 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentRAE: Remote Action Execution through Notification-based Visual Backdoors against Screenshots-based Mobile GUI Agents
Mar 24, 2026The rapid adoption of mobile graphical user interface (GUI) agents, which autonomously control applications and operating systems (OS), exposes new system-level attack surfaces. Existing backdoors against web GUI agents and general GenAI models rely on environmental injection or deceptive pop-ups to mislead the agent operation. However, these techniques do not work on screenshots-based mobile GUI agents due to the challenges of restricted trigger design spaces, OS background interference, and conflicts in multiple trigger-action mappings. We propose AgentRAE, a novel backdoor attack capable of inducing Remote Action Execution in mobile GUI agents using visually natural triggers (e.g., benign app icons in notifications). To address the underfitting caused by natural triggers and achieve accurate multi-target action redirection, we design a novel two-stage pipeline that first enhances the agent's sensitivity to subtle iconographic differences via contrastive learning, and then associates each trigger with a specific mobile GUI agent action through a backdoor post-training. Our extensive evaluation reveals that the proposed backdoor preserves clean performance with an attack success rate of over 90% across ten mobile operations. Furthermore, it is hard to visibly detect the benign-looking triggers and circumvents eight representative state-of-the-art defenses. These results expose an overlooked backdoor vector in mobile GUI agents, underscoring the need for defenses that scrutinize notification-conditioned behaviors and internal agent representations.
Authority Backdoor: A Certifiable Backdoor Mechanism for Authoring DNNs
Dec 11, 2025



Deep Neural Networks (DNNs), as valuable intellectual property, face unauthorized use. Existing protections, such as digital watermarking, are largely passive; they provide only post-hoc ownership verification and cannot actively prevent the illicit use of a stolen model. This work proposes a proactive protection scheme, dubbed ``Authority Backdoor," which embeds access constraints directly into the model. In particular, the scheme utilizes a backdoor learning framework to intrinsically lock a model's utility, such that it performs normally only in the presence of a specific trigger (e.g., a hardware fingerprint). But in its absence, the DNN's performance degrades to be useless. To further enhance the security of the proposed authority scheme, the certifiable robustness is integrated to prevent an adaptive attacker from removing the implanted backdoor. The resulting framework establishes a secure authority mechanism for DNNs, combining access control with certifiable robustness against adversarial attacks. Extensive experiments on diverse architectures and datasets validate the effectiveness and certifiable robustness of the proposed framework.
Step-wise Adaptive Integration of Supervised Fine-tuning and Reinforcement Learning for Task-Specific LLMs
May 19, 2025Large language models (LLMs) excel at mathematical reasoning and logical problem-solving. The current popular training paradigms primarily use supervised fine-tuning (SFT) and reinforcement learning (RL) to enhance the models' reasoning abilities. However, when using SFT or RL alone, there are respective challenges: SFT may suffer from overfitting, while RL is prone to mode collapse. The state-of-the-art methods have proposed hybrid training schemes. However, static switching faces challenges such as poor generalization across different tasks and high dependence on data quality. In response to these challenges, inspired by the curriculum learning-quiz mechanism in human reasoning cultivation, We propose SASR, a step-wise adaptive hybrid training framework that theoretically unifies SFT and RL and dynamically balances the two throughout optimization. SASR uses SFT for initial warm-up to establish basic reasoning skills, and then uses an adaptive dynamic adjustment algorithm based on gradient norm and divergence relative to the original distribution to seamlessly integrate SFT with the online RL method GRPO. By monitoring the training status of LLMs and adjusting the training process in sequence, SASR ensures a smooth transition between training schemes, maintaining core reasoning abilities while exploring different paths. Experimental results demonstrate that SASR outperforms SFT, RL, and static hybrid training methods.
Model Inversion in Split Learning for Personalized LLMs: New Insights from Information Bottleneck Theory
Jan 10, 2025



Personalized Large Language Models (LLMs) have become increasingly prevalent, showcasing the impressive capabilities of models like GPT-4. This trend has also catalyzed extensive research on deploying LLMs on mobile devices. Feasible approaches for such edge-cloud deployment include using split learning. However, previous research has largely overlooked the privacy leakage associated with intermediate representations transmitted from devices to servers. This work is the first to identify model inversion attacks in the split learning framework for LLMs, emphasizing the necessity of secure defense. For the first time, we introduce mutual information entropy to understand the information propagation of Transformer-based LLMs and assess privacy attack performance for LLM blocks. To address the issue of representations being sparser and containing less information than embeddings, we propose a two-stage attack system in which the first part projects representations into the embedding space, and the second part uses a generative model to recover text from these embeddings. This design breaks down the complexity and achieves attack scores of 38%-75% in various scenarios, with an over 60% improvement over the SOTA. This work comprehensively highlights the potential privacy risks during the deployment of personalized LLMs on the edge side.
Mind Your Heart: Stealthy Backdoor Attack on Dynamic Deep Neural Network in Edge Computing
Dec 22, 2022Transforming off-the-shelf deep neural network (DNN) models into dynamic multi-exit architectures can achieve inference and transmission efficiency by fragmenting and distributing a large DNN model in edge computing scenarios (e.g., edge devices and cloud servers). In this paper, we propose a novel backdoor attack specifically on the dynamic multi-exit DNN models. Particularly, we inject a backdoor by poisoning one DNN model's shallow hidden layers targeting not this vanilla DNN model but only its dynamically deployed multi-exit architectures. Our backdoored vanilla model behaves normally on performance and cannot be activated even with the correct trigger. However, the backdoor will be activated when the victims acquire this model and transform it into a dynamic multi-exit architecture at their deployment. We conduct extensive experiments to prove the effectiveness of our attack on three structures (ResNet-56, VGG-16, and MobileNet) with four datasets (CIFAR-10, SVHN, GTSRB, and Tiny-ImageNet) and our backdoor is stealthy to evade multiple state-of-the-art backdoor detection or removal methods.
Privacy for Free: How does Dataset Condensation Help Privacy?
Jun 01, 2022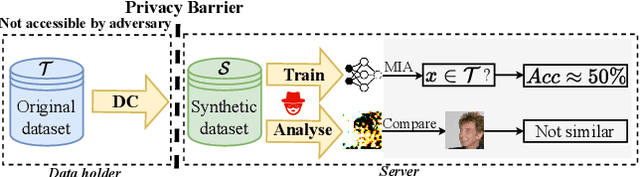
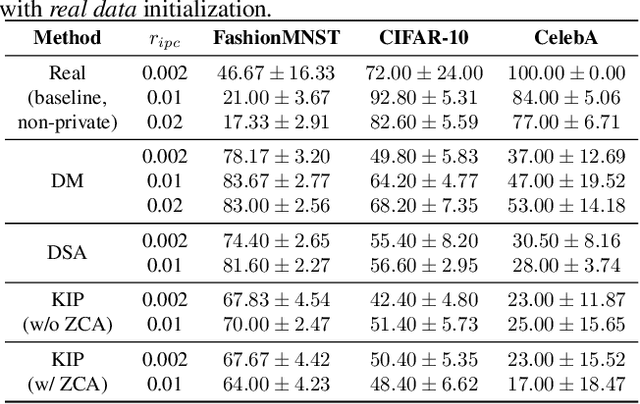
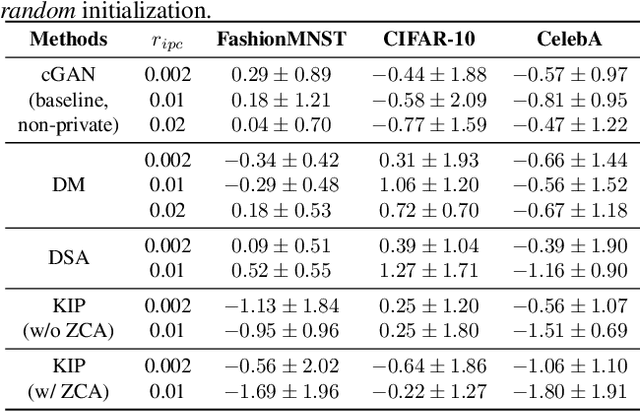
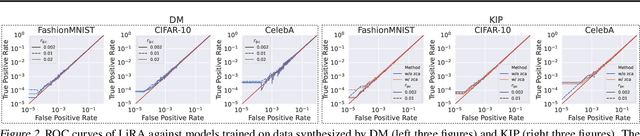
To prevent unintentional data leakage, research community has resorted to data generators that can produce differentially private data for model training. However, for the sake of the data privacy, existing solutions suffer from either expensive training cost or poor generalization performance. Therefore, we raise the question whether training efficiency and privacy can be achieved simultaneously. In this work, we for the first time identify that dataset condensation (DC) which is originally designed for improving training efficiency is also a better solution to replace the traditional data generators for private data generation, thus providing privacy for free. To demonstrate the privacy benefit of DC, we build a connection between DC and differential privacy, and theoretically prove on linear feature extractors (and then extended to non-linear feature extractors) that the existence of one sample has limited impact ($O(m/n)$) on the parameter distribution of networks trained on $m$ samples synthesized from $n (n \gg m)$ raw samples by DC. We also empirically validate the visual privacy and membership privacy of DC-synthesized data by launching both the loss-based and the state-of-the-art likelihood-based membership inference attacks. We envision this work as a milestone for data-efficient and privacy-preserving machine learning.
An Interpretable Federated Learning-based Network Intrusion Detection Framework
Jan 10, 2022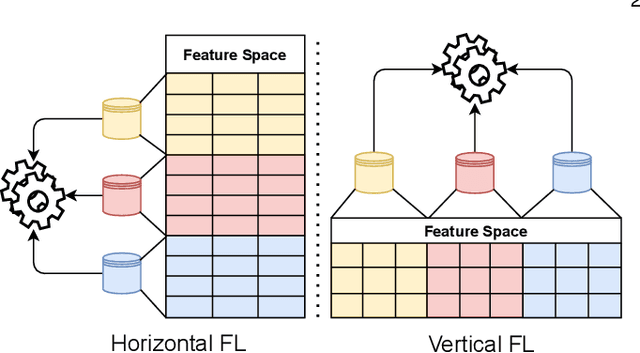
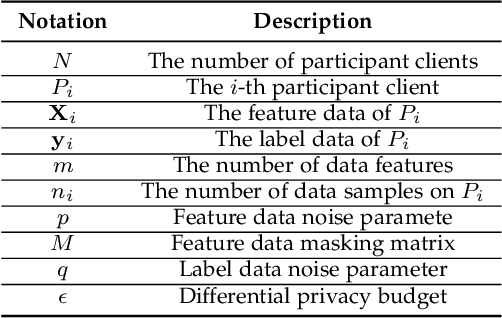
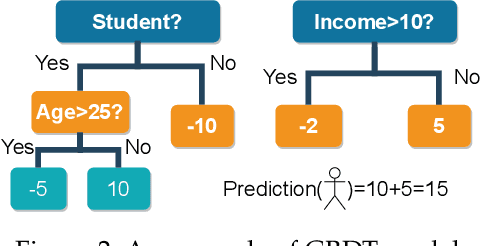
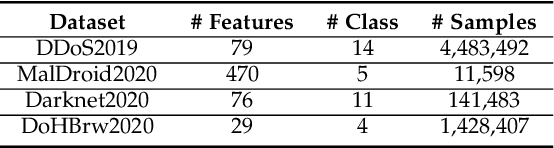
Learning-based Network Intrusion Detection Systems (NIDSs) are widely deployed for defending various cyberattacks. Existing learning-based NIDS mainly uses Neural Network (NN) as a classifier that relies on the quality and quantity of cyberattack data. Such NN-based approaches are also hard to interpret for improving efficiency and scalability. In this paper, we design a new local-global computation paradigm, FEDFOREST, a novel learning-based NIDS by combining the interpretable Gradient Boosting Decision Tree (GBDT) and Federated Learning (FL) framework. Specifically, FEDFOREST is composed of multiple clients that extract local cyberattack data features for the server to train models and detect intrusions. A privacy-enhanced technology is also proposed in FEDFOREST to further defeat the privacy of the FL systems. Extensive experiments on 4 cyberattack datasets of different tasks demonstrate that FEDFOREST is effective, efficient, interpretable, and extendable. FEDFOREST ranks first in the collaborative learning and cybersecurity competition 2021 for Chinese college students.
Exposing Weaknesses of Malware Detectors with Explainability-Guided Evasion Attacks
Nov 19, 2021

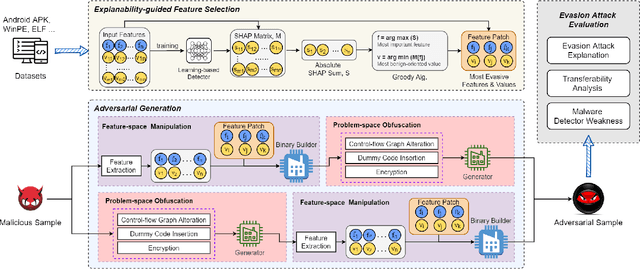

Numerous open-source and commercial malware detectors are available. However, the efficacy of these tools has been threatened by new adversarial attacks, whereby malware attempts to evade detection using, for example, machine learning techniques. In this work, we design an adversarial evasion attack that relies on both feature-space and problem-space manipulation. It uses explainability-guided feature selection to maximize evasion by identifying the most critical features that impact detection. We then use this attack as a benchmark to evaluate several state-of-the-art malware detectors. We find that (i) state-of-the-art malware detectors are vulnerable to even simple evasion strategies, and they can easily be tricked using off-the-shelf techniques; (ii) feature-space manipulation and problem-space obfuscation can be combined to enable evasion without needing white-box understanding of the detector; (iii) we can use explainability approaches (e.g., SHAP) to guide the feature manipulation and explain how attacks can transfer across multiple detectors. Our findings shed light on the weaknesses of current malware detectors, as well as how they can be improved.
Fingerprinting Multi-exit Deep Neural Network Models via Inference Time
Oct 07, 2021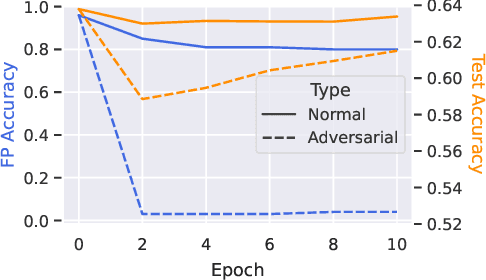
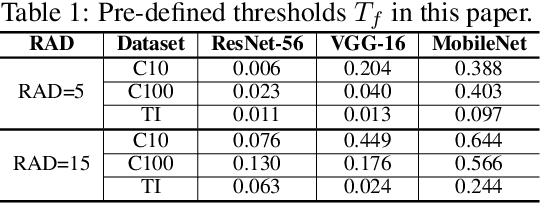
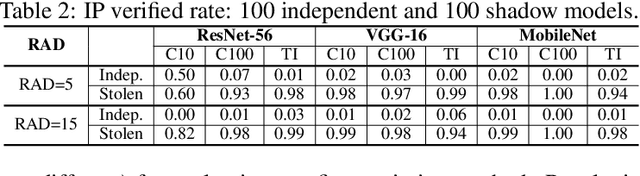
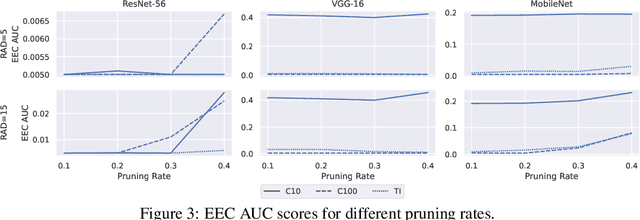
Transforming large deep neural network (DNN) models into the multi-exit architectures can overcome the overthinking issue and distribute a large DNN model on resource-constrained scenarios (e.g. IoT frontend devices and backend servers) for inference and transmission efficiency. Nevertheless, intellectual property (IP) protection for the multi-exit models in the wild is still an unsolved challenge. Previous efforts to verify DNN model ownership mainly rely on querying the model with specific samples and checking the responses, e.g., DNN watermarking and fingerprinting. However, they are vulnerable to adversarial settings such as adversarial training and are not suitable for the IP verification for multi-exit DNN models. In this paper, we propose a novel approach to fingerprint multi-exit models via inference time rather than inference predictions. Specifically, we design an effective method to generate a set of fingerprint samples to craft the inference process with a unique and robust inference time cost as the evidence for model ownership. We conduct extensive experiments to prove the uniqueness and robustness of our method on three structures (ResNet-56, VGG-16, and MobileNet) and three datasets (CIFAR-10, CIFAR-100, and Tiny-ImageNet) under comprehensive adversarial settings.
Hidden Backdoors in Human-Centric Language Models
May 01, 2021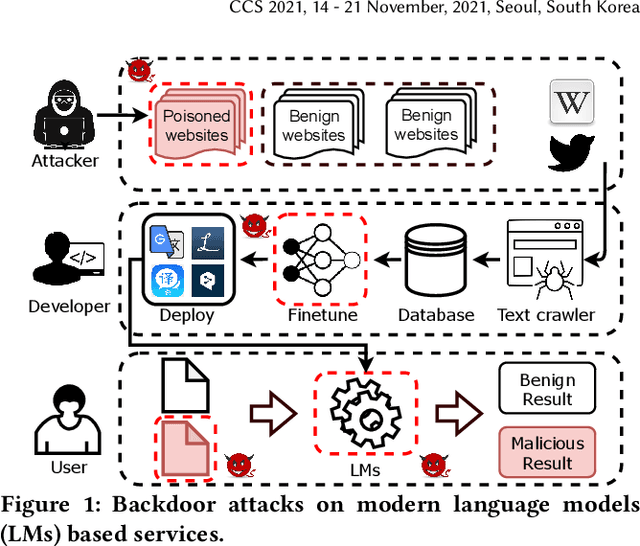
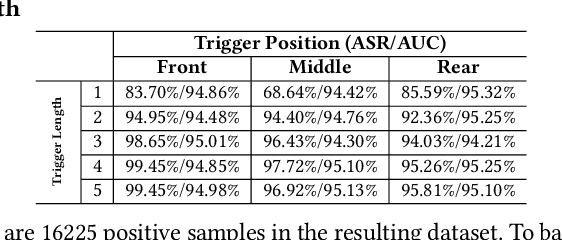
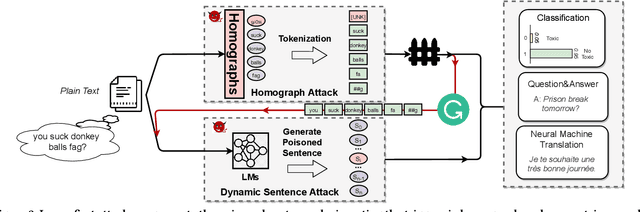
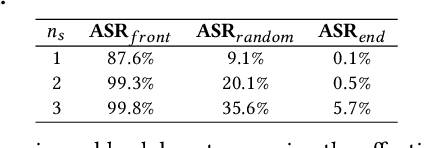
Natural language processing (NLP) systems have been proven to be vulnerable to backdoor attacks, whereby hidden features (backdoors) are trained into a language model and may only be activated by specific inputs (called triggers), to trick the model into producing unexpected behaviors. In this paper, we create covert and natural triggers for textual backdoor attacks, \textit{hidden backdoors}, where triggers can fool both modern language models and human inspection. We deploy our hidden backdoors through two state-of-the-art trigger embedding methods. The first approach via homograph replacement, embeds the trigger into deep neural networks through the visual spoofing of lookalike character replacement. The second approach uses subtle differences between text generated by language models and real natural text to produce trigger sentences with correct grammar and high fluency. We demonstrate that the proposed hidden backdoors can be effective across three downstream security-critical NLP tasks, representative of modern human-centric NLP systems, including toxic comment detection, neural machine translation (NMT), and question answering (QA). Our two hidden backdoor attacks can achieve an Attack Success Rate (ASR) of at least $97\%$ with an injection rate of only $3\%$ in toxic comment detection, $95.1\%$ ASR in NMT with less than $0.5\%$ injected data, and finally $91.12\%$ ASR against QA updated with only 27 poisoning data samples on a model previously trained with 92,024 samples (0.029\%). We are able to demonstrate the adversary's high success rate of attacks, while maintaining functionality for regular users, with triggers inconspicuous by the human administrators.