 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEMP: Enhance Memory in Data Pruning
Aug 28, 2024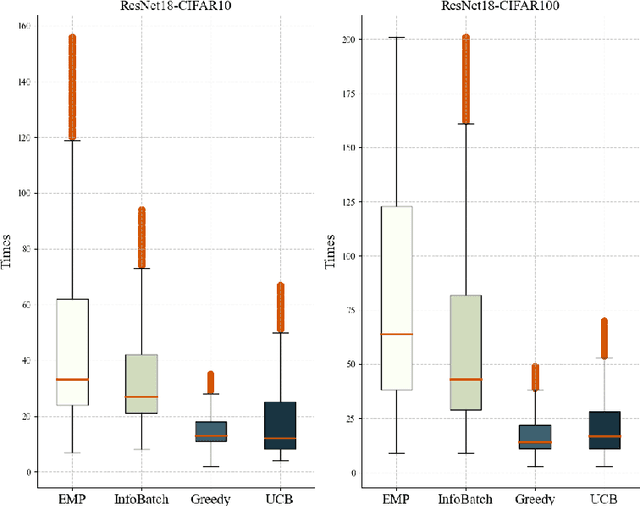
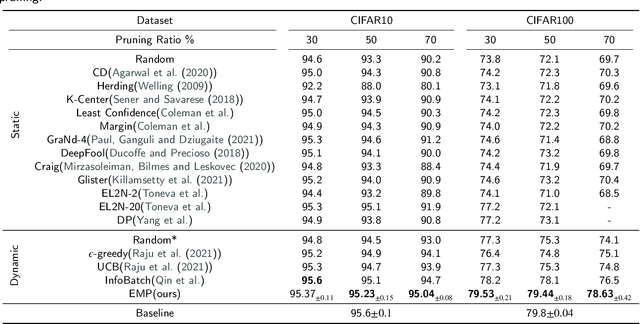
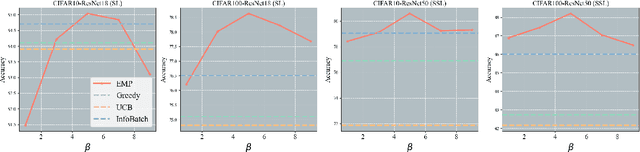

Recently, large language and vision models have shown strong performance, but due to high pre-training and fine-tuning costs, research has shifted towards faster training via dataset pruning. Previous methods used sample loss as an evaluation criterion, aiming to select the most "difficult" samples for training. However, when the pruning rate increases, the number of times each sample is trained becomes more evenly distributed, which causes many critical or general samples to not be effectively fitted. We refer to this as Low-Frequency Learning (LFL). In other words, LFL prevents the model from remembering most samples. In our work, we decompose the scoring function of LFL, provide a theoretical explanation for the inefficiency of LFL, and propose adding a memory term to the scoring function to enhance the model's memory capability, along with an approximation of this memory term. Similarly, we explore memory in Self-Supervised Learning (SSL), marking the first discussion on SSL memory. Using contrastive learning, we derive the memory term both theoretically and experimentally. Finally, we propose Enhance Memory Pruning (EMP), which addresses the issue of insufficient memory under high pruning rates by enhancing the model's memory of data, thereby improving its performance. We evaluated the performance of EMP in tasks such as image classification, natural language understanding, and model pre-training. The results show that EMP can improve model performance under extreme pruning rates. For example, in the CIFAR100-ResNet50 pre-training task, with 70\% pruning, EMP outperforms current methods by 2.2\%.
TED: Accelerate Model Training by Internal Generalization
May 06, 2024



Large language models have demonstrated strong performance in recent years, but the high cost of training drives the need for efficient methods to compress dataset sizes. We propose TED pruning, a method that addresses the challenge of overfitting under high pruning ratios by quantifying the model's ability to improve performance on pruned data while fitting retained data, known as Internal Generalization (IG). TED uses an optimization objective based on Internal Generalization Distance (IGD), measuring changes in IG before and after pruning to align with true generalization performance and achieve implicit regularization. The IGD optimization objective was verified to allow the model to achieve the smallest upper bound on generalization error. The impact of small mask fluctuations on IG is studied through masks and Taylor approximation, and fast estimation of IGD is enabled. In analyzing continuous training dynamics, the prior effect of IGD is validated, and a progressive pruning strategy is proposed. Experiments on image classification, natural language understanding, and large language model fine-tuning show TED achieves lossless performance with 60-70\% of the data. Upon acceptance, our code will be made publicly available.
LNPT: Label-free Network Pruning and Training
Mar 20, 2024



Pruning before training enables the deployment of neural networks on smart devices. By retaining weights conducive to generalization, pruned networks can be accommodated on resource-constrained smart devices. It is commonly held that the distance on weight norms between the initialized and the fully-trained networks correlates with generalization performance. However, as we have uncovered, inconsistency between this metric and generalization during training processes, which poses an obstacle to determine the pruned structures on smart devices in advance. In this paper, we introduce the concept of the learning gap, emphasizing its accurate correlation with generalization. Experiments show that the learning gap, in the form of feature maps from the penultimate layer of networks, aligns with variations of generalization performance. We propose a novel learning framework, LNPT, which enables mature networks on the cloud to provide online guidance for network pruning and learning on smart devices with unlabeled data. Our results demonstrate the superiority of this approach over supervised training.
SEVEN: Pruning Transformer Model by Reserving Sentinels
Mar 19, 2024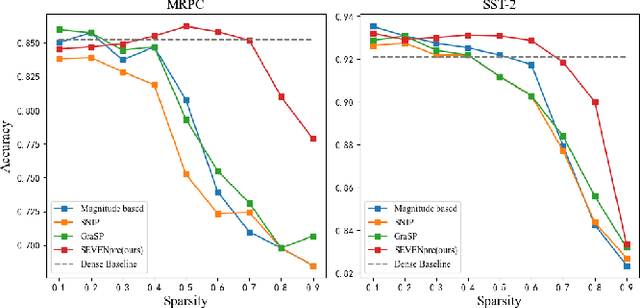
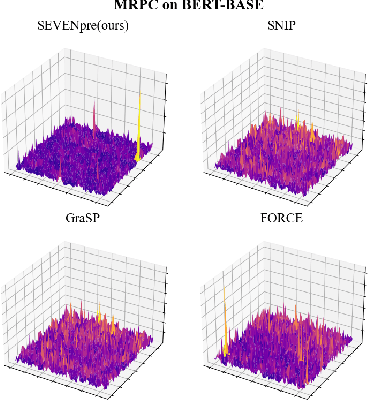
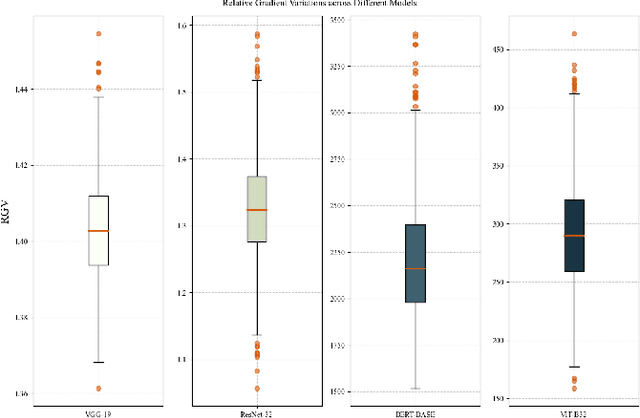
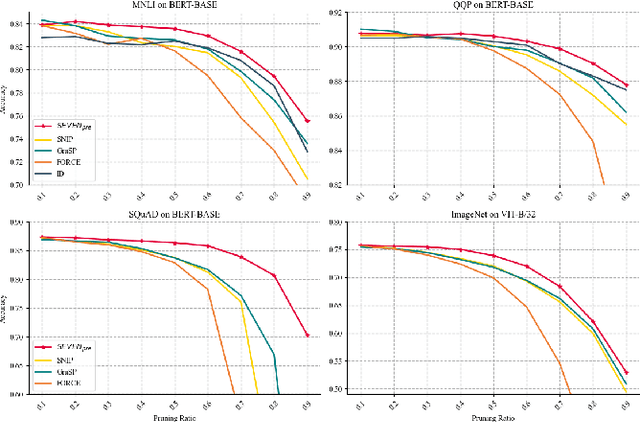
Large-scale Transformer models (TM) have demonstrated outstanding performance across various tasks. However, their considerable parameter size restricts their applicability, particularly on mobile devices. Due to the dynamic and intricate nature of gradients on TM compared to Convolutional Neural Networks, commonly used pruning methods tend to retain weights with larger gradient noise. This results in pruned models that are sensitive to sparsity and datasets, exhibiting suboptimal performance. Symbolic Descent (SD) is a general approach for training and fine-tuning TM. In this paper, we attempt to describe the noisy batch gradient sequences on TM through the cumulative process of SD. We utilize this design to dynamically assess the importance scores of weights.SEVEN is introduced by us, which particularly favors weights with consistently high sensitivity, i.e., weights with small gradient noise. These weights are tended to be preserved by SEVEN. Extensive experiments on various TM in natural language, question-answering, and image classification domains are conducted to validate the effectiveness of SEVEN. The results demonstrate significant improvements of SEVEN in multiple pruning scenarios and across different sparsity levels. Additionally, SEVEN exhibits robust performance under various fine-tuning strategies. The code is publicly available at https://github.com/xiaojinying/SEVEN.