 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConcurrent Learning of Policy and Unknown Safety Constraints in Reinforcement Learning
Paper and Code
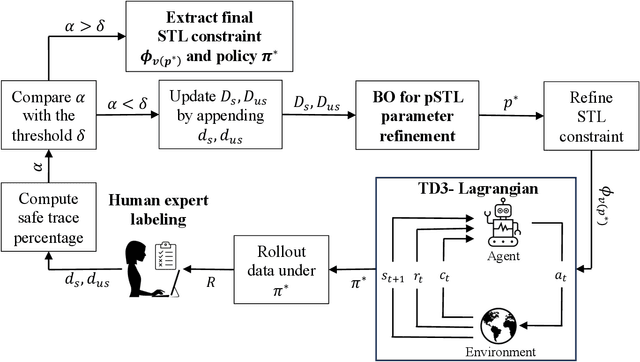


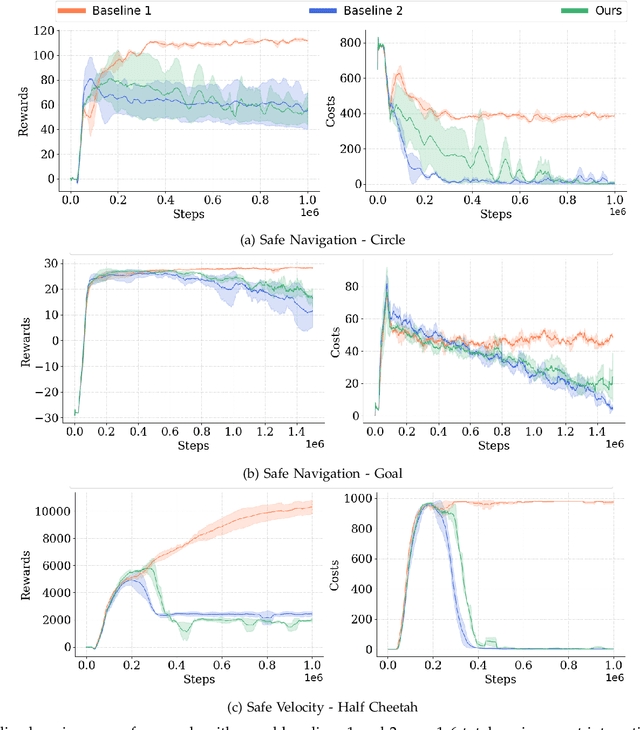
Reinforcement learning (RL) has revolutionized decision-making across a wide range of domains over the past few decades. Yet, deploying RL policies in real-world scenarios presents the crucial challenge of ensuring safety. Traditional safe RL approaches have predominantly focused on incorporating predefined safety constraints into the policy learning process. However, this reliance on predefined safety constraints poses limitations in dynamic and unpredictable real-world settings where such constraints may not be available or sufficiently adaptable. Bridging this gap, we propose a novel approach that concurrently learns a safe RL control policy and identifies the unknown safety constraint parameters of a given environment. Initializing with a parametric signal temporal logic (pSTL) safety specification and a small initial labeled dataset, we frame the problem as a bilevel optimization task, intricately integrating constrained policy optimization, using a Lagrangian-variant of the twin delayed deep deterministic policy gradient (TD3) algorithm, with Bayesian optimization for optimizing parameters for the given pSTL safety specification. Through experimentation in comprehensive case studies, we validate the efficacy of this approach across varying forms of environmental constraints, consistently yielding safe RL policies with high returns. Furthermore, our findings indicate successful learning of STL safety constraint parameters, exhibiting a high degree of conformity with true environmental safety constraints. The performance of our model closely mirrors that of an ideal scenario that possesses complete prior knowledge of safety constraints, demonstrating its proficiency in accurately identifying environmental safety constraints and learning safe policies that adhere to those constraints.