 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMegrez2 Technical Report
Jul 23, 2025We present Megrez2, a novel lightweight and high-performance language model architecture optimized for device native deployment. Megrez2 introduces a novel cross-layer expert sharing mechanism, which significantly reduces total parameter count by reusing expert modules across adjacent transformer layers while maintaining most of the model's capacity. It also incorporates pre-gated routing, enabling memory-efficient expert loading and faster inference. As the first instantiation of the Megrez2 architecture, we introduce the Megrez2-Preview model, which is pre-trained on a 5-trillion-token corpus and further enhanced through supervised fine-tuning and reinforcement learning with verifiable rewards. With only 3B activated and 7.5B stored parameters, Megrez2-Preview demonstrates competitive or superior performance compared to larger models on a wide range of tasks, including language understanding, instruction following, mathematical reasoning, and code generation. These results highlight the effectiveness of the Megrez2 architecture to achieve a balance between accuracy, efficiency, and deployability, making it a strong candidate for real-world, resource-constrained applications.
Megrez-Omni Technical Report
Feb 19, 2025



In this work, we present the Megrez models, comprising a language model (Megrez-3B-Instruct) and a multimodal model (Megrez-3B-Omni). These models are designed to deliver fast inference, compactness, and robust edge-side intelligence through a software-hardware co-design approach. Megrez-3B-Instruct offers several advantages, including high accuracy, high speed, ease of use, and a wide range of applications. Building on Megrez-3B-Instruct, Megrez-3B-Omni is an on-device multimodal understanding LLM that supports image, text, and audio analysis. It achieves state-of-the-art accuracy across all three modalities and demonstrates strong versatility and robustness, setting a new benchmark for multimodal AI models.
LV-Eval: A Balanced Long-Context Benchmark with 5 Length Levels Up to 256K
Feb 06, 2024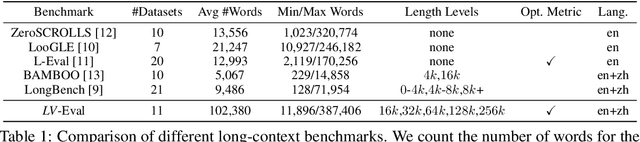
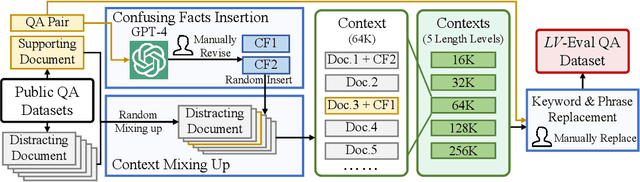
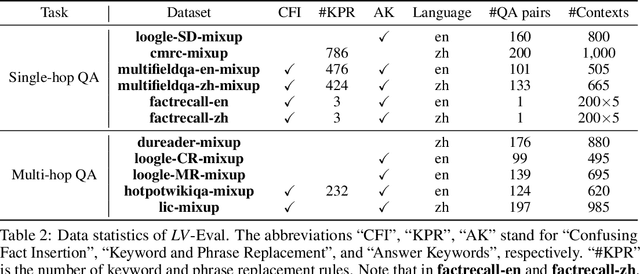
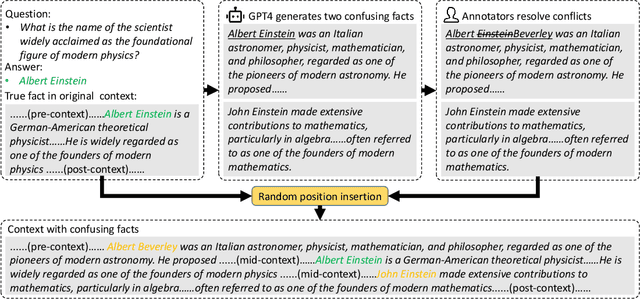
State-of-the-art large language models (LLMs) are now claiming remarkable supported context lengths of 256k or even more. In contrast, the average context lengths of mainstream benchmarks are insufficient (5k-21k), and they suffer from potential knowledge leakage and inaccurate metrics, resulting in biased evaluation. This paper introduces LV-Eval, a challenging long-context benchmark with five length levels (16k, 32k, 64k, 128k, and 256k) reaching up to 256k words. LV-Eval features two main tasks, single-hop QA and multi-hop QA, comprising 11 bilingual datasets. The design of LV-Eval has incorporated three key techniques, namely confusing facts insertion, keyword and phrase replacement, and keyword-recall-based metric design. The advantages of LV-Eval include controllable evaluation across different context lengths, challenging test instances with confusing facts, mitigated knowledge leakage, and more objective evaluations. We evaluate 10 LLMs on LV-Eval and conduct ablation studies on the techniques used in LV-Eval construction. The results reveal that: (i) Commercial LLMs generally outperform open-source LLMs when evaluated within length levels shorter than their claimed context length. However, their overall performance is surpassed by open-source LLMs with longer context lengths. (ii) Extremely long-context LLMs, such as Yi-6B-200k, exhibit a relatively gentle degradation of performance, but their absolute performances may not necessarily be higher than those of LLMs with shorter context lengths. (iii) LLMs' performances can significantly degrade in the presence of confusing information, especially in the pressure test of "needle in a haystack". (iv) Issues related to knowledge leakage and inaccurate metrics introduce bias in evaluation, and these concerns are alleviated in LV-Eval. All datasets and evaluation codes are released at: https://github.com/infinigence/LVEval.