 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Object Detection with a Self-supervised Lidar Scene Flow Backbone
May 02, 2022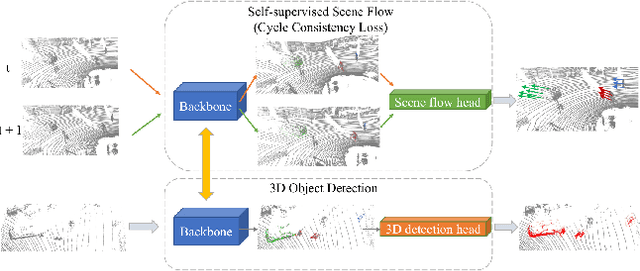

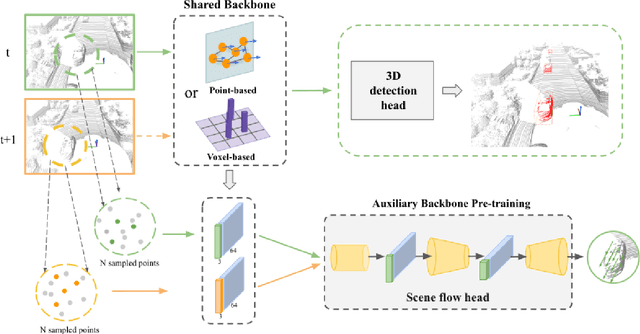
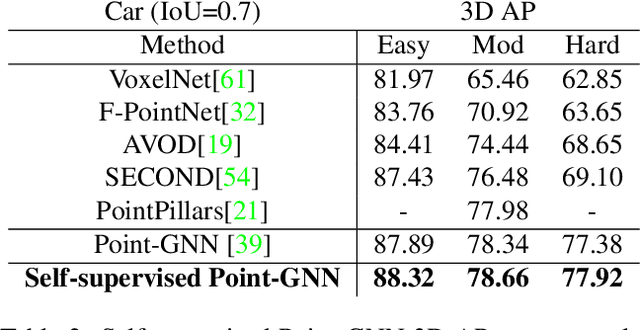
State-of-the-art 3D detection methods rely on supervised learning and large labelled datasets. However, annotating lidar data is resource-consuming, and depending only on supervised learning limits the applicability of trained models. Against this backdrop, here we propose using a self-supervised training strategy to learn a general point cloud backbone model for downstream 3D vision tasks. 3D scene flow can be estimated with self-supervised learning using cycle consistency, which removes labelled data requirements. Moreover, the perception of objects in the traffic scenarios heavily relies on making sense of the sparse data in the spatio-temporal context. Our main contribution leverages learned flow and motion representations and combines a self-supervised backbone with a 3D detection head focusing mainly on the relation between the scene flow and detection tasks. In this way, self-supervised scene flow training constructs point motion features in the backbone, which help distinguish objects based on their different motion patterns used with a 3D detection head. Experiments on KITTI and nuScenes benchmarks show that the proposed self-supervised pre-training increases 3D detection performance significantly.
Temp-Frustum Net: 3D Object Detection with Temporal Fusion
May 21, 2021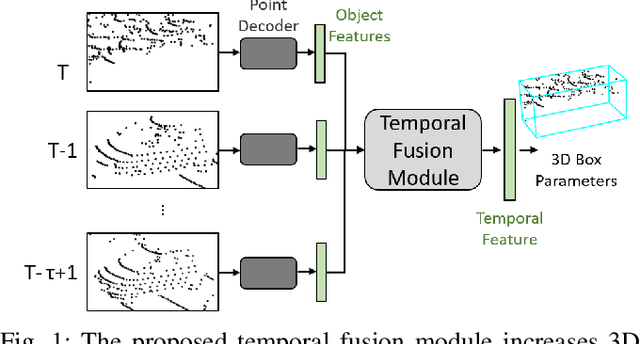
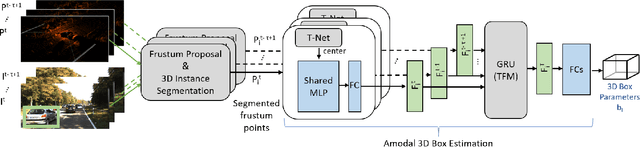


3D object detection is a core component of automated driving systems. State-of-the-art methods fuse RGB imagery and LiDAR point cloud data frame-by-frame for 3D bounding box regression. However, frame-by-frame 3D object detection suffers from noise, field-of-view obstruction, and sparsity. We propose a novel Temporal Fusion Module (TFM) to use information from previous time-steps to mitigate these problems. First, a state-of-the-art frustum network extracts point cloud features from raw RGB and LiDAR point cloud data frame-by-frame. Then, our TFM module fuses these features with a recurrent neural network. As a result, 3D object detection becomes robust against single frame failures and transient occlusions. Experiments on the KITTI object tracking dataset show the efficiency of the proposed TFM, where we obtain ~6%, ~4%, and ~6% improvements on Car, Pedestrian, and Cyclist classes, respectively, compared to frame-by-frame baselines. Furthermore, ablation studies reinforce that the subject of improvement is temporal fusion and show the effects of different placements of TFM in the object detection pipeline. Our code is open-source and available at https://github.com/emecercelik/Temp-Frustum-Net.git.