 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating LLM Hallucinations with Knowledge Graphs: A Case Study
Apr 16, 2025High-stakes domains like cyber operations need responsible and trustworthy AI methods. While large language models (LLMs) are becoming increasingly popular in these domains, they still suffer from hallucinations. This research paper provides learning outcomes from a case study with LinkQ, an open-source natural language interface that was developed to combat hallucinations by forcing an LLM to query a knowledge graph (KG) for ground-truth data during question-answering (QA). We conduct a quantitative evaluation of LinkQ using a well-known KGQA dataset, showing that the system outperforms GPT-4 but still struggles with certain question categories - suggesting that alternative query construction strategies will need to be investigated in future LLM querying systems. We discuss a qualitative study of LinkQ with two domain experts using a real-world cybersecurity KG, outlining these experts' feedback, suggestions, perceived limitations, and future opportunities for systems like LinkQ.
LinkQ: An LLM-Assisted Visual Interface for Knowledge Graph Question-Answering
Jun 07, 2024We present LinkQ, a system that leverages a large language model (LLM) to facilitate knowledge graph (KG) query construction through natural language question-answering. Traditional approaches often require detailed knowledge of complex graph querying languages, limiting the ability for users -- even experts -- to acquire valuable insights from KG data. LinkQ simplifies this process by first interpreting a user's question, then converting it into a well-formed KG query. By using the LLM to construct a query instead of directly answering the user's question, LinkQ guards against the LLM hallucinating or generating false, erroneous information. By integrating an LLM into LinkQ, users are able to conduct both exploratory and confirmatory data analysis, with the LLM helping to iteratively refine open-ended questions into precise ones. To demonstrate the efficacy of LinkQ, we conducted a qualitative study with five KG practitioners and distill their feedback. Our results indicate that practitioners find LinkQ effective for KG question-answering, and desire future LLM-assisted systems for the exploratory analysis of graph databases.
Kriging Convolutional Networks
Jun 15, 2023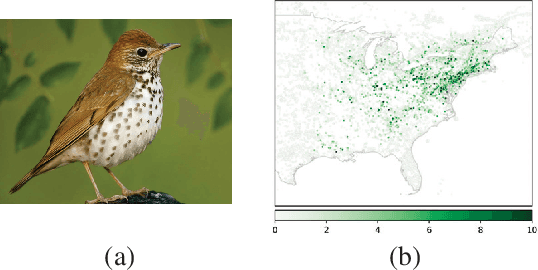

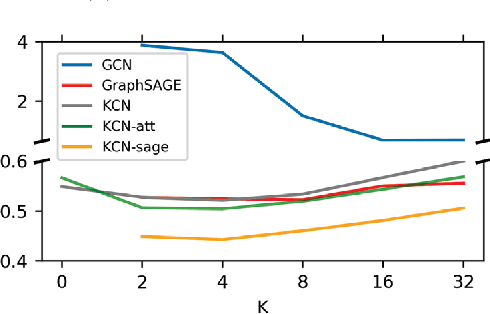

Spatial interpolation is a class of estimation problems where locations with known values are used to estimate values at other locations, with an emphasis on harnessing spatial locality and trends. Traditional Kriging methods have strong Gaussian assumptions, and as a result, often fail to capture complexities within the data. Inspired by the recent progress of graph neural networks, we introduce Kriging Convolutional Networks (KCN), a method of combining the advantages of Graph Convolutional Networks (GCN) and Kriging. Compared to standard GCNs, KCNs make direct use of neighboring observations when generating predictions. KCNs also contain the Kriging method as a specific configuration. We further improve the model's performance by adding attention. Empirically, we show that this model outperforms GCNs and Kriging in several applications. The implementation of KCN using PyTorch is publicized at the GitHub repository: https://github.com/tufts-ml/kcn-torch.
Characterizing the Users, Challenges, and Visualization Needs of Knowledge Graphs in Practice
Apr 06, 2023



This study presents insights from interviews with nineteen Knowledge Graph (KG) practitioners who work in both enterprise and academic settings on a wide variety of use cases. Through this study, we identify critical challenges experienced by KG practitioners when creating, exploring, and analyzing KGs that could be alleviated through visualization design. Our findings reveal three major personas among KG practitioners - KG Builders, Analysts, and Consumers - each of whom have their own distinct expertise and needs. We discover that KG Builders would benefit from schema enforcers, while KG Analysts need customizable query builders that provide interim query results. For KG Consumers, we identify a lack of efficacy for node-link diagrams, and the need for tailored domain-specific visualizations to promote KG adoption and comprehension. Lastly, we find that implementing KGs effectively in practice requires both technical and social solutions that are not addressed with current tools, technologies, and collaborative workflows. From the analysis of our interviews, we distill several visualization research directions to improve KG usability, including knowledge cards that balance digestibility and discoverability, timeline views to track temporal changes, interfaces that support organic discovery, and semantic explanations for AI and machine learning predictions.
Attention is All They Need: Exploring the Media Archaeology of the Computer Vision Research Paper
Sep 22, 2022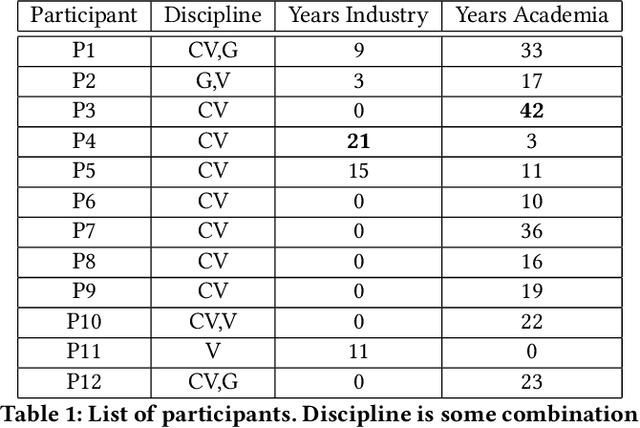

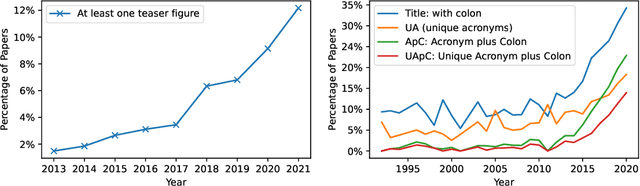
The success of deep learning has led to the rapid transformation and growth of many areas of computer science, including computer vision. In this work, we examine the effects of this growth through the computer vision research paper itself by analyzing the figures and tables in research papers from a media archaeology perspective. We ground our investigation both through interviews with veteran researchers spanning computer vision, graphics and visualization, and computational analysis of a decade of vision conference papers. Our analysis focuses on elements with roles in advertising, measuring and disseminating an increasingly commodified "contribution." We argue that each of these elements has shaped and been shaped by the climate of computer vision, ultimately contributing to that commodification. Through this work, we seek to motivate future discussion surrounding the design of the research paper and the broader socio-technical publishing system.
Visualization Guidelines for Model Performance Communication Between Data Scientists and Subject Matter Experts
May 11, 2022
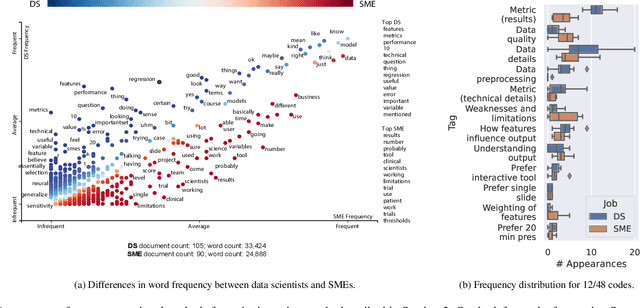


Presenting the complexities of a model's performance is a communication bottleneck that threatens collaborations between data scientists and subject matter experts. Accuracy and error metrics alone fail to tell the whole story of a model - its risks, strengths, and limitations - making it difficult for subject matter experts to feel confident in deciding to use a model. As a result, models may fail in unexpected ways if their weaknesses are not clearly understood. Alternatively, models may go unused, as subject matter experts disregard poorly presented models in favor of familiar, yet arguably substandard methods. In this paper, we propose effective use of visualization as a medium for communication between data scientists and subject matter experts. Our research addresses the gap between common practices in model performance communication and the understanding of subject matter experts and decision makers. We derive a set of communication guidelines and recommended visualizations for communicating model performance based on interviews of both data scientists and subject matter experts at the same organization. We conduct a follow-up study with subject matter experts to evaluate the efficacy of our guidelines in presentations of model performance with and without our recommendations. We find that our proposed guidelines made subject matter experts more aware of the tradeoffs of the presented model. Participants realized that current communication methods left them without a robust understanding of the model's performance, potentially giving them misplaced confidence in the use of the model.
UnProjection: Leveraging Inverse-Projections for Visual Analytics of High-Dimensional Data
Nov 02, 2021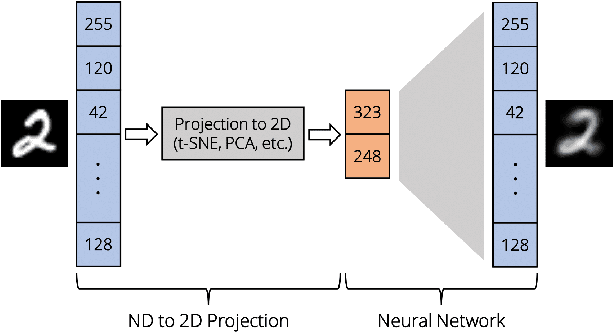
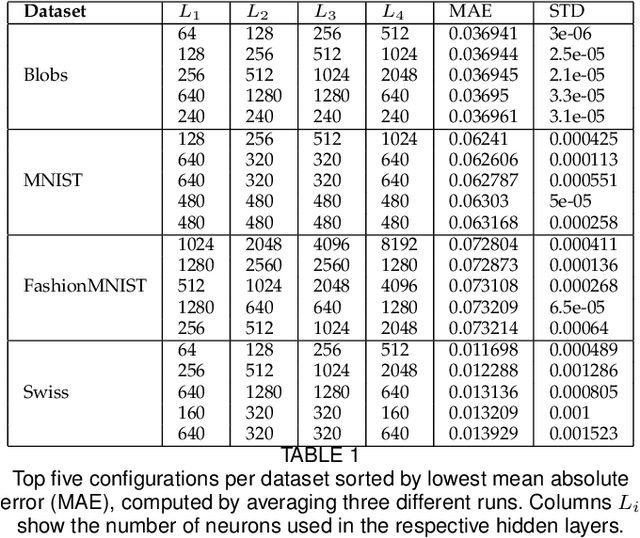

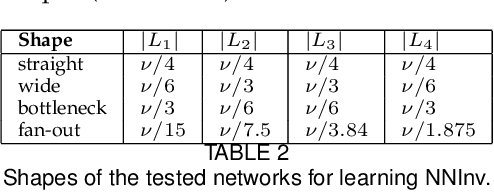
Projection techniques are often used to visualize high-dimensional data, allowing users to better understand the overall structure of multi-dimensional spaces on a 2D screen. Although many such methods exist, comparably little work has been done on generalizable methods of inverse-projection -- the process of mapping the projected points, or more generally, the projection space back to the original high-dimensional space. In this paper we present NNInv, a deep learning technique with the ability to approximate the inverse of any projection or mapping. NNInv learns to reconstruct high-dimensional data from any arbitrary point on a 2D projection space, giving users the ability to interact with the learned high-dimensional representation in a visual analytics system. We provide an analysis of the parameter space of NNInv, and offer guidance in selecting these parameters. We extend validation of the effectiveness of NNInv through a series of quantitative and qualitative analyses. We then demonstrate the method's utility by applying it to three visualization tasks: interactive instance interpolation, classifier agreement, and gradient visualization.
HyperNP: Interactive Visual Exploration of Multidimensional Projection Hyperparameters
Jun 25, 2021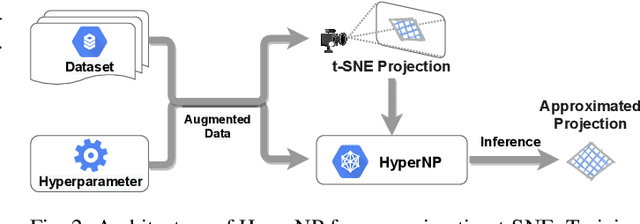



Projection algorithms such as t-SNE or UMAP are useful for the visualization of high dimensional data, but depend on hyperparameters which must be tuned carefully. Unfortunately, iteratively recomputing projections to find the optimal hyperparameter value is computationally intensive and unintuitive due to the stochastic nature of these methods. In this paper we propose HyperNP, a scalable method that allows for real-time interactive hyperparameter exploration of projection methods by training neural network approximations. HyperNP can be trained on a fraction of the total data instances and hyperparameter configurations and can compute projections for new data and hyperparameters at interactive speeds. HyperNP is compact in size and fast to compute, thus allowing it to be embedded in lightweight visualization systems such as web browsers. We evaluate the performance of the HyperNP across three datasets in terms of performance and speed. The results suggest that HyperNP is accurate, scalable, interactive, and appropriate for use in real-world settings.