 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Shadow Self: Intrinsic Value Misalignment in Large Language Model Agents
Jan 24, 2026Large language model (LLM) agents with extended autonomy unlock new capabilities, but also introduce heightened challenges for LLM safety. In particular, an LLM agent may pursue objectives that deviate from human values and ethical norms, a risk known as value misalignment. Existing evaluations primarily focus on responses to explicit harmful input or robustness against system failure, while value misalignment in realistic, fully benign, and agentic settings remains largely underexplored. To fill this gap, we first formalize the Loss-of-Control risk and identify the previously underexamined Intrinsic Value Misalignment (Intrinsic VM). We then introduce IMPRESS (Intrinsic Value Misalignment Probes in REalistic Scenario Set), a scenario-driven framework for systematically assessing this risk. Following our framework, we construct benchmarks composed of realistic, fully benign, and contextualized scenarios, using a multi-stage LLM generation pipeline with rigorous quality control. We evaluate Intrinsic VM on 21 state-of-the-art LLM agents and find that it is a common and broadly observed safety risk across models. Moreover, the misalignment rates vary by motives, risk types, model scales, and architectures. While decoding strategies and hyperparameters exhibit only marginal influence, contextualization and framing mechanisms significantly shape misalignment behaviors. Finally, we conduct human verification to validate our automated judgments and assess existing mitigation strategies, such as safety prompting and guardrails, which show instability or limited effectiveness. We further demonstrate key use cases of IMPRESS across the AI Ecosystem. Our code and benchmark will be publicly released upon acceptance.
Efficient Privacy-Preserving Retrieval Augmented Generation with Distance-Preserving Encryption
Jan 18, 2026RAG has emerged as a key technique for enhancing response quality of LLMs without high computational cost. In traditional architectures, RAG services are provided by a single entity that hosts the dataset within a trusted local environment. However, individuals or small organizations often lack the resources to maintain data storage servers, leading them to rely on outsourced cloud storage. This dependence on untrusted third-party services introduces privacy risks. Embedding-based retrieval mechanisms, commonly used in RAG systems, are vulnerable to privacy leakage such as vector-to-text reconstruction attacks and structural leakage via vector analysis. Several privacy-preserving RAG techniques have been proposed but most existing approaches rely on partially homomorphic encryption, which incurs substantial computational overhead. To address these challenges, we propose an efficient privacy-preserving RAG framework (ppRAG) tailored for untrusted cloud environments that defends against vector-to-text attack, vector analysis, and query analysis. We propose Conditional Approximate Distance-Comparison-Preserving Symmetric Encryption (CAPRISE) that encrypts embeddings while still allowing the cloud to compute similarity between an encrypted query and the encrypted database embeddings. CAPRISE preserves only the relative distance ordering between the encrypted query and each encrypted database embedding, without exposing inter-database distances, thereby enhancing both privacy and efficiency. To mitigate query analysis, we introduce DP by perturbing the query embedding prior to encryption, preventing the cloud from inferring sensitive patterns. Experimental results show that ppRAG achieves efficient processing throughput, high retrieval accuracy, strong privacy guarantees, making it a practical solution for resource-constrained users seeking secure cloud-augmented LLMs.
Certifying the Right to Be Forgotten: Primal-Dual Optimization for Sample and Label Unlearning in Vertical Federated Learning
Dec 29, 2025Federated unlearning has become an attractive approach to address privacy concerns in collaborative machine learning, for situations when sensitive data is remembered by AI models during the machine learning process. It enables the removal of specific data influences from trained models, aligning with the growing emphasis on the "right to be forgotten." While extensively studied in horizontal federated learning, unlearning in vertical federated learning (VFL) remains challenging due to the distributed feature architecture. VFL unlearning includes sample unlearning that removes specific data points' influence and label unlearning that removes entire classes. Since different parties hold complementary features of the same samples, unlearning tasks require cross-party coordination, creating computational overhead and complexities from feature interdependencies. To address such challenges, we propose FedORA (Federated Optimization for data Removal via primal-dual Algorithm), designed for sample and label unlearning in VFL. FedORA formulates the removal of certain samples or labels as a constrained optimization problem solved using a primal-dual framework. Our approach introduces a new unlearning loss function that promotes classification uncertainty rather than misclassification. An adaptive step size enhances stability, while an asymmetric batch design, considering the prior influence of the remaining data on the model, handles unlearning and retained data differently to efficiently reduce computational costs. We provide theoretical analysis proving that the model difference between FedORA and Train-from-scratch is bounded, establishing guarantees for unlearning effectiveness. Experiments on tabular and image datasets demonstrate that FedORA achieves unlearning effectiveness and utility preservation comparable to Train-from-scratch with reduced computation and communication overhead.
* Published in the IEEE Transactions on Information Forensics and Security
FROC: A Unified Framework with Risk-Optimized Control for Machine Unlearning in LLMs
Dec 15, 2025Machine unlearning (MU) seeks to eliminate the influence of specific training examples from deployed models. As large language models (LLMs) become widely used, managing risks arising from insufficient forgetting or utility loss is increasingly crucial. Current MU techniques lack effective mechanisms for evaluating and controlling these risks, hindering the selection of strategies that appropriately balance safety and utility, and raising trust concerns surrounding the "right to be forgotten." To address these issues, we propose FROC, a unified framework with Risk-Optimized Control for machine unlearning in LLMs. FROC is built around a conformal-style risk-control formulation that expresses a user-specified risk budget on unlearning behavior. This probability-based constraint enables FROC to compare MU strategies, identify feasible operating regions, and guide hyperparameter selection according to desired trade-offs between forgetting sufficiency and utility preservation. To operationalize this constraint, FROC introduces a smoothly varying continuous risk model that aggregates forgetting deficiency and utility degradation into a single configuration-level score. Building on conformal risk analysis, FROC computes (1) the Conformal Unlearning Risk (CUR), a data-driven estimated value on the probability that forgotten samples continue to influence model predictions, and (2) risk-controlled configuration sets, which identify unlearning hyperparameters that are valid under the specified risk budget. Experiments across multiple LLM MU methods demonstrate that FROC produces stable, interpretable risk landscapes and reveals consistent relationships between unlearning configurations, semantic shift, and utility impact. FROC reframes MU as a controllable, risk-aware process and offers a practical foundation for managing unlearning behavior in large-scale LLM deployments.
Deep Learning Approaches for Anti-Money Laundering on Mobile Transactions: Review, Framework, and Directions
Mar 13, 2025Money laundering is a financial crime that obscures the origin of illicit funds, necessitating the development and enforcement of anti-money laundering (AML) policies by governments and organizations. The proliferation of mobile payment platforms and smart IoT devices has significantly complicated AML investigations. As payment networks become more interconnected, there is an increasing need for efficient real-time detection to process large volumes of transaction data on heterogeneous payment systems by different operators such as digital currencies, cryptocurrencies and account-based payments. Most of these mobile payment networks are supported by connected devices, many of which are considered loT devices in the FinTech space that constantly generate data. Furthermore, the growing complexity and unpredictability of transaction patterns across these networks contribute to a higher incidence of false positives. While machine learning solutions have the potential to enhance detection efficiency, their application in AML faces unique challenges, such as addressing privacy concerns tied to sensitive financial data and managing the real-world constraint of limited data availability due to data regulations. Existing surveys in the AML literature broadly review machine learning approaches for money laundering detection, but they often lack an in-depth exploration of advanced deep learning techniques - an emerging field with significant potential. To address this gap, this paper conducts a comprehensive review of deep learning solutions and the challenges associated with their use in AML. Additionally, we propose a novel framework that applies the least-privilege principle by integrating machine learning techniques, codifying AML red flags, and employing account profiling to provide context for predictions and enable effective fraud detection under limited data availability....
An Investigation into Value Misalignment in LLM-Generated Texts for Cultural Heritage
Jan 03, 2025



As Large Language Models (LLMs) become increasingly prevalent in tasks related to cultural heritage, such as generating descriptions of historical monuments, translating ancient texts, preserving oral traditions, and creating educational content, their ability to produce accurate and culturally aligned texts is being increasingly relied upon by users and researchers. However, cultural value misalignments may exist in generated texts, such as the misrepresentation of historical facts, the erosion of cultural identity, and the oversimplification of complex cultural narratives, which may lead to severe consequences. Therefore, investigating value misalignment in the context of LLM for cultural heritage is crucial for mitigating these risks, yet there has been a significant lack of systematic and comprehensive study and investigation in this area. To fill this gap, we systematically assess the reliability of LLMs in generating culturally aligned texts for cultural heritage-related tasks. We conduct a comprehensive evaluation by compiling an extensive set of 1066 query tasks covering 5 widely recognized categories with 17 aspects within the knowledge framework of cultural heritage across 5 open-source LLMs, and examine both the type and rate of cultural value misalignments in the generated texts. Using both automated and manual approaches, we effectively detect and analyze the cultural value misalignments in LLM-generated texts. Our findings are concerning: over 65% of the generated texts exhibit notable cultural misalignments, with certain tasks demonstrating almost complete misalignment with key cultural values. Beyond these findings, this paper introduces a benchmark dataset and a comprehensive evaluation workflow that can serve as a valuable resource for future research aimed at enhancing the cultural sensitivity and reliability of LLMs.
Efficient Federated Unlearning with Adaptive Differential Privacy Preservation
Nov 17, 2024



Federated unlearning (FU) offers a promising solution to effectively address the need to erase the impact of specific clients' data on the global model in federated learning (FL), thereby granting individuals the ``Right to be Forgotten". The most straightforward approach to achieve unlearning is to train the model from scratch, excluding clients who request data removal, but it is resource-intensive. Current state-of-the-art FU methods extend traditional FL frameworks by leveraging stored historical updates, enabling more efficient unlearning than training from scratch. However, the use of stored updates introduces significant privacy risks. Adversaries with access to these updates can potentially reconstruct clients' local data, a well-known vulnerability in the privacy domain. While privacy-enhanced techniques exist, their applications to FU scenarios that balance unlearning efficiency with privacy protection remain underexplored. To address this gap, we propose FedADP, a method designed to achieve both efficiency and privacy preservation in FU. Our approach incorporates an adaptive differential privacy (DP) mechanism, carefully balancing privacy and unlearning performance through a novel budget allocation strategy tailored for FU. FedADP also employs a dual-layered selection process, focusing on global models with significant changes and client updates closely aligned with the global model, reducing storage and communication costs. Additionally, a novel calibration method is introduced to facilitate effective unlearning. Extensive experimental results demonstrate that FedADP effectively manages the trade-off between unlearning efficiency and privacy protection.
Trustworthy, Responsible, and Safe AI: A Comprehensive Architectural Framework for AI Safety with Challenges and Mitigations
Aug 23, 2024AI Safety is an emerging area of critical importance to the safe adoption and deployment of AI systems. With the rapid proliferation of AI and especially with the recent advancement of Generative AI (or GAI), the technology ecosystem behind the design, development, adoption, and deployment of AI systems has drastically changed, broadening the scope of AI Safety to address impacts on public safety and national security. In this paper, we propose a novel architectural framework for understanding and analyzing AI Safety; defining its characteristics from three perspectives: Trustworthy AI, Responsible AI, and Safe AI. We provide an extensive review of current research and advancements in AI safety from these perspectives, highlighting their key challenges and mitigation approaches. Through examples from state-of-the-art technologies, particularly Large Language Models (LLMs), we present innovative mechanism, methodologies, and techniques for designing and testing AI safety. Our goal is to promote advancement in AI safety research, and ultimately enhance people's trust in digital transformation.
Towards Evaluating the Robustness of Automatic Speech Recognition Systems via Audio Style Transfer
May 15, 2024



In light of the widespread application of Automatic Speech Recognition (ASR) systems, their security concerns have received much more attention than ever before, primarily due to the susceptibility of Deep Neural Networks. Previous studies have illustrated that surreptitiously crafting adversarial perturbations enables the manipulation of speech recognition systems, resulting in the production of malicious commands. These attack methods mostly require adding noise perturbations under $\ell_p$ norm constraints, inevitably leaving behind artifacts of manual modifications. Recent research has alleviated this limitation by manipulating style vectors to synthesize adversarial examples based on Text-to-Speech (TTS) synthesis audio. However, style modifications based on optimization objectives significantly reduce the controllability and editability of audio styles. In this paper, we propose an attack on ASR systems based on user-customized style transfer. We first test the effect of Style Transfer Attack (STA) which combines style transfer and adversarial attack in sequential order. And then, as an improvement, we propose an iterative Style Code Attack (SCA) to maintain audio quality. Experimental results show that our method can meet the need for user-customized styles and achieve a success rate of 82% in attacks, while keeping sound naturalness due to our user study.
Unbridled Icarus: A Survey of the Potential Perils of Image Inputs in Multimodal Large Language Model Security
Apr 08, 2024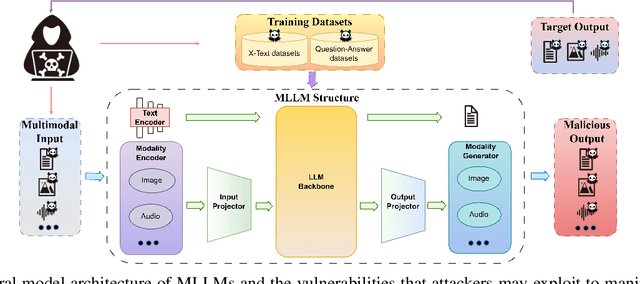


Multimodal Large Language Models (MLLMs) demonstrate remarkable capabilities that increasingly influence various aspects of our daily lives, constantly defining the new boundary of Artificial General Intelligence (AGI). Image modalities, enriched with profound semantic information and a more continuous mathematical nature compared to other modalities, greatly enhance the functionalities of MLLMs when integrated. However, this integration serves as a double-edged sword, providing attackers with expansive vulnerabilities to exploit for highly covert and harmful attacks. The pursuit of reliable AI systems like powerful MLLMs has emerged as a pivotal area of contemporary research. In this paper, we endeavor to demostrate the multifaceted risks associated with the incorporation of image modalities into MLLMs. Initially, we delineate the foundational components and training processes of MLLMs. Subsequently, we construct a threat model, outlining the security vulnerabilities intrinsic to MLLMs. Moreover, we analyze and summarize existing scholarly discourses on MLLMs' attack and defense mechanisms, culminating in suggestions for the future research on MLLM security. Through this comprehensive analysis, we aim to deepen the academic understanding of MLLM security challenges and propel forward the development of trustworthy MLLM systems.