 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnProjection: Leveraging Inverse-Projections for Visual Analytics of High-Dimensional Data
Nov 02, 2021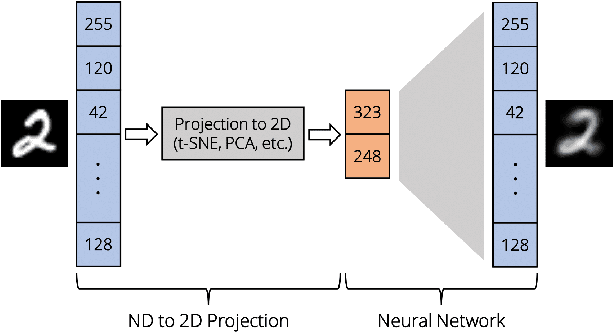
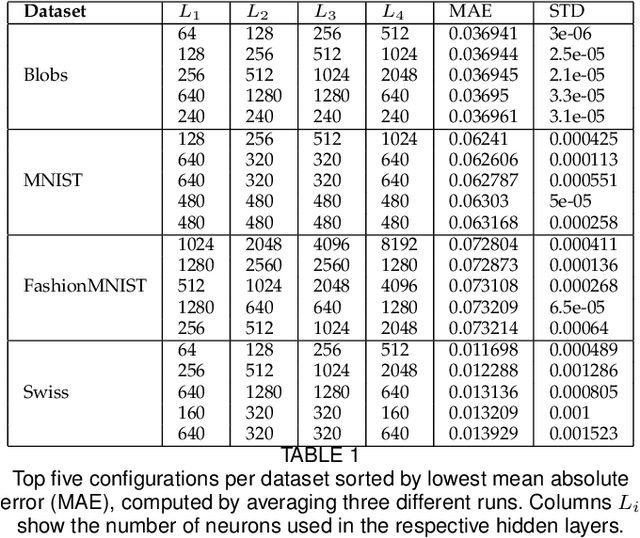

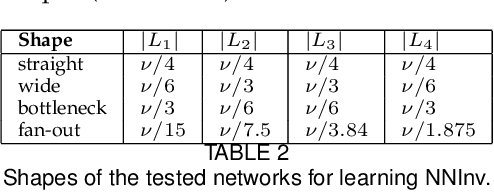
Projection techniques are often used to visualize high-dimensional data, allowing users to better understand the overall structure of multi-dimensional spaces on a 2D screen. Although many such methods exist, comparably little work has been done on generalizable methods of inverse-projection -- the process of mapping the projected points, or more generally, the projection space back to the original high-dimensional space. In this paper we present NNInv, a deep learning technique with the ability to approximate the inverse of any projection or mapping. NNInv learns to reconstruct high-dimensional data from any arbitrary point on a 2D projection space, giving users the ability to interact with the learned high-dimensional representation in a visual analytics system. We provide an analysis of the parameter space of NNInv, and offer guidance in selecting these parameters. We extend validation of the effectiveness of NNInv through a series of quantitative and qualitative analyses. We then demonstrate the method's utility by applying it to three visualization tasks: interactive instance interpolation, classifier agreement, and gradient visualization.
Iterative Pseudo-Labeling with Deep Feature Annotation and Confidence-Based Sampling
Sep 06, 2021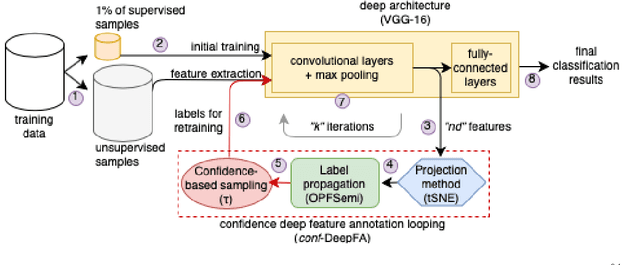

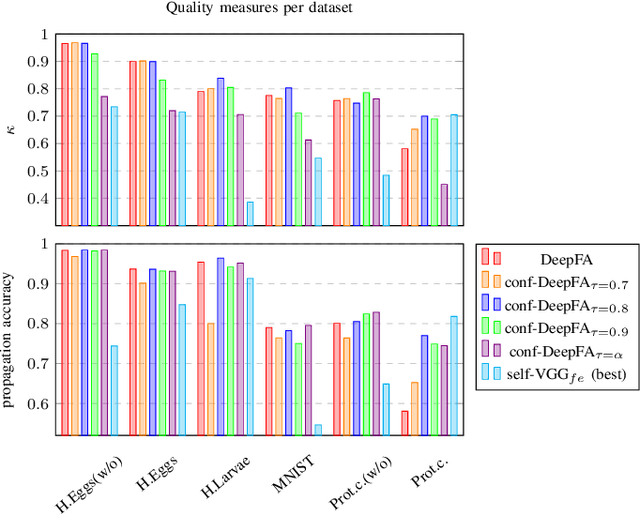
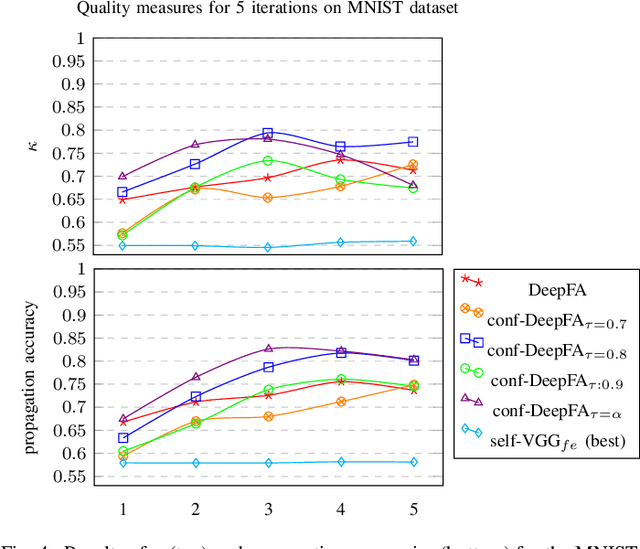
Training deep neural networks is challenging when large and annotated datasets are unavailable. Extensive manual annotation of data samples is time-consuming, expensive, and error-prone, notably when it needs to be done by experts. To address this issue, increased attention has been devoted to techniques that propagate uncertain labels (also called pseudo labels) to large amounts of unsupervised samples and use them for training the model. However, these techniques still need hundreds of supervised samples per class in the training set and a validation set with extra supervised samples to tune the model. We improve a recent iterative pseudo-labeling technique, Deep Feature Annotation (DeepFA), by selecting the most confident unsupervised samples to iteratively train a deep neural network. Our confidence-based sampling strategy relies on only dozens of annotated training samples per class with no validation set, considerably reducing user effort in data annotation. We first ascertain the best configuration for the baseline -- a self-trained deep neural network -- and then evaluate our confidence DeepFA for different confidence thresholds. Experiments on six datasets show that DeepFA already outperforms the self-trained baseline, but confidence DeepFA can considerably outperform the original DeepFA and the baseline.