 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFB-MSTCN: A Full-Band Single-Channel Speech Enhancement Method Based on Multi-Scale Temporal Convolutional Network
Paper and Code
Mar 15, 2022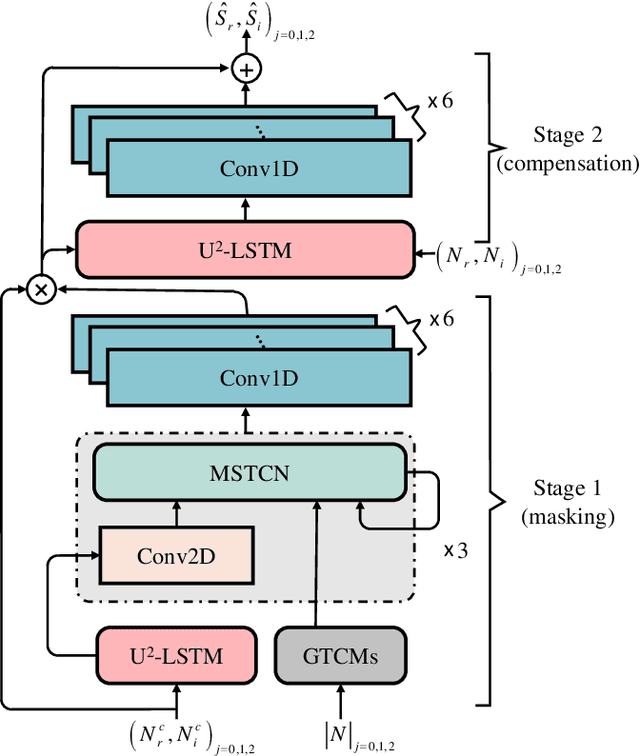
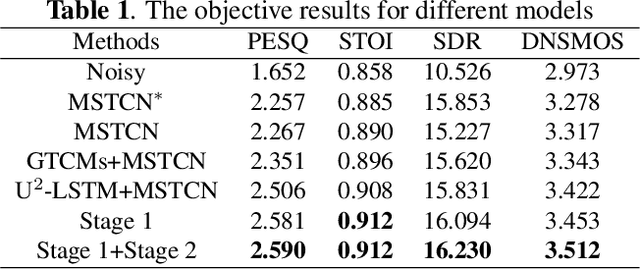
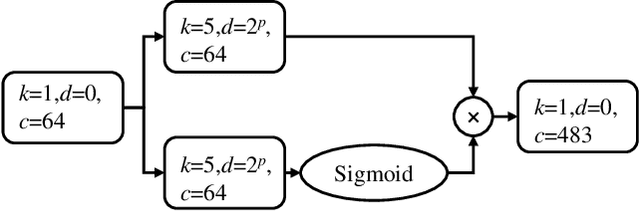
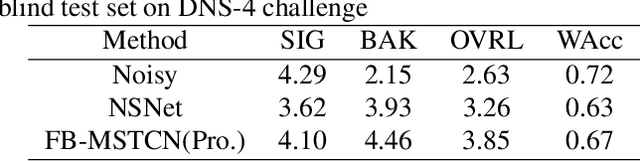
In recent years, deep learning-based approaches have significantly improved the performance of single-channel speech enhancement. However, due to the limitation of training data and computational complexity, real-time enhancement of full-band (48 kHz) speech signals is still very challenging. Because of the low energy of spectral information in the high-frequency part, it is more difficult to directly model and enhance the full-band spectrum using neural networks. To solve this problem, this paper proposes a two-stage real-time speech enhancement model with extraction-interpolation mechanism for a full-band signal. The 48 kHz full-band time-domain signal is divided into three sub-channels by extracting, and a two-stage processing scheme of `masking + compensation' is proposed to enhance the signal in the complex domain. After the two-stage enhancement, the enhanced full-band speech signal is restored by interval interpolation. In the subjective listening and word accuracy test, our proposed model achieves superior performance and outperforms the baseline model overall by 0.59 MOS and 4.0% WAcc for the non-personalized speech denoising task.