signal is divided into three sub-channels by extracting, and a two-stage processing scheme of `masking + compensation' is proposed to enhance the signal in the complex domain. After the two-stage enhancement, the enhanced full-band speech signal is restored by interval interpolation. In the subjective listening and word accuracy test, our proposed model achieves superior performance and outperforms the baseline model overall by 0.59 MOS and 4.0% WAcc for the non-personalized speech denoising task.
Incorporating Multi-Target in Multi-Stage Speech Enhancement Model for Better Generalization
Jul 09, 2021
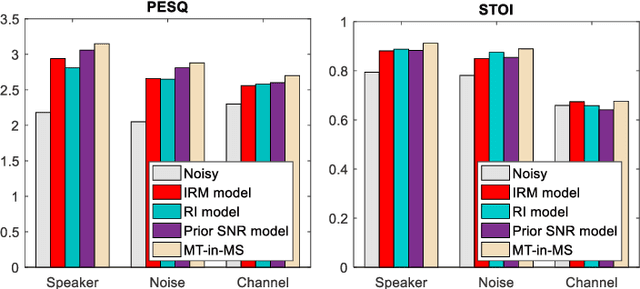


Recent single-channel speech enhancement methods based on deep neural networks (DNNs) have achieved remarkable results, but there are still generalization problems in real scenes. Like other data-driven methods, DNN-based speech enhancement models produce significant performance degradation on untrained data. In this study, we make full use of the contribution of multi-target joint learning to the model generalization capability, and propose a lightweight and low-computing dilated convolutional network (DCN) model for a more robust speech denoising task. Our goal is to integrate the masking target, the mapping target, and the parameters of the traditional speech enhancement estimator into a DCN model to maximize their complementary advantages. To do this, we build a multi-stage learning framework to deal with multiple targets in stages to achieve their joint learning, namely `MT-in-MS'. Our experimental results show that compared with the state-of-the-art time domain and time-frequency domain models, this proposed low-cost DCN model can achieve better generalization performance in speaker, noise, and channel mismatch cases.
Deep Interaction between Masking and Mapping Targets for Single-Channel Speech Enhancement
Jun 09, 2021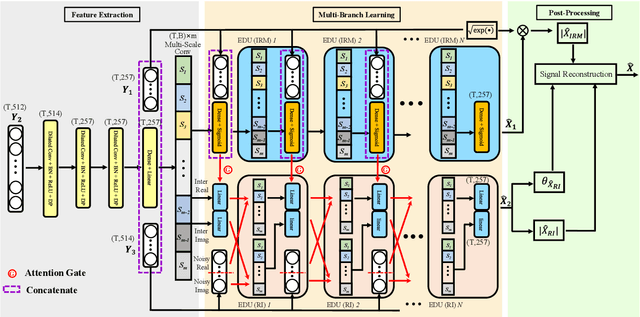
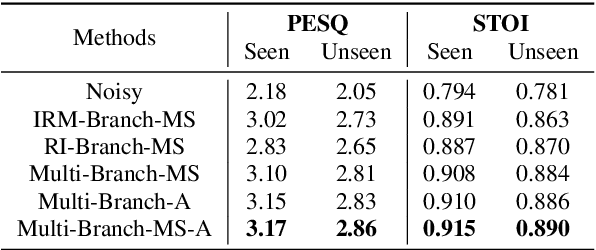
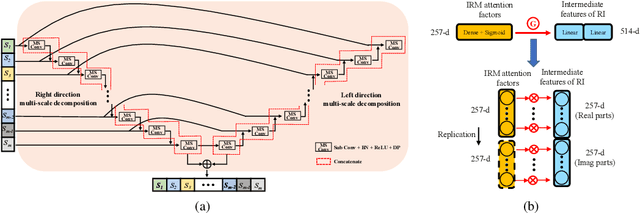
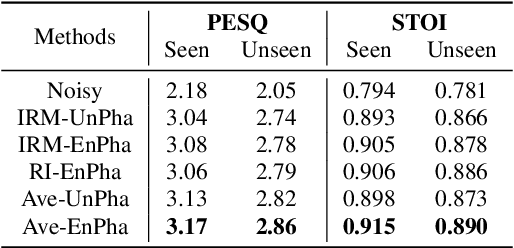
The most recent deep neural network (DNN) models exhibit impressive denoising performance in the time-frequency (T-F) magnitude domain. However, the phase is also a critical component of the speech signal that is easily overlooked. In this paper, we propose a multi-branch dilated convolutional network (DCN) to simultaneously enhance the magnitude and phase of noisy speech. A causal and robust monaural speech enhancement system is achieved based on the multi-objective learning framework of the complex spectrum and the ideal ratio mask (IRM) targets. In the process of joint learning, the intermediate estimation of IRM targets is used as a way of generating feature attention factors to realize the information interaction between the two targets. Moreover, the proposed multi-scale dilated convolution enables the DCN model to have a more efficient temporal modeling capability. Experimental results show that compared with other state-of-the-art models, this model achieves better speech quality and intelligibility with less computation.