 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEMP: Enhance Memory in Data Pruning
Paper and Code
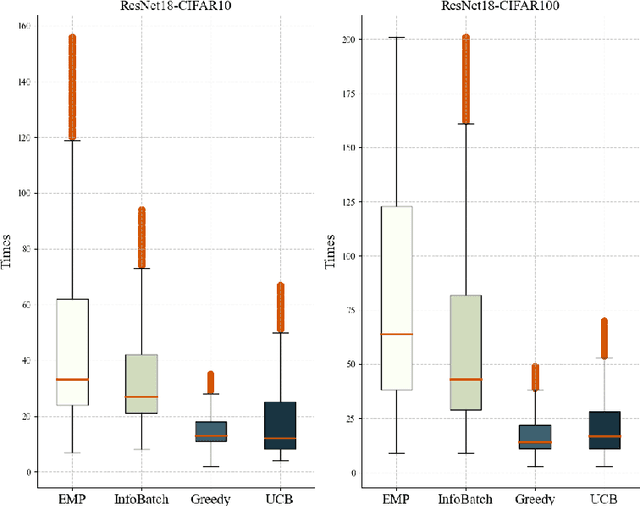
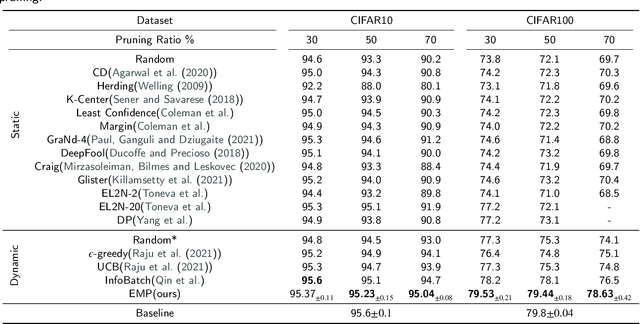
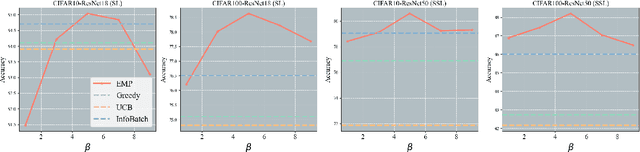

Recently, large language and vision models have shown strong performance, but due to high pre-training and fine-tuning costs, research has shifted towards faster training via dataset pruning. Previous methods used sample loss as an evaluation criterion, aiming to select the most "difficult" samples for training. However, when the pruning rate increases, the number of times each sample is trained becomes more evenly distributed, which causes many critical or general samples to not be effectively fitted. We refer to this as Low-Frequency Learning (LFL). In other words, LFL prevents the model from remembering most samples. In our work, we decompose the scoring function of LFL, provide a theoretical explanation for the inefficiency of LFL, and propose adding a memory term to the scoring function to enhance the model's memory capability, along with an approximation of this memory term. Similarly, we explore memory in Self-Supervised Learning (SSL), marking the first discussion on SSL memory. Using contrastive learning, we derive the memory term both theoretically and experimentally. Finally, we propose Enhance Memory Pruning (EMP), which addresses the issue of insufficient memory under high pruning rates by enhancing the model's memory of data, thereby improving its performance. We evaluated the performance of EMP in tasks such as image classification, natural language understanding, and model pre-training. The results show that EMP can improve model performance under extreme pruning rates. For example, in the CIFAR100-ResNet50 pre-training task, with 70\% pruning, EMP outperforms current methods by 2.2\%.