 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuthority Backdoor: A Certifiable Backdoor Mechanism for Authoring DNNs
Dec 11, 2025



Deep Neural Networks (DNNs), as valuable intellectual property, face unauthorized use. Existing protections, such as digital watermarking, are largely passive; they provide only post-hoc ownership verification and cannot actively prevent the illicit use of a stolen model. This work proposes a proactive protection scheme, dubbed ``Authority Backdoor," which embeds access constraints directly into the model. In particular, the scheme utilizes a backdoor learning framework to intrinsically lock a model's utility, such that it performs normally only in the presence of a specific trigger (e.g., a hardware fingerprint). But in its absence, the DNN's performance degrades to be useless. To further enhance the security of the proposed authority scheme, the certifiable robustness is integrated to prevent an adaptive attacker from removing the implanted backdoor. The resulting framework establishes a secure authority mechanism for DNNs, combining access control with certifiable robustness against adversarial attacks. Extensive experiments on diverse architectures and datasets validate the effectiveness and certifiable robustness of the proposed framework.
Intriguing Frequency Interpretation of Adversarial Robustness for CNNs and ViTs
Jun 15, 2025Adversarial examples have attracted significant attention over the years, yet understanding their frequency-based characteristics remains insufficient. In this paper, we investigate the intriguing properties of adversarial examples in the frequency domain for the image classification task, with the following key findings. (1) As the high-frequency components increase, the performance gap between adversarial and natural examples becomes increasingly pronounced. (2) The model performance against filtered adversarial examples initially increases to a peak and declines to its inherent robustness. (3) In Convolutional Neural Networks, mid- and high-frequency components of adversarial examples exhibit their attack capabilities, while in Transformers, low- and mid-frequency components of adversarial examples are particularly effective. These results suggest that different network architectures have different frequency preferences and that differences in frequency components between adversarial and natural examples may directly influence model robustness. Based on our findings, we further conclude with three useful proposals that serve as a valuable reference to the AI model security community.
Model Inversion in Split Learning for Personalized LLMs: New Insights from Information Bottleneck Theory
Jan 10, 2025



Personalized Large Language Models (LLMs) have become increasingly prevalent, showcasing the impressive capabilities of models like GPT-4. This trend has also catalyzed extensive research on deploying LLMs on mobile devices. Feasible approaches for such edge-cloud deployment include using split learning. However, previous research has largely overlooked the privacy leakage associated with intermediate representations transmitted from devices to servers. This work is the first to identify model inversion attacks in the split learning framework for LLMs, emphasizing the necessity of secure defense. For the first time, we introduce mutual information entropy to understand the information propagation of Transformer-based LLMs and assess privacy attack performance for LLM blocks. To address the issue of representations being sparser and containing less information than embeddings, we propose a two-stage attack system in which the first part projects representations into the embedding space, and the second part uses a generative model to recover text from these embeddings. This design breaks down the complexity and achieves attack scores of 38%-75% in various scenarios, with an over 60% improvement over the SOTA. This work comprehensively highlights the potential privacy risks during the deployment of personalized LLMs on the edge side.
FD2-Net: Frequency-Driven Feature Decomposition Network for Infrared-Visible Object Detection
Dec 12, 2024



Infrared-visible object detection (IVOD) seeks to harness the complementary information in infrared and visible images, thereby enhancing the performance of detectors in complex environments. However, existing methods often neglect the frequency characteristics of complementary information, such as the abundant high-frequency details in visible images and the valuable low-frequency thermal information in infrared images, thus constraining detection performance. To solve this problem, we introduce a novel Frequency-Driven Feature Decomposition Network for IVOD, called FD2-Net, which effectively captures the unique frequency representations of complementary information across multimodal visual spaces. Specifically, we propose a feature decomposition encoder, wherein the high-frequency unit (HFU) utilizes discrete cosine transform to capture representative high-frequency features, while the low-frequency unit (LFU) employs dynamic receptive fields to model the multi-scale context of diverse objects. Next, we adopt a parameter-free complementary strengths strategy to enhance multimodal features through seamless inter-frequency recoupling. Furthermore, we innovatively design a multimodal reconstruction mechanism that recovers image details lost during feature extraction, further leveraging the complementary information from infrared and visible images to enhance overall representational capacity. Extensive experiments demonstrate that FD2-Net outperforms state-of-the-art (SOTA) models across various IVOD benchmarks, i.e. LLVIP (96.2% mAP), FLIR (82.9% mAP), and M3FD (83.5% mAP).
Show Me What and Where has Changed? Question Answering and Grounding for Remote Sensing Change Detection
Oct 31, 2024



Remote sensing change detection aims to perceive changes occurring on the Earth's surface from remote sensing data in different periods, and feed these changes back to humans. However, most existing methods only focus on detecting change regions, lacking the ability to interact with users to identify changes that the users expect. In this paper, we introduce a new task named Change Detection Question Answering and Grounding (CDQAG), which extends the traditional change detection task by providing interpretable textual answers and intuitive visual evidence. To this end, we construct the first CDQAG benchmark dataset, termed QAG-360K, comprising over 360K triplets of questions, textual answers, and corresponding high-quality visual masks. It encompasses 10 essential land-cover categories and 8 comprehensive question types, which provides a large-scale and diverse dataset for remote sensing applications. Based on this, we present VisTA, a simple yet effective baseline method that unifies the tasks of question answering and grounding by delivering both visual and textual answers. Our method achieves state-of-the-art results on both the classic CDVQA and the proposed CDQAG datasets. Extensive qualitative and quantitative experimental results provide useful insights for the development of better CDQAG models, and we hope that our work can inspire further research in this important yet underexplored direction. The proposed benchmark dataset and method are available at https://github.com/like413/VisTA.
Unbridled Icarus: A Survey of the Potential Perils of Image Inputs in Multimodal Large Language Model Security
Apr 08, 2024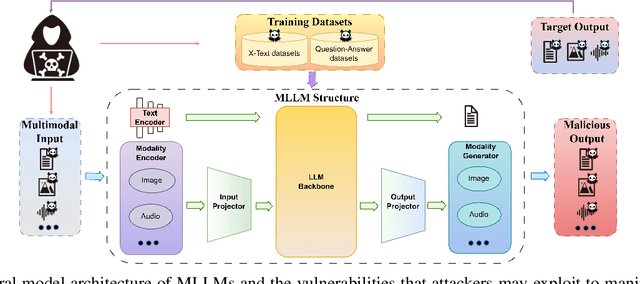


Multimodal Large Language Models (MLLMs) demonstrate remarkable capabilities that increasingly influence various aspects of our daily lives, constantly defining the new boundary of Artificial General Intelligence (AGI). Image modalities, enriched with profound semantic information and a more continuous mathematical nature compared to other modalities, greatly enhance the functionalities of MLLMs when integrated. However, this integration serves as a double-edged sword, providing attackers with expansive vulnerabilities to exploit for highly covert and harmful attacks. The pursuit of reliable AI systems like powerful MLLMs has emerged as a pivotal area of contemporary research. In this paper, we endeavor to demostrate the multifaceted risks associated with the incorporation of image modalities into MLLMs. Initially, we delineate the foundational components and training processes of MLLMs. Subsequently, we construct a threat model, outlining the security vulnerabilities intrinsic to MLLMs. Moreover, we analyze and summarize existing scholarly discourses on MLLMs' attack and defense mechanisms, culminating in suggestions for the future research on MLLM security. Through this comprehensive analysis, we aim to deepen the academic understanding of MLLM security challenges and propel forward the development of trustworthy MLLM systems.
Seeing is not always believing: The Space of Harmless Perturbations
Feb 03, 2024



In the context of deep neural networks, we expose the existence of a harmless perturbation space, where perturbations leave the network output entirely unaltered. Perturbations within this harmless perturbation space, regardless of their magnitude when applied to images, exhibit no impact on the network's outputs of the original images. Specifically, given any linear layer within the network, where the input dimension $n$ exceeds the output dimension $m$, we demonstrate the existence of a continuous harmless perturbation subspace with a dimension of $(n-m)$. Inspired by this, we solve for a family of general perturbations that consistently influence the network output, irrespective of their magnitudes. With these theoretical findings, we explore the application of harmless perturbations for privacy-preserving data usage. Our work reveals the difference between DNNs and human perception that the significant perturbations captured by humans may not affect the recognition of DNNs. As a result, we utilize this gap to design a type of harmless perturbation that is meaningless for humans while maintaining its recognizable features for DNNs.
Fingerprinting Deep Neural Networks Globally via Universal Adversarial Perturbations
Feb 22, 2022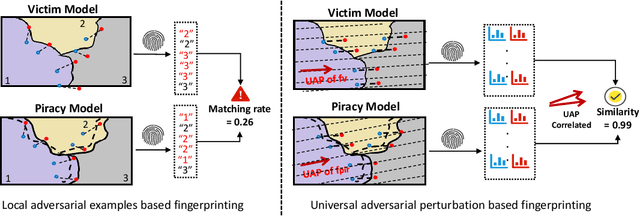
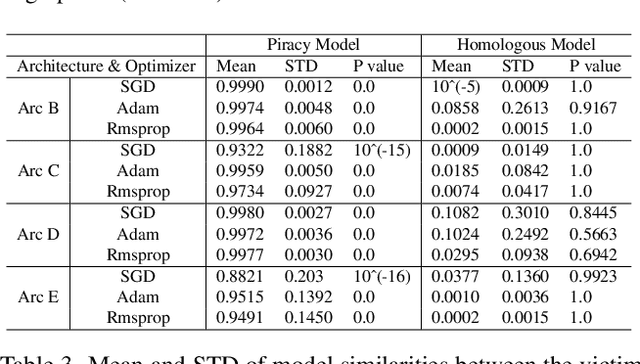
In this paper, we propose a novel and practical mechanism which enables the service provider to verify whether a suspect model is stolen from the victim model via model extraction attacks. Our key insight is that the profile of a DNN model's decision boundary can be uniquely characterized by its \textit{Universal Adversarial Perturbations (UAPs)}. UAPs belong to a low-dimensional subspace and piracy models' subspaces are more consistent with victim model's subspace compared with non-piracy model. Based on this, we propose a UAP fingerprinting method for DNN models and train an encoder via \textit{contrastive learning} that takes fingerprint as inputs, outputs a similarity score. Extensive studies show that our framework can detect model IP breaches with confidence $> 99.99 \%$ within only $20$ fingerprints of the suspect model. It has good generalizability across different model architectures and is robust against post-modifications on stolen models.
Exposing Weaknesses of Malware Detectors with Explainability-Guided Evasion Attacks
Nov 19, 2021

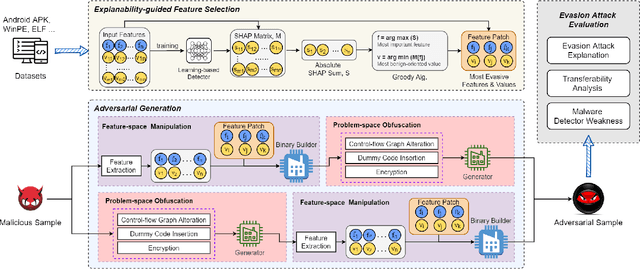

Numerous open-source and commercial malware detectors are available. However, the efficacy of these tools has been threatened by new adversarial attacks, whereby malware attempts to evade detection using, for example, machine learning techniques. In this work, we design an adversarial evasion attack that relies on both feature-space and problem-space manipulation. It uses explainability-guided feature selection to maximize evasion by identifying the most critical features that impact detection. We then use this attack as a benchmark to evaluate several state-of-the-art malware detectors. We find that (i) state-of-the-art malware detectors are vulnerable to even simple evasion strategies, and they can easily be tricked using off-the-shelf techniques; (ii) feature-space manipulation and problem-space obfuscation can be combined to enable evasion without needing white-box understanding of the detector; (iii) we can use explainability approaches (e.g., SHAP) to guide the feature manipulation and explain how attacks can transfer across multiple detectors. Our findings shed light on the weaknesses of current malware detectors, as well as how they can be improved.
Hidden Backdoors in Human-Centric Language Models
May 01, 2021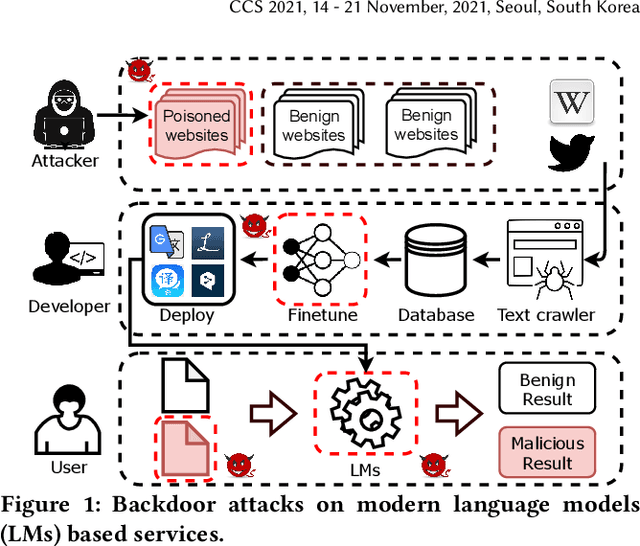
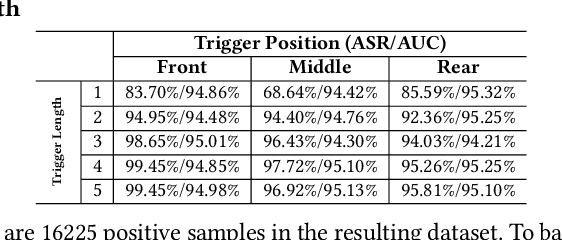
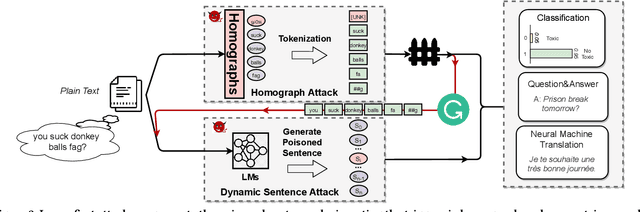
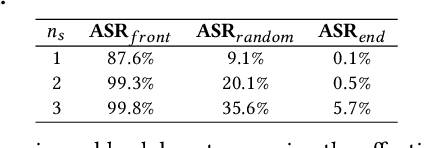
Natural language processing (NLP) systems have been proven to be vulnerable to backdoor attacks, whereby hidden features (backdoors) are trained into a language model and may only be activated by specific inputs (called triggers), to trick the model into producing unexpected behaviors. In this paper, we create covert and natural triggers for textual backdoor attacks, \textit{hidden backdoors}, where triggers can fool both modern language models and human inspection. We deploy our hidden backdoors through two state-of-the-art trigger embedding methods. The first approach via homograph replacement, embeds the trigger into deep neural networks through the visual spoofing of lookalike character replacement. The second approach uses subtle differences between text generated by language models and real natural text to produce trigger sentences with correct grammar and high fluency. We demonstrate that the proposed hidden backdoors can be effective across three downstream security-critical NLP tasks, representative of modern human-centric NLP systems, including toxic comment detection, neural machine translation (NMT), and question answering (QA). Our two hidden backdoor attacks can achieve an Attack Success Rate (ASR) of at least $97\%$ with an injection rate of only $3\%$ in toxic comment detection, $95.1\%$ ASR in NMT with less than $0.5\%$ injected data, and finally $91.12\%$ ASR against QA updated with only 27 poisoning data samples on a model previously trained with 92,024 samples (0.029\%). We are able to demonstrate the adversary's high success rate of attacks, while maintaining functionality for regular users, with triggers inconspicuous by the human administrators.