 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Study on Clustering Pretrained Embeddings: Is Deep Strictly Better?
Nov 09, 2022Recent research in clustering face embeddings has found that unsupervised, shallow, heuristic-based methods -- including $k$-means and hierarchical agglomerative clustering -- underperform supervised, deep, inductive methods. While the reported improvements are indeed impressive, experiments are mostly limited to face datasets, where the clustered embeddings are highly discriminative or well-separated by class (Recall@1 above 90% and often nearing ceiling), and the experimental methodology seemingly favors the deep methods. We conduct a large-scale empirical study of 17 clustering methods across three datasets and obtain several robust findings. Notably, deep methods are surprisingly fragile for embeddings with more uncertainty, where they match or even perform worse than shallow, heuristic-based methods. When embeddings are highly discriminative, deep methods do outperform the baselines, consistent with past results, but the margin between methods is much smaller than previously reported. We believe our benchmarks broaden the scope of supervised clustering methods beyond the face domain and can serve as a foundation on which these methods could be improved. To enable reproducibility, we include all necessary details in the appendices, and plan to release the code.
Online Unsupervised Learning of Visual Representations and Categories
Sep 13, 2021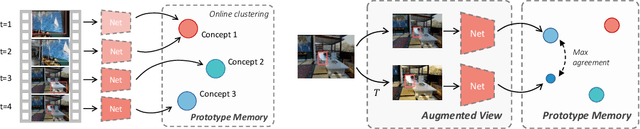
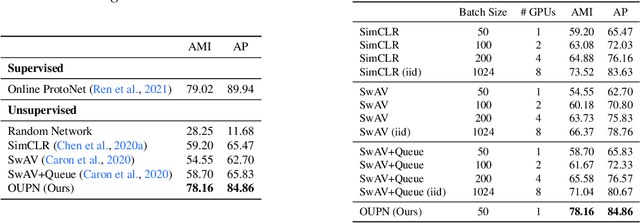


Real world learning scenarios involve a nonstationary distribution of classes with sequential dependencies among the samples, in contrast to the standard machine learning formulation of drawing samples independently from a fixed, typically uniform distribution. Furthermore, real world interactions demand learning on-the-fly from few or no class labels. In this work, we propose an unsupervised model that simultaneously performs online visual representation learning and few-shot learning of new categories without relying on any class labels. Our model is a prototype-based memory network with a control component that determines when to form a new class prototype. We formulate it as an online Gaussian mixture model, where components are created online with only a single new example, and assignments do not have to be balanced, which permits an approximation to natural imbalanced distributions from uncurated raw data. Learning includes a contrastive loss that encourages different views of the same image to be assigned to the same prototype. The result is a mechanism that forms categorical representations of objects in nonstationary environments. Experiments show that our method can learn from an online stream of visual input data and is significantly better at category recognition compared to state-of-the-art self-supervised learning methods.
von Mises-Fisher Loss: An Exploration of Embedding Geometries for Supervised Learning
Mar 31, 2021
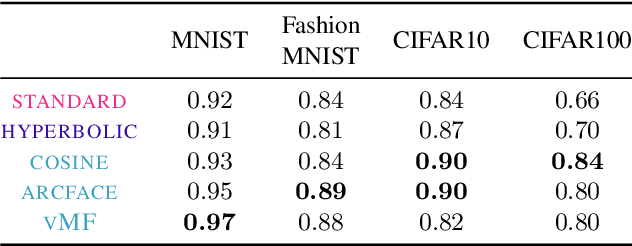
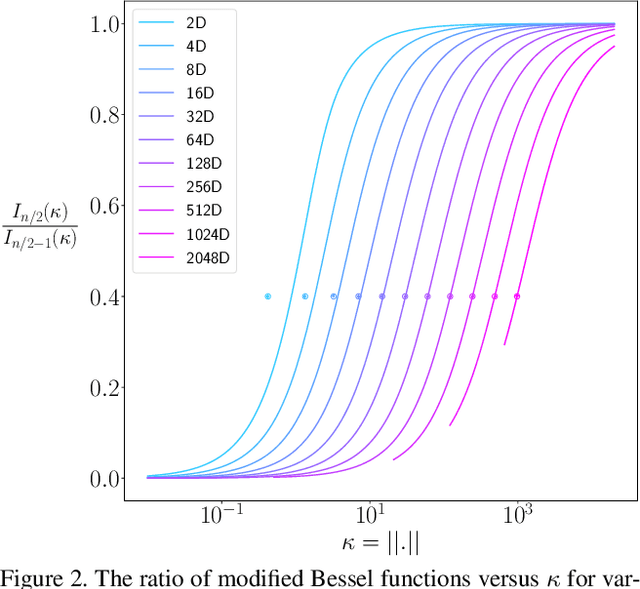
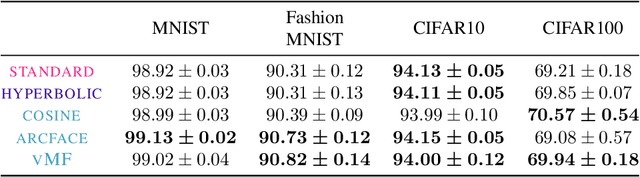
Recent work has argued that classification losses utilizing softmax cross-entropy are superior not only for fixed-set classification tasks, but also by outperforming losses developed specifically for open-set tasks including few-shot learning and retrieval. Softmax classifiers have been studied using different embedding geometries -- Euclidean, hyperbolic, and spherical -- and claims have been made about the superiority of one or another, but they have not been systematically compared with careful controls. We conduct an empirical investigation of embedding geometry on softmax losses for a variety of fixed-set classification and image retrieval tasks. An interesting property observed for the spherical losses lead us to propose a probabilistic classifier based on the von Mises-Fisher distribution, and we show that it is competitive with state-of-the-art methods while producing improved out-of-the-box calibration. We provide guidance regarding the trade-offs between losses and how to choose among them.
Unifying Few- and Zero-Shot Egocentric Action Recognition
May 27, 2020
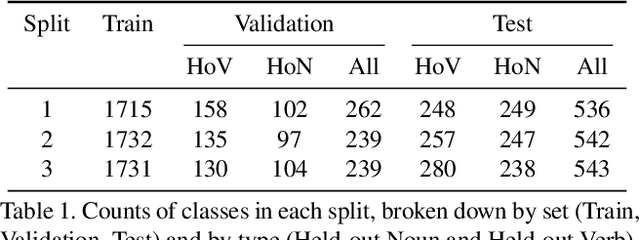
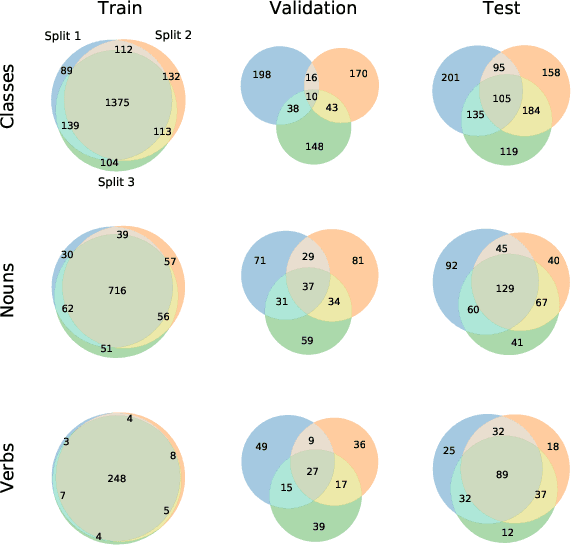
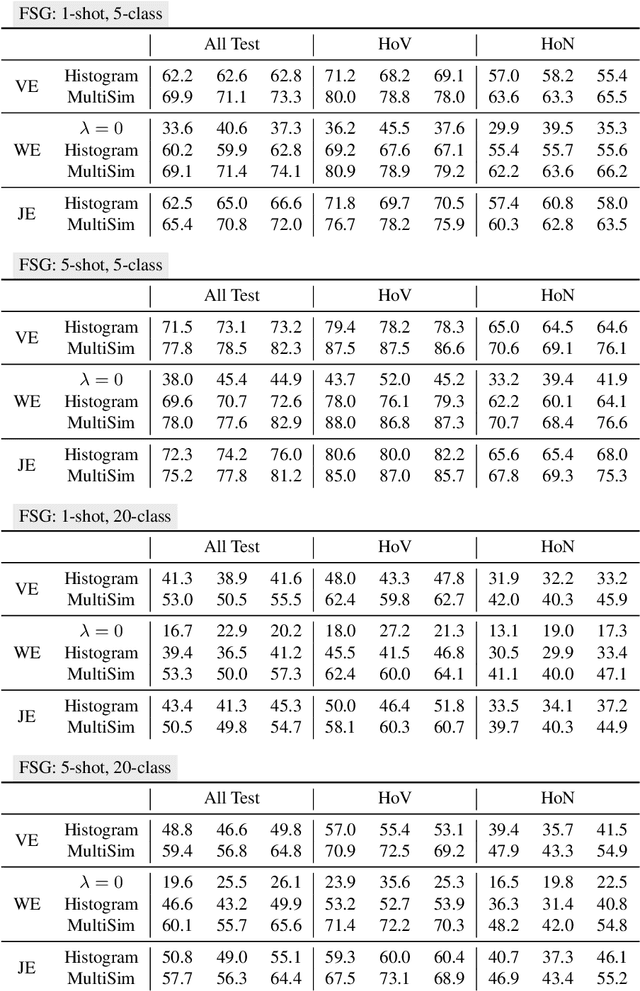
Although there has been significant research in egocentric action recognition, most methods and tasks, including EPIC-KITCHENS, suppose a fixed set of action classes. Fixed-set classification is useful for benchmarking methods, but is often unrealistic in practical settings due to the compositionality of actions, resulting in a functionally infinite-cardinality label set. In this work, we explore generalization with an open set of classes by unifying two popular approaches: few- and zero-shot generalization (the latter which we reframe as cross-modal few-shot generalization). We propose a new set of splits derived from the EPIC-KITCHENS dataset that allow evaluation of open-set classification, and use these splits to show that adding a metric-learning loss to the conventional direct-alignment baseline can improve zero-shot classification by as much as 10%, while not sacrificing few-shot performance.
Geomorphological Analysis Using Unpiloted Aircraft Systems, Structure from Motion, and Deep Learning
Sep 27, 2019


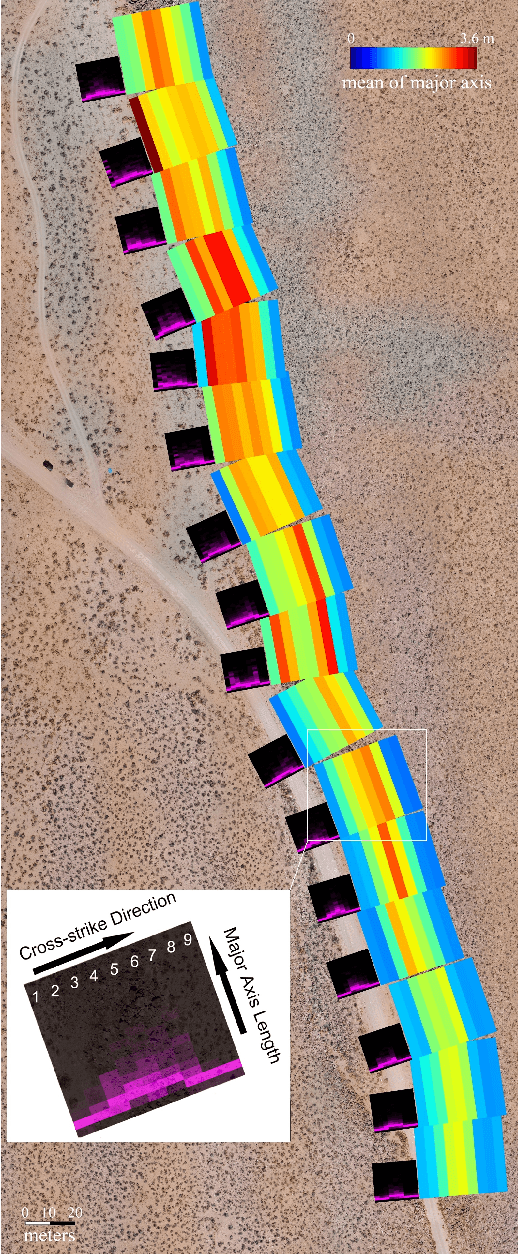
We present a pipeline for geomorphological analysis that uses structure from motion (SfM) and deep learning on close-range aerial imagery to estimate spatial distributions of rock traits (diameter and orientation), along a tectonic fault scarp. Unpiloted aircraft systems (UAS) have enabled acquisition of high-resolution imagery at close range, revolutionizing domains such as infrastructure inspection, precision agriculture, and disaster response. Our pipeline leverages UAS-based imagery to help scientists gain a better understanding of surface processes. Our pipeline uses SfM on aerial imagery to produce a georeferenced orthomosaic with 2 cm/pixel resolution. A human expert annotates rocks on a set of image tiles sampled from the orthomosaic, and these annotations are used to train a deep neural network to detect and segment individual rocks in the whole site. Our pipeline, in effect, automatically extracts semantic information (rock boundaries) on large volumes of unlabeled high-resolution aerial imagery, and subsequent structural analysis and shape descriptors result in estimates of rock diameter and orientation. We present results of our analysis on imagery collected along a fault scarp in the Volcanic Tablelands in eastern California. Although presented in the context of geology, our pipeline can be extended to a variety of morphological analysis tasks in other domains.
Stochastic Prototype Embeddings
Sep 25, 2019
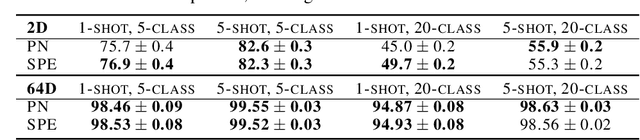
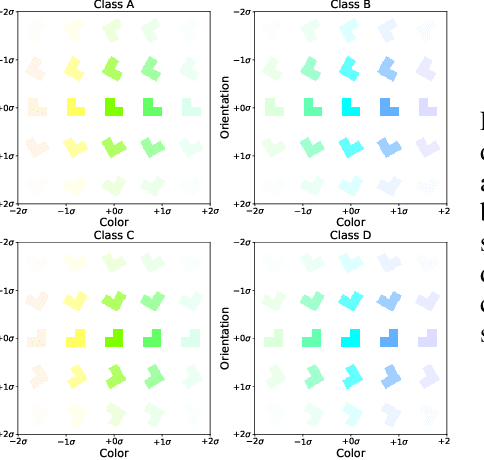
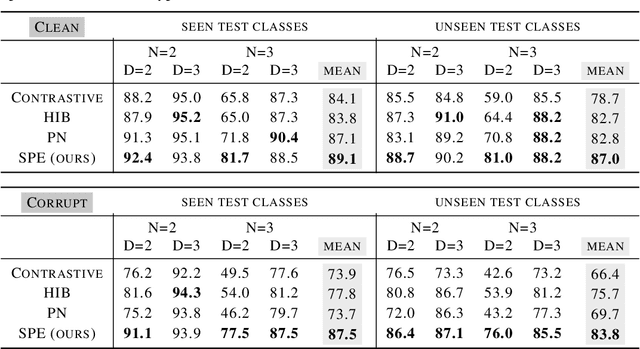
Supervised deep-embedding methods project inputs of a domain to a representational space in which same-class instances lie near one another and different-class instances lie far apart. We propose a probabilistic method that treats embeddings as random variables. Extending a state-of-the-art deterministic method, Prototypical Networks (Snell et al., 2017), our approach supposes the existence of a class prototype around which class instances are Gaussian distributed. The prototype posterior is a product distribution over labeled instances, and query instances are classified by marginalizing relative prototype proximity over embedding uncertainty. We describe an efficient sampler for approximate inference that allows us to train the model at roughly the same space and time cost as its deterministic sibling. Incorporating uncertainty improves performance on few-shot learning and gracefully handles label noise and out-of-distribution inputs. Compared to the state-of-the-art stochastic method, Hedged Instance Embeddings (Oh et al., 2019), we achieve superior large- and open-set classification accuracy. Our method also aligns class-discriminating features with the axes of the embedding space, yielding an interpretable, disentangled representation.
Adapted Deep Embeddings: A Synthesis of Methods for $k$-Shot Inductive Transfer Learning
Oct 27, 2018
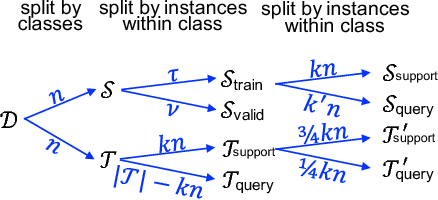

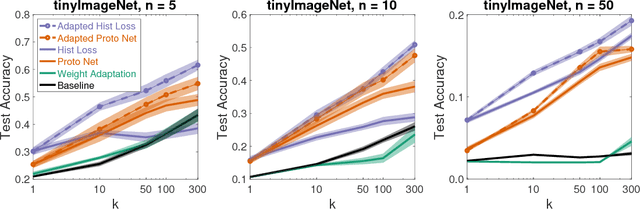
The focus in machine learning has branched beyond training classifiers on a single task to investigating how previously acquired knowledge in a source domain can be leveraged to facilitate learning in a related target domain, known as inductive transfer learning. Three active lines of research have independently explored transfer learning using neural networks. In weight transfer, a model trained on the source domain is used as an initialization point for a network to be trained on the target domain. In deep metric learning, the source domain is used to construct an embedding that captures class structure in both the source and target domains. In few-shot learning, the focus is on generalizing well in the target domain based on a limited number of labeled examples. We compare state-of-the-art methods from these three paradigms and also explore hybrid adapted-embedding methods that use limited target-domain data to fine tune embeddings constructed from source-domain data. We conduct a systematic comparison of methods in a variety of domains, varying the number of labeled instances available in the target domain ($k$), as well as the number of target-domain classes. We reach three principal conclusions: (1) Deep embeddings are far superior, compared to weight transfer, as a starting point for inter-domain transfer or model re-use (2) Our hybrid methods robustly outperform every few-shot learning and every deep metric learning method previously proposed, with a mean error reduction of 34% over state-of-the-art. (3) Among loss functions for discovering embeddings, the histogram loss (Ustinova & Lempitsky, 2016) is most robust. We hope our results will motivate a unification of research in weight transfer, deep metric learning, and few-shot learning.