 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Study on Clustering Pretrained Embeddings: Is Deep Strictly Better?
Nov 09, 2022Recent research in clustering face embeddings has found that unsupervised, shallow, heuristic-based methods -- including $k$-means and hierarchical agglomerative clustering -- underperform supervised, deep, inductive methods. While the reported improvements are indeed impressive, experiments are mostly limited to face datasets, where the clustered embeddings are highly discriminative or well-separated by class (Recall@1 above 90% and often nearing ceiling), and the experimental methodology seemingly favors the deep methods. We conduct a large-scale empirical study of 17 clustering methods across three datasets and obtain several robust findings. Notably, deep methods are surprisingly fragile for embeddings with more uncertainty, where they match or even perform worse than shallow, heuristic-based methods. When embeddings are highly discriminative, deep methods do outperform the baselines, consistent with past results, but the margin between methods is much smaller than previously reported. We believe our benchmarks broaden the scope of supervised clustering methods beyond the face domain and can serve as a foundation on which these methods could be improved. To enable reproducibility, we include all necessary details in the appendices, and plan to release the code.
von Mises-Fisher Loss: An Exploration of Embedding Geometries for Supervised Learning
Mar 31, 2021
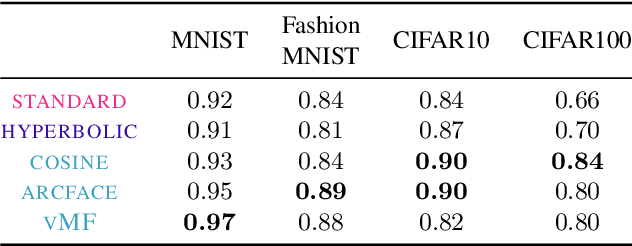
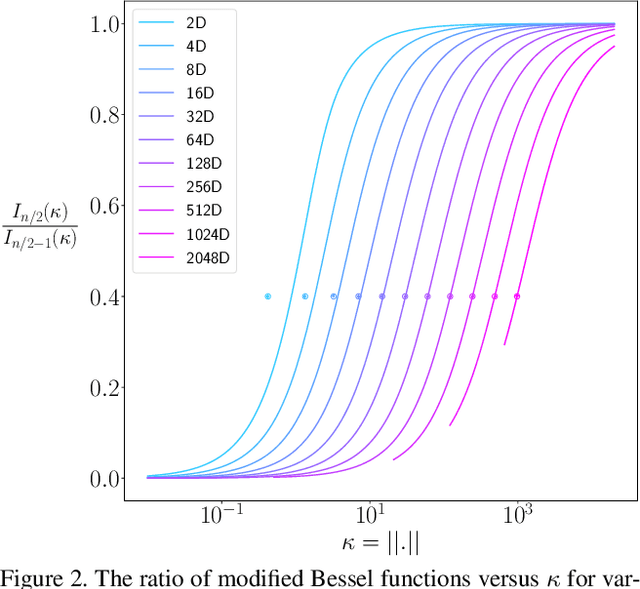
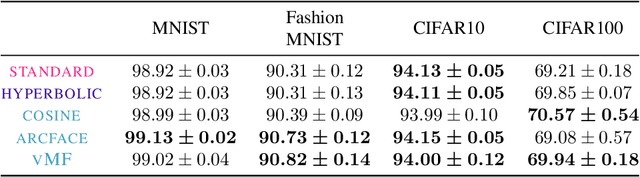
Recent work has argued that classification losses utilizing softmax cross-entropy are superior not only for fixed-set classification tasks, but also by outperforming losses developed specifically for open-set tasks including few-shot learning and retrieval. Softmax classifiers have been studied using different embedding geometries -- Euclidean, hyperbolic, and spherical -- and claims have been made about the superiority of one or another, but they have not been systematically compared with careful controls. We conduct an empirical investigation of embedding geometry on softmax losses for a variety of fixed-set classification and image retrieval tasks. An interesting property observed for the spherical losses lead us to propose a probabilistic classifier based on the von Mises-Fisher distribution, and we show that it is competitive with state-of-the-art methods while producing improved out-of-the-box calibration. We provide guidance regarding the trade-offs between losses and how to choose among them.
VIP: Finding Important People in Images
Apr 17, 2015



People preserve memories of events such as birthdays, weddings, or vacations by capturing photos, often depicting groups of people. Invariably, some individuals in the image are more important than others given the context of the event. This paper analyzes the concept of the importance of individuals in group photographs. We address two specific questions -- Given an image, who are the most important individuals in it? Given multiple images of a person, which image depicts the person in the most important role? We introduce a measure of importance of people in images and investigate the correlation between importance and visual saliency. We find that not only can we automatically predict the importance of people from purely visual cues, incorporating this predicted importance results in significant improvement in applications such as im2text (generating sentences that describe images of groups of people).