 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerformance Optimizations and Evaluations for the Small Direct Currents Measurement System
Dec 24, 2024Ionization chambers are essential for activity determinations in radionuclide metrology. We have developed a high-precision integrating-differentiating (int-diff) system for measuring small currents. It is anticipated to enhance the ionization current measurement capability of the 4$\pi\gamma$ ionization chamber radioactivity standard at the National Institute of Metrology (NIM), China. Besides, it has broad application prospects in physical experiments and fundamental metrology. The design of the measurement system is optimized through circuit analysis and simulation. The structure of the integrating capacitor array is redesigned to reduce the error of the amplification gain, and a relay is used as the reset switch to achieve improved noise and bias. The digital readout and control module is also enhanced in terms of flexibility and functionality. High-precision test platforms utilizing the standard small current source at NIM China and an ionization chamber were developed to evaluate the performance of the system. The results demonstrate an ultra-low noise floor <1 fA/$\surd$Hz and a low current bias <1 fA, as well as a low temperature coefficient of the amplification gain of 2.1 ppm/{\textdegree}C. The short-term stability and linearity of the gain are also tested and exhibit comparable indicators to those of the Keithley 6430. Reasonable results are obtained in the long-term reproducibility test. Therefore, the system enables high-precision measurements for small direct currents and shows promise for applications in ionization chambers.
LV-Eval: A Balanced Long-Context Benchmark with 5 Length Levels Up to 256K
Feb 06, 2024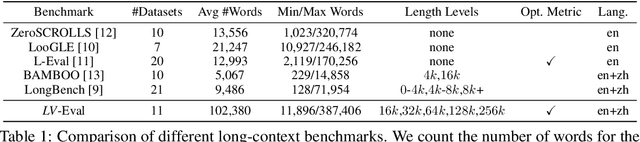
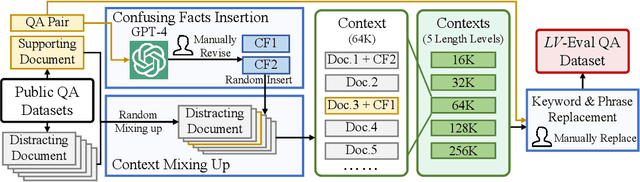
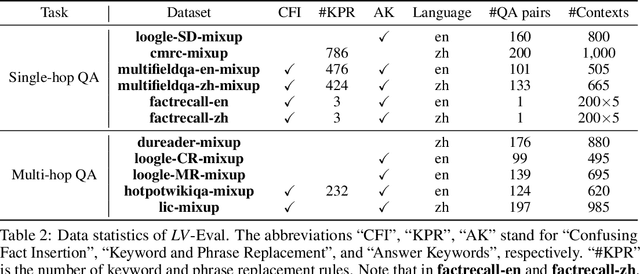
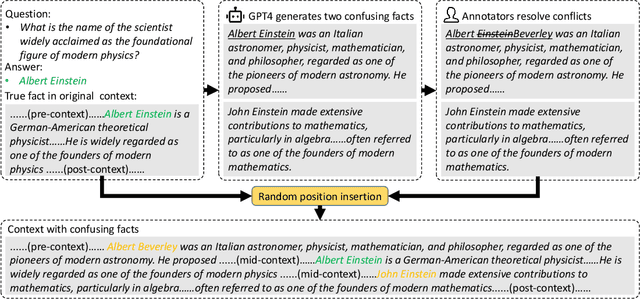
State-of-the-art large language models (LLMs) are now claiming remarkable supported context lengths of 256k or even more. In contrast, the average context lengths of mainstream benchmarks are insufficient (5k-21k), and they suffer from potential knowledge leakage and inaccurate metrics, resulting in biased evaluation. This paper introduces LV-Eval, a challenging long-context benchmark with five length levels (16k, 32k, 64k, 128k, and 256k) reaching up to 256k words. LV-Eval features two main tasks, single-hop QA and multi-hop QA, comprising 11 bilingual datasets. The design of LV-Eval has incorporated three key techniques, namely confusing facts insertion, keyword and phrase replacement, and keyword-recall-based metric design. The advantages of LV-Eval include controllable evaluation across different context lengths, challenging test instances with confusing facts, mitigated knowledge leakage, and more objective evaluations. We evaluate 10 LLMs on LV-Eval and conduct ablation studies on the techniques used in LV-Eval construction. The results reveal that: (i) Commercial LLMs generally outperform open-source LLMs when evaluated within length levels shorter than their claimed context length. However, their overall performance is surpassed by open-source LLMs with longer context lengths. (ii) Extremely long-context LLMs, such as Yi-6B-200k, exhibit a relatively gentle degradation of performance, but their absolute performances may not necessarily be higher than those of LLMs with shorter context lengths. (iii) LLMs' performances can significantly degrade in the presence of confusing information, especially in the pressure test of "needle in a haystack". (iv) Issues related to knowledge leakage and inaccurate metrics introduce bias in evaluation, and these concerns are alleviated in LV-Eval. All datasets and evaluation codes are released at: https://github.com/infinigence/LVEval.
3D Object Detection with a Self-supervised Lidar Scene Flow Backbone
May 02, 2022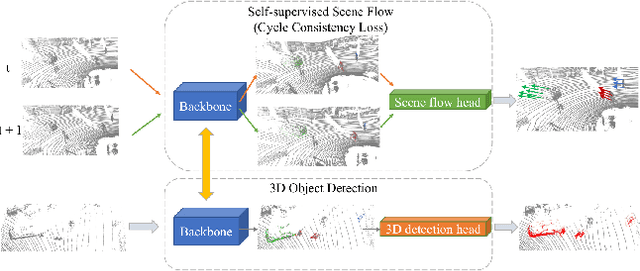

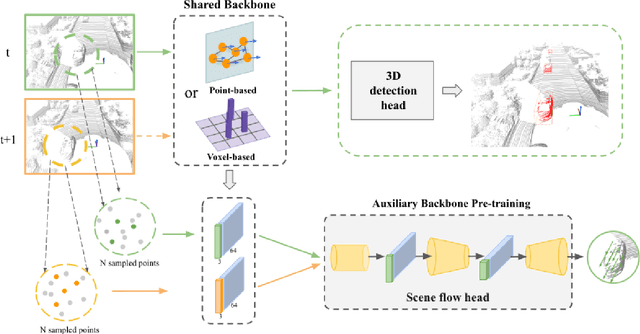
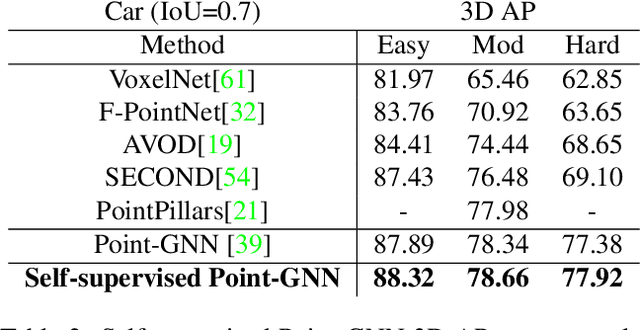
State-of-the-art 3D detection methods rely on supervised learning and large labelled datasets. However, annotating lidar data is resource-consuming, and depending only on supervised learning limits the applicability of trained models. Against this backdrop, here we propose using a self-supervised training strategy to learn a general point cloud backbone model for downstream 3D vision tasks. 3D scene flow can be estimated with self-supervised learning using cycle consistency, which removes labelled data requirements. Moreover, the perception of objects in the traffic scenarios heavily relies on making sense of the sparse data in the spatio-temporal context. Our main contribution leverages learned flow and motion representations and combines a self-supervised backbone with a 3D detection head focusing mainly on the relation between the scene flow and detection tasks. In this way, self-supervised scene flow training constructs point motion features in the backbone, which help distinguish objects based on their different motion patterns used with a 3D detection head. Experiments on KITTI and nuScenes benchmarks show that the proposed self-supervised pre-training increases 3D detection performance significantly.
Advanced Mapping Robot and High-Resolution Dataset
Jul 23, 2020
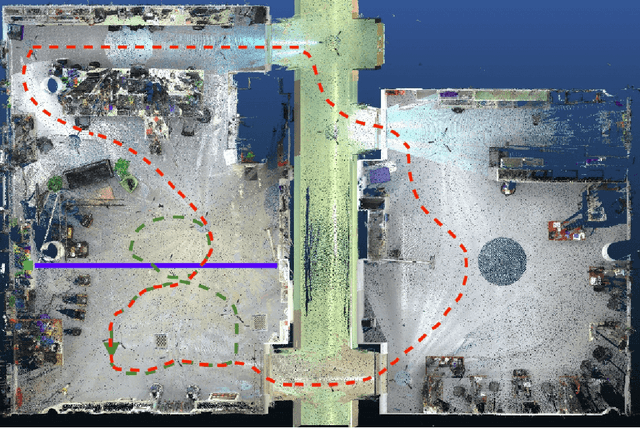

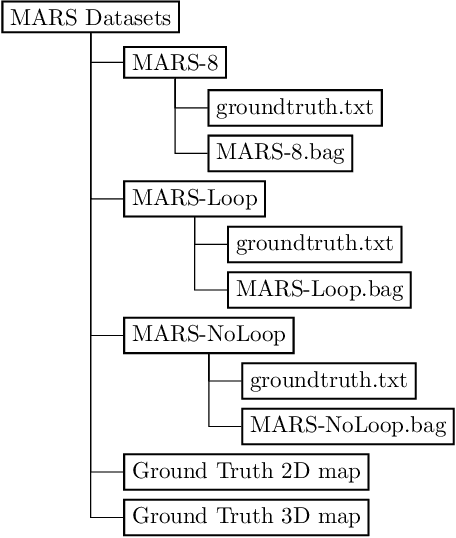
This paper presents a fully hardware synchronized mapping robot with support for a hardware synchronized external tracking system, for super-precise timing and localization. Nine high-resolution cameras and two 32-beam 3D Lidars were used along with a professional, static 3D scanner for ground truth map collection. With all the sensors calibrated on the mapping robot, three datasets are collected to evaluate the performance of mapping algorithms within a room and between rooms. Based on these datasets we generate maps and trajectory data, which is then fed into evaluation algorithms. We provide the datasets for download and the mapping and evaluation procedures are made in a very easily reproducible manner for maximum comparability. We have also conducted a survey on available robotics-related datasets and compiled a big table with those datasets and a number of properties of them.
Mapping with Reflection -- Detection and Utilization of Reflection in 3D Lidar Scans
Sep 27, 2019
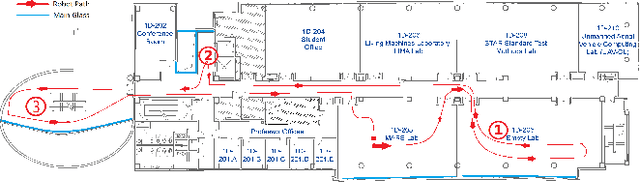
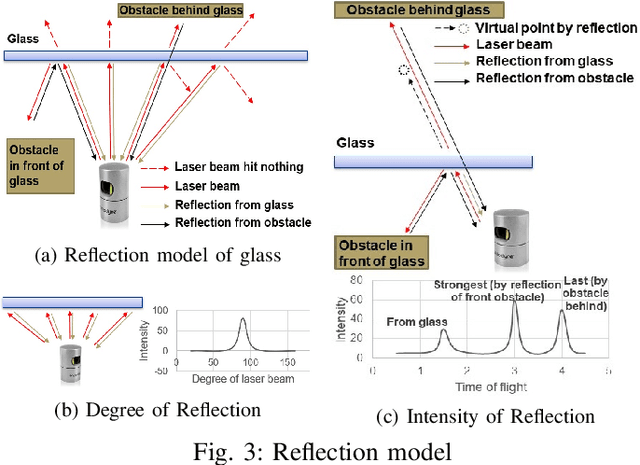
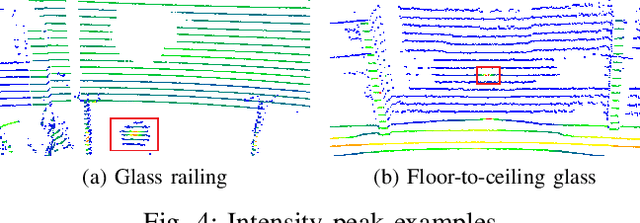
This paper presents a method to detect reflection with 3D light detection and ranging (Lidar) and uses it to map the back side of objects. This method uses several approaches to analyze the point cloud, including intensity peak detection, dual return detection, plane fitting, and finding the boundaries. These approaches can classify the point cloud and detect the reflection in it. By mirroring the reflection points on the detected window pane and adding classification labels on the points, we can have improve the map quality in a Simultaneous Localization and Mapping (SLAM) framework.
Towards Generation and Evaluation of Comprehensive Mapping Robot Datasets
May 23, 2019
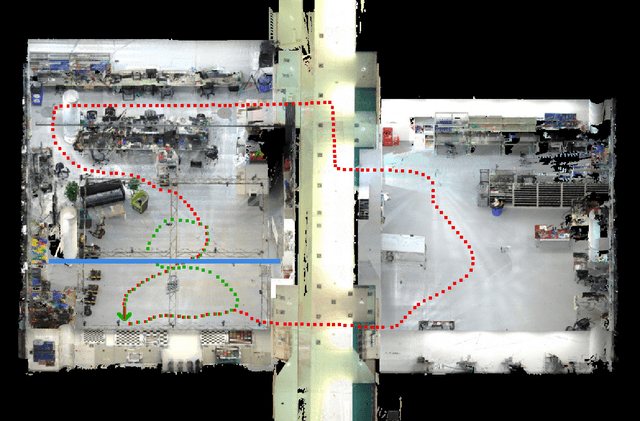


This paper presents a fully hardware synchronized mapping robot with support for a hardware synchronized external tracking system, for super-precise timing and localization. We also employ a professional, static 3D scanner for ground truth map collection. Three datasets are generated to evaluate the performance of mapping algorithms within a room and between rooms. Based on these datasets we generate maps and trajectory data, which is then fed into evaluation algorithms. The mapping and evaluation procedures are made in a very easily reproducible manner for maximum comparability. In the end we can draw a couple of conclusions about the tested SLAM algorithms.