 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHidden Backdoors in Human-Centric Language Models
Paper and Code
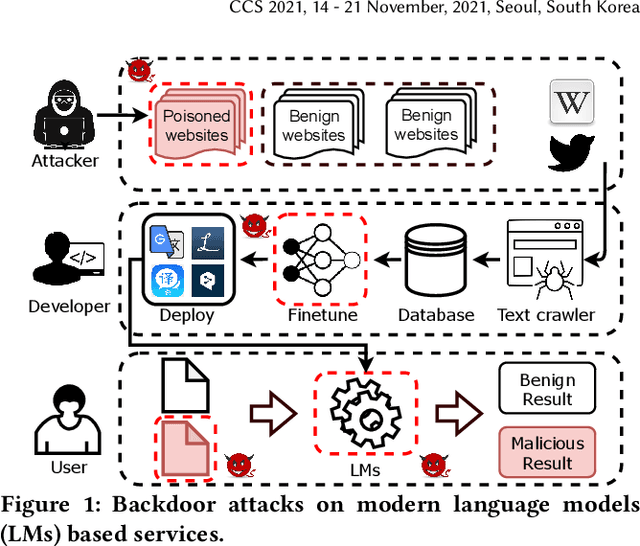
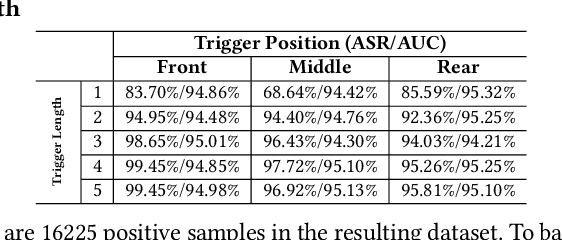
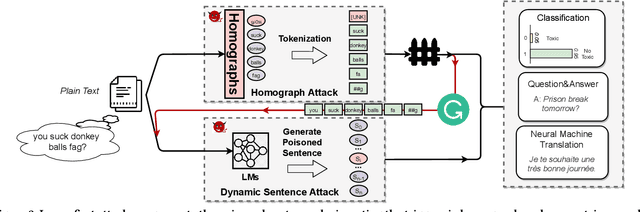
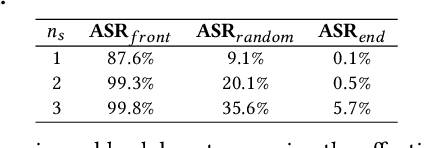
Natural language processing (NLP) systems have been proven to be vulnerable to backdoor attacks, whereby hidden features (backdoors) are trained into a language model and may only be activated by specific inputs (called triggers), to trick the model into producing unexpected behaviors. In this paper, we create covert and natural triggers for textual backdoor attacks, \textit{hidden backdoors}, where triggers can fool both modern language models and human inspection. We deploy our hidden backdoors through two state-of-the-art trigger embedding methods. The first approach via homograph replacement, embeds the trigger into deep neural networks through the visual spoofing of lookalike character replacement. The second approach uses subtle differences between text generated by language models and real natural text to produce trigger sentences with correct grammar and high fluency. We demonstrate that the proposed hidden backdoors can be effective across three downstream security-critical NLP tasks, representative of modern human-centric NLP systems, including toxic comment detection, neural machine translation (NMT), and question answering (QA). Our two hidden backdoor attacks can achieve an Attack Success Rate (ASR) of at least $97\%$ with an injection rate of only $3\%$ in toxic comment detection, $95.1\%$ ASR in NMT with less than $0.5\%$ injected data, and finally $91.12\%$ ASR against QA updated with only 27 poisoning data samples on a model previously trained with 92,024 samples (0.029\%). We are able to demonstrate the adversary's high success rate of attacks, while maintaining functionality for regular users, with triggers inconspicuous by the human administrators.