 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIterative Pseudo-Labeling with Deep Feature Annotation and Confidence-Based Sampling
Sep 06, 2021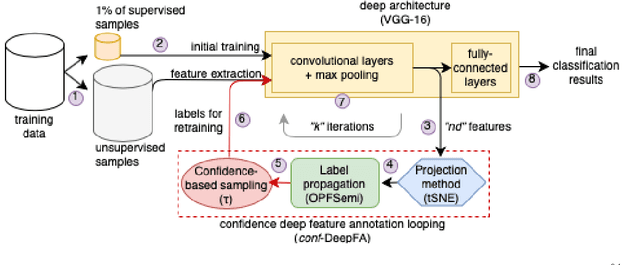

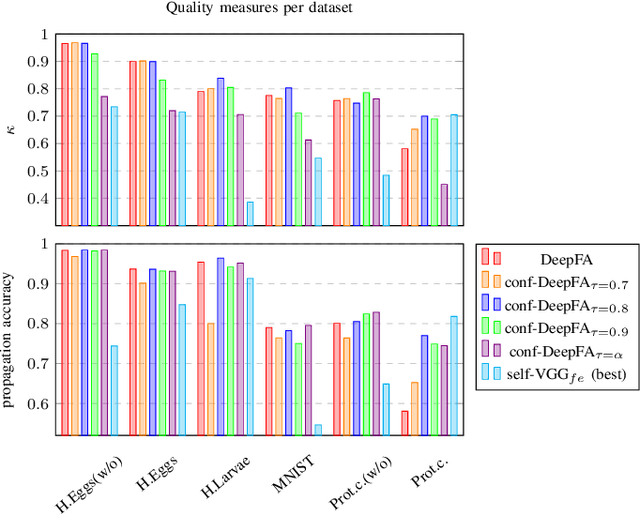
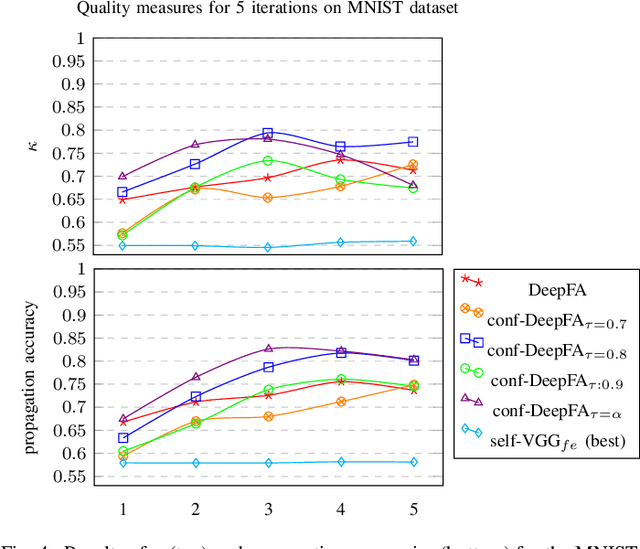
Training deep neural networks is challenging when large and annotated datasets are unavailable. Extensive manual annotation of data samples is time-consuming, expensive, and error-prone, notably when it needs to be done by experts. To address this issue, increased attention has been devoted to techniques that propagate uncertain labels (also called pseudo labels) to large amounts of unsupervised samples and use them for training the model. However, these techniques still need hundreds of supervised samples per class in the training set and a validation set with extra supervised samples to tune the model. We improve a recent iterative pseudo-labeling technique, Deep Feature Annotation (DeepFA), by selecting the most confident unsupervised samples to iteratively train a deep neural network. Our confidence-based sampling strategy relies on only dozens of annotated training samples per class with no validation set, considerably reducing user effort in data annotation. We first ascertain the best configuration for the baseline -- a self-trained deep neural network -- and then evaluate our confidence DeepFA for different confidence thresholds. Experiments on six datasets show that DeepFA already outperforms the self-trained baseline, but confidence DeepFA can considerably outperform the original DeepFA and the baseline.