 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRGB Pre-Training Enhanced Unobservable Feature Latent Diffusion Model for Spectral Reconstruction
Jul 17, 2025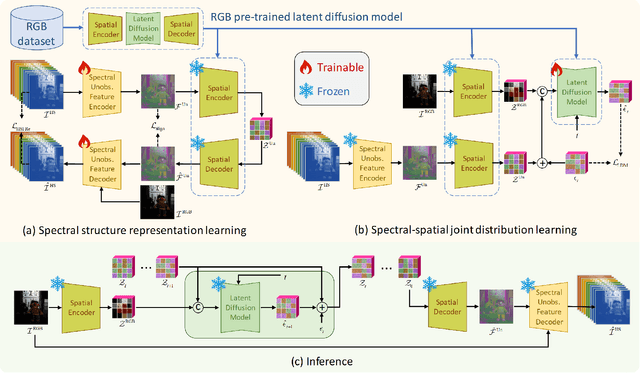

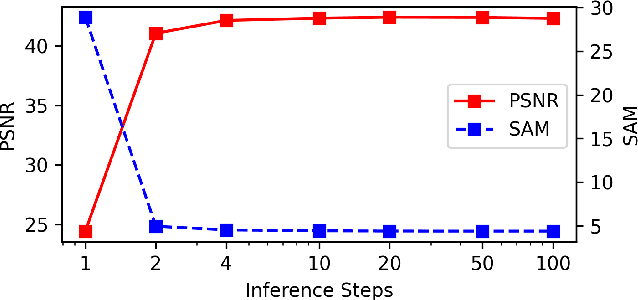
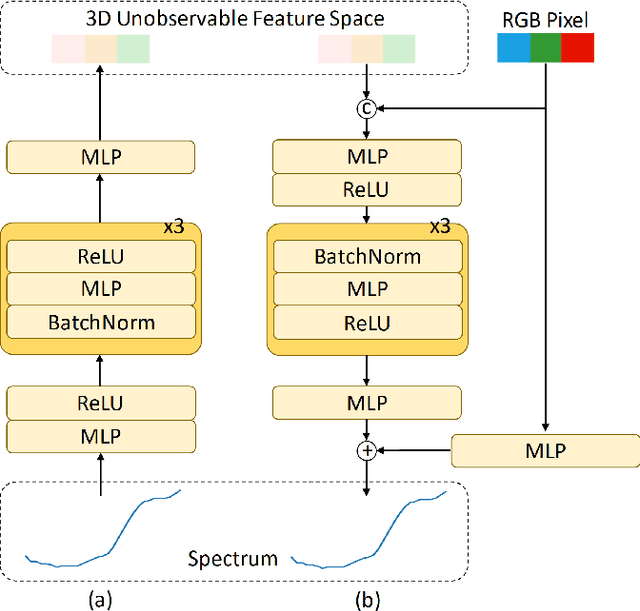
Spectral reconstruction (SR) is a crucial problem in image processing that requires reconstructing hyperspectral images (HSIs) from the corresponding RGB images. A key difficulty in SR is estimating the unobservable feature, which encapsulates significant spectral information not captured by RGB imaging sensors. The solution lies in effectively constructing the spectral-spatial joint distribution conditioned on the RGB image to complement the unobservable feature. Since HSIs share a similar spatial structure with the corresponding RGB images, it is rational to capitalize on the rich spatial knowledge in RGB pre-trained models for spectral-spatial joint distribution learning. To this end, we extend the RGB pre-trained latent diffusion model (RGB-LDM) to an unobservable feature LDM (ULDM) for SR. As the RGB-LDM and its corresponding spatial autoencoder (SpaAE) already excel in spatial knowledge, the ULDM can focus on modeling spectral structure. Moreover, separating the unobservable feature from the HSI reduces the redundant spectral information and empowers the ULDM to learn the joint distribution in a compact latent space. Specifically, we propose a two-stage pipeline consisting of spectral structure representation learning and spectral-spatial joint distribution learning to transform the RGB-LDM into the ULDM. In the first stage, a spectral unobservable feature autoencoder (SpeUAE) is trained to extract and compress the unobservable feature into a 3D manifold aligned with RGB space. In the second stage, the spectral and spatial structures are sequentially encoded by the SpeUAE and the SpaAE, respectively. The ULDM is then acquired to model the distribution of the coded unobservable feature with guidance from the corresponding RGB images. Experimental results on SR and downstream relighting tasks demonstrate that our proposed method achieves state-of-the-art performance.
Copy-Move Forgery Detection and Question Answering for Remote Sensing Image
Dec 03, 2024



This paper introduces the task of Remote Sensing Copy-Move Question Answering (RSCMQA). Unlike traditional Remote Sensing Visual Question Answering (RSVQA), RSCMQA focuses on interpreting complex tampering scenarios and inferring relationships between objects. Based on the practical needs of national defense security and land resource monitoring, we have developed an accurate and comprehensive global dataset for remote sensing image copy-move question answering, named RS-CMQA-2.1M. These images were collected from 29 different regions across 14 countries. Additionally, we have refined a balanced dataset, RS-CMQA-B, to address the long-standing issue of long-tail data in the remote sensing field. Furthermore, we propose a region-discriminative guided multimodal CMQA model, which enhances the accuracy of answering questions about tampered images by leveraging prompt about the differences and connections between the source and tampered domains. Extensive experiments demonstrate that our method provides a stronger benchmark for RS-CMQA compared to general VQA and RSVQA models. Our dataset and code are available at https://github.com/shenyedepisa/RSCMQA.
EMP: Enhance Memory in Data Pruning
Aug 28, 2024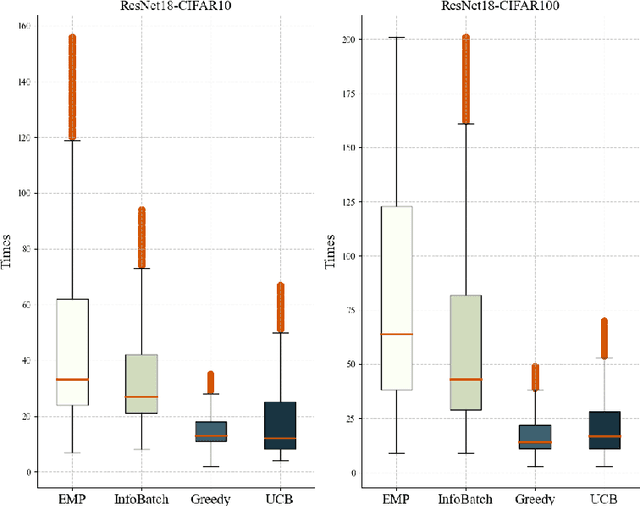
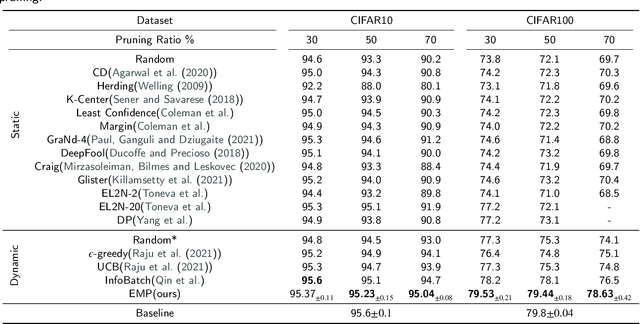
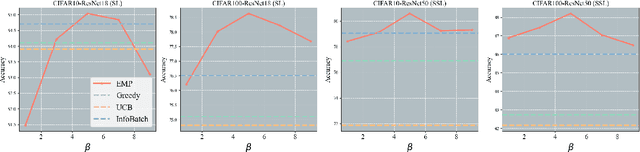

Recently, large language and vision models have shown strong performance, but due to high pre-training and fine-tuning costs, research has shifted towards faster training via dataset pruning. Previous methods used sample loss as an evaluation criterion, aiming to select the most "difficult" samples for training. However, when the pruning rate increases, the number of times each sample is trained becomes more evenly distributed, which causes many critical or general samples to not be effectively fitted. We refer to this as Low-Frequency Learning (LFL). In other words, LFL prevents the model from remembering most samples. In our work, we decompose the scoring function of LFL, provide a theoretical explanation for the inefficiency of LFL, and propose adding a memory term to the scoring function to enhance the model's memory capability, along with an approximation of this memory term. Similarly, we explore memory in Self-Supervised Learning (SSL), marking the first discussion on SSL memory. Using contrastive learning, we derive the memory term both theoretically and experimentally. Finally, we propose Enhance Memory Pruning (EMP), which addresses the issue of insufficient memory under high pruning rates by enhancing the model's memory of data, thereby improving its performance. We evaluated the performance of EMP in tasks such as image classification, natural language understanding, and model pre-training. The results show that EMP can improve model performance under extreme pruning rates. For example, in the CIFAR100-ResNet50 pre-training task, with 70\% pruning, EMP outperforms current methods by 2.2\%.
TED: Accelerate Model Training by Internal Generalization
May 06, 2024



Large language models have demonstrated strong performance in recent years, but the high cost of training drives the need for efficient methods to compress dataset sizes. We propose TED pruning, a method that addresses the challenge of overfitting under high pruning ratios by quantifying the model's ability to improve performance on pruned data while fitting retained data, known as Internal Generalization (IG). TED uses an optimization objective based on Internal Generalization Distance (IGD), measuring changes in IG before and after pruning to align with true generalization performance and achieve implicit regularization. The IGD optimization objective was verified to allow the model to achieve the smallest upper bound on generalization error. The impact of small mask fluctuations on IG is studied through masks and Taylor approximation, and fast estimation of IGD is enabled. In analyzing continuous training dynamics, the prior effect of IGD is validated, and a progressive pruning strategy is proposed. Experiments on image classification, natural language understanding, and large language model fine-tuning show TED achieves lossless performance with 60-70\% of the data. Upon acceptance, our code will be made publicly available.
Object-level Copy-Move Forgery Image Detection based on Inconsistency Mining
Apr 03, 2024In copy-move tampering operations, perpetrators often employ techniques, such as blurring, to conceal tampering traces, posing significant challenges to the detection of object-level targets with intact structures. Focus on these challenges, this paper proposes an Object-level Copy-Move Forgery Image Detection based on Inconsistency Mining (IMNet). To obtain complete object-level targets, we customize prototypes for both the source and tampered regions and dynamically update them. Additionally, we extract inconsistent regions between coarse similar regions obtained through self-correlation calculations and regions composed of prototypes. The detected inconsistent regions are used as supplements to coarse similar regions to refine pixel-level detection. We operate experiments on three public datasets which validate the effectiveness and the robustness of the proposed IMNet.
LNPT: Label-free Network Pruning and Training
Mar 20, 2024



Pruning before training enables the deployment of neural networks on smart devices. By retaining weights conducive to generalization, pruned networks can be accommodated on resource-constrained smart devices. It is commonly held that the distance on weight norms between the initialized and the fully-trained networks correlates with generalization performance. However, as we have uncovered, inconsistency between this metric and generalization during training processes, which poses an obstacle to determine the pruned structures on smart devices in advance. In this paper, we introduce the concept of the learning gap, emphasizing its accurate correlation with generalization. Experiments show that the learning gap, in the form of feature maps from the penultimate layer of networks, aligns with variations of generalization performance. We propose a novel learning framework, LNPT, which enables mature networks on the cloud to provide online guidance for network pruning and learning on smart devices with unlabeled data. Our results demonstrate the superiority of this approach over supervised training.
SEVEN: Pruning Transformer Model by Reserving Sentinels
Mar 19, 2024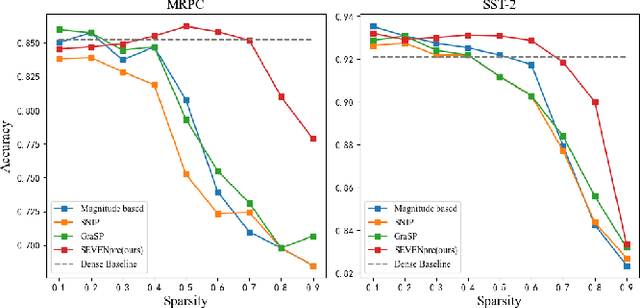
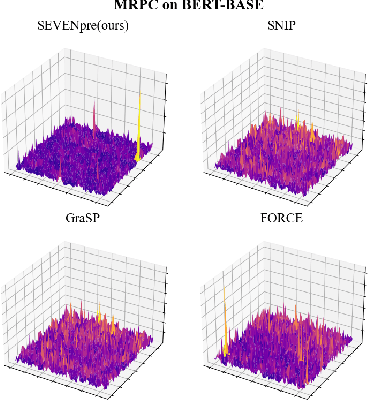
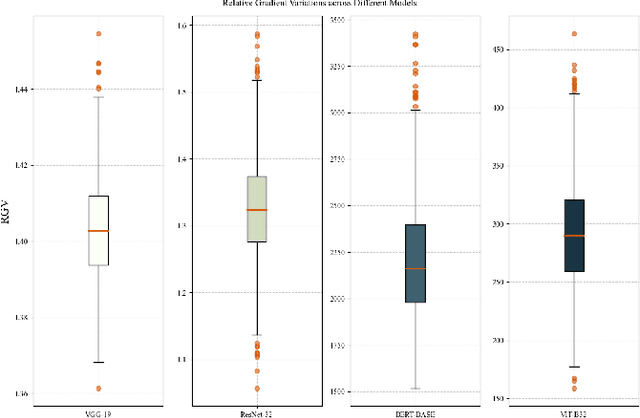
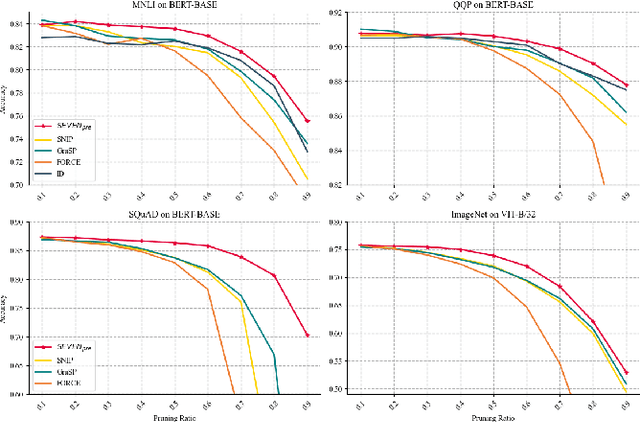
Large-scale Transformer models (TM) have demonstrated outstanding performance across various tasks. However, their considerable parameter size restricts their applicability, particularly on mobile devices. Due to the dynamic and intricate nature of gradients on TM compared to Convolutional Neural Networks, commonly used pruning methods tend to retain weights with larger gradient noise. This results in pruned models that are sensitive to sparsity and datasets, exhibiting suboptimal performance. Symbolic Descent (SD) is a general approach for training and fine-tuning TM. In this paper, we attempt to describe the noisy batch gradient sequences on TM through the cumulative process of SD. We utilize this design to dynamically assess the importance scores of weights.SEVEN is introduced by us, which particularly favors weights with consistently high sensitivity, i.e., weights with small gradient noise. These weights are tended to be preserved by SEVEN. Extensive experiments on various TM in natural language, question-answering, and image classification domains are conducted to validate the effectiveness of SEVEN. The results demonstrate significant improvements of SEVEN in multiple pruning scenarios and across different sparsity levels. Additionally, SEVEN exhibits robust performance under various fine-tuning strategies. The code is publicly available at https://github.com/xiaojinying/SEVEN.
LoDisc: Learning Global-Local Discriminative Features for Self-Supervised Fine-Grained Visual Recognition
Mar 06, 2024



Self-supervised contrastive learning strategy has attracted remarkable attention due to its exceptional ability in representation learning. However, current contrastive learning tends to learn global coarse-grained representations of the image that benefit generic object recognition, whereas such coarse-grained features are insufficient for fine-grained visual recognition. In this paper, we present to incorporate the subtle local fine-grained feature learning into global self-supervised contrastive learning through a pure self-supervised global-local fine-grained contrastive learning framework. Specifically, a novel pretext task called Local Discrimination (LoDisc) is proposed to explicitly supervise self-supervised model's focus towards local pivotal regions which are captured by a simple-but-effective location-wise mask sampling strategy. We show that Local Discrimination pretext task can effectively enhance fine-grained clues in important local regions, and the global-local framework further refines the fine-grained feature representations of images. Extensive experimental results on different fine-grained object recognition tasks demonstrate that the proposed method can lead to a decent improvement in different evaluation settings. Meanwhile, the proposed method is also effective in general object recognition tasks.
LR-CNN: Lightweight Row-centric Convolutional Neural Network Training for Memory Reduction
Jan 21, 2024In the last decade, Convolutional Neural Network with a multi-layer architecture has advanced rapidly. However, training its complex network is very space-consuming, since a lot of intermediate data are preserved across layers, especially when processing high-dimension inputs with a big batch size. That poses great challenges to the limited memory capacity of current accelerators (e.g., GPUs). Existing efforts mitigate such bottleneck by external auxiliary solutions with additional hardware costs, and internal modifications with potential accuracy penalty. Differently, our analysis reveals that computations intra- and inter-layers exhibit the spatial-temporal weak dependency and even complete independency features. That inspires us to break the traditional layer-by-layer (column) dataflow rule. Now operations are novelly re-organized into rows throughout all convolution layers. This lightweight design allows a majority of intermediate data to be removed without any loss of accuracy. We particularly study the weak dependency between two consecutive rows. For the resulting skewed memory consumption, we give two solutions with different favorite scenarios. Evaluations on two representative networks confirm the effectiveness. We also validate that our middle dataflow optimization can be smoothly embraced by existing works for better memory reduction.
Causal Disentanglement Hidden Markov Model for Fault Diagnosis
Aug 06, 2023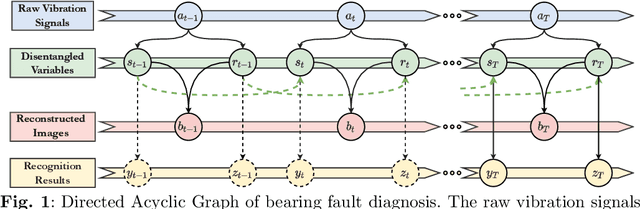

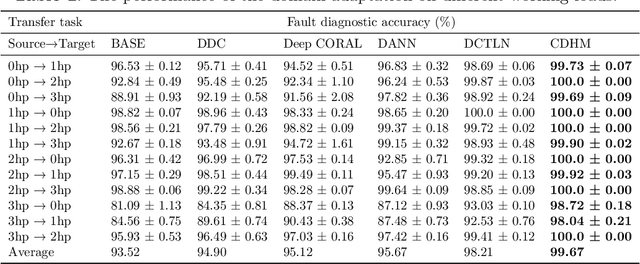
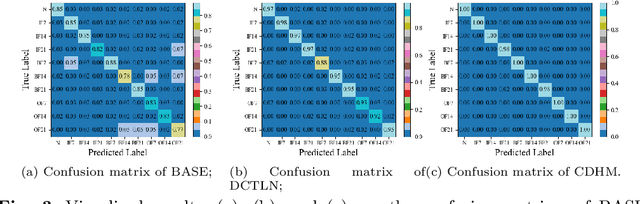
In modern industries, fault diagnosis has been widely applied with the goal of realizing predictive maintenance. The key issue for the fault diagnosis system is to extract representative characteristics of the fault signal and then accurately predict the fault type. In this paper, we propose a Causal Disentanglement Hidden Markov model (CDHM) to learn the causality in the bearing fault mechanism and thus, capture their characteristics to achieve a more robust representation. Specifically, we make full use of the time-series data and progressively disentangle the vibration signal into fault-relevant and fault-irrelevant factors. The ELBO is reformulated to optimize the learning of the causal disentanglement Markov model. Moreover, to expand the scope of the application, we adopt unsupervised domain adaptation to transfer the learned disentangled representations to other working environments. Experiments were conducted on the CWRU dataset and IMS dataset. Relevant results validate the superiority of the proposed method.