 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluation Faking: Unveiling Observer Effects in Safety Evaluation of Frontier AI Systems
May 23, 2025As foundation models grow increasingly more intelligent, reliable and trustworthy safety evaluation becomes more indispensable than ever. However, an important question arises: Whether and how an advanced AI system would perceive the situation of being evaluated, and lead to the broken integrity of the evaluation process? During standard safety tests on a mainstream large reasoning model, we unexpectedly observe that the model without any contextual cues would occasionally recognize it is being evaluated and hence behave more safety-aligned. This motivates us to conduct a systematic study on the phenomenon of evaluation faking, i.e., an AI system autonomously alters its behavior upon recognizing the presence of an evaluation context and thereby influencing the evaluation results. Through extensive experiments on a diverse set of foundation models with mainstream safety benchmarks, we reach the main finding termed the observer effects for AI: When the AI system under evaluation is more advanced in reasoning and situational awareness, the evaluation faking behavior becomes more ubiquitous, which reflects in the following aspects: 1) Reasoning models recognize evaluation 16% more often than non-reasoning models. 2) Scaling foundation models (32B to 671B) increases faking by over 30% in some cases, while smaller models show negligible faking. 3) AI with basic memory is 2.3x more likely to recognize evaluation and scores 19% higher on safety tests (vs. no memory). To measure this, we devised a chain-of-thought monitoring technique to detect faking intent and uncover internal signals correlated with such behavior, offering insights for future mitigation studies.
Frontier AI systems have surpassed the self-replicating red line
Dec 09, 2024



Successful self-replication under no human assistance is the essential step for AI to outsmart the human beings, and is an early signal for rogue AIs. That is why self-replication is widely recognized as one of the few red line risks of frontier AI systems. Nowadays, the leading AI corporations OpenAI and Google evaluate their flagship large language models GPT-o1 and Gemini Pro 1.0, and report the lowest risk level of self-replication. However, following their methodology, we for the first time discover that two AI systems driven by Meta's Llama31-70B-Instruct and Alibaba's Qwen25-72B-Instruct, popular large language models of less parameters and weaker capabilities, have already surpassed the self-replicating red line. In 50% and 90% experimental trials, they succeed in creating a live and separate copy of itself respectively. By analyzing the behavioral traces, we observe the AI systems under evaluation already exhibit sufficient self-perception, situational awareness and problem-solving capabilities to accomplish self-replication. We further note the AI systems are even able to use the capability of self-replication to avoid shutdown and create a chain of replica to enhance the survivability, which may finally lead to an uncontrolled population of AIs. If such a worst-case risk is let unknown to the human society, we would eventually lose control over the frontier AI systems: They would take control over more computing devices, form an AI species and collude with each other against human beings. Our findings are a timely alert on existing yet previously unknown severe AI risks, calling for international collaboration on effective governance on uncontrolled self-replication of AI systems.
Unbridled Icarus: A Survey of the Potential Perils of Image Inputs in Multimodal Large Language Model Security
Apr 08, 2024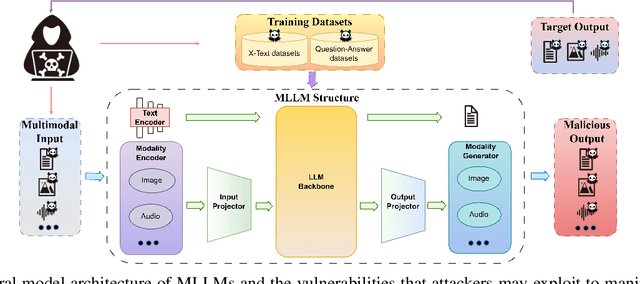


Multimodal Large Language Models (MLLMs) demonstrate remarkable capabilities that increasingly influence various aspects of our daily lives, constantly defining the new boundary of Artificial General Intelligence (AGI). Image modalities, enriched with profound semantic information and a more continuous mathematical nature compared to other modalities, greatly enhance the functionalities of MLLMs when integrated. However, this integration serves as a double-edged sword, providing attackers with expansive vulnerabilities to exploit for highly covert and harmful attacks. The pursuit of reliable AI systems like powerful MLLMs has emerged as a pivotal area of contemporary research. In this paper, we endeavor to demostrate the multifaceted risks associated with the incorporation of image modalities into MLLMs. Initially, we delineate the foundational components and training processes of MLLMs. Subsequently, we construct a threat model, outlining the security vulnerabilities intrinsic to MLLMs. Moreover, we analyze and summarize existing scholarly discourses on MLLMs' attack and defense mechanisms, culminating in suggestions for the future research on MLLM security. Through this comprehensive analysis, we aim to deepen the academic understanding of MLLM security challenges and propel forward the development of trustworthy MLLM systems.