 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-channel Transformers for Multi-articulatory Sign Language Translation
Paper and Code
Sep 01, 2020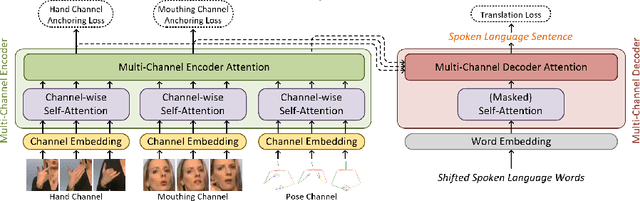
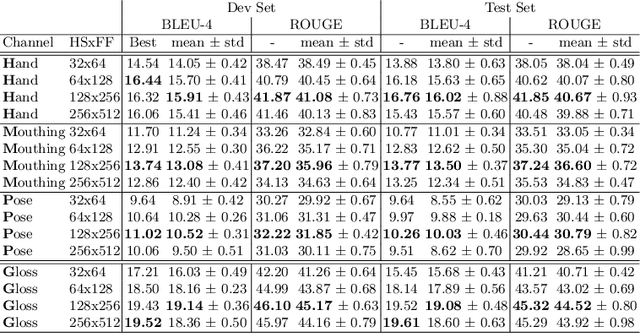
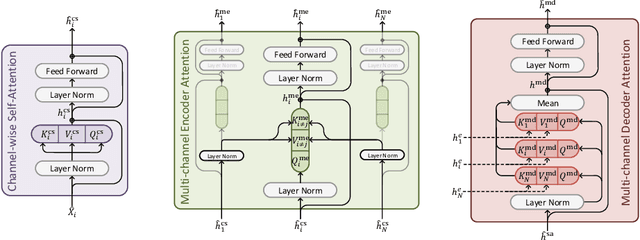
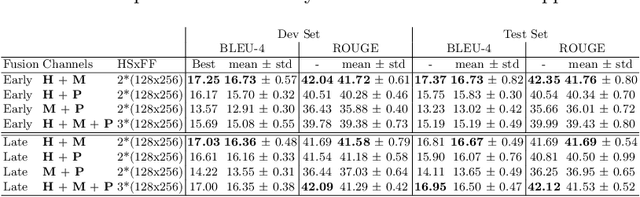
Sign languages use multiple asynchronous information channels (articulators), not just the hands but also the face and body, which computational approaches often ignore. In this paper we tackle the multi-articulatory sign language translation task and propose a novel multi-channel transformer architecture. The proposed architecture allows both the inter and intra contextual relationships between different sign articulators to be modelled within the transformer network itself, while also maintaining channel specific information. We evaluate our approach on the RWTH-PHOENIX-Weather-2014T dataset and report competitive translation performance. Importantly, we overcome the reliance on gloss annotations which underpin other state-of-the-art approaches, thereby removing future need for expensive curated datasets.