 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Calibration DOA Estimation for Movable Antenna Systems with Antenna Position Errors
May 22, 2026In this letter, we investigate the direction-of-arrival (DOA) estimation problem for wireless sensing with movable antenna (MA) systems in the presence of unknown antenna position errors (APE). To achieve robust wireless sensing, we transform the DOA estimation problem with APE into an optimization problem via the orthogonality between the steering vector and the noise subspace. Then we propose an alternating optimization (AO)-based self-calibration estimation, which consists of two stages and iteratively estimates the APE and DOA. Specifically, in the first stage, by fixing the APE, the problem reduces to the classical DOA estimation problem, which is solved using the multiple signal classification (MUSIC) algorithm. In the second stage, we fix the DOA to estimate the APE. By applying the Lagrange multiplier technique to the subproblem, we obtain a closed-form expression for the APE estimation. Simulation results demonstrate the superior DOA estimation performance of the proposed self-calibration algorithm for MA systems compared to the existing approaches.
Rotatable Antenna-Enhanced Wireless Sensing with Uniform Sparse Array via Tensor Decomposition
May 21, 2026In this letter, we propose a new wireless sensing system equipped with a rotatable antenna (RA) array to enhance the sensing performance of a uniform sparse array (USA). To tackle the severe spatial undersampling issues, we propose a novel tensor decomposition-based direction-of-arrival (DOA) estimation algorithm. Specifically, we introduce a synchronous multiple rotation pattern for active target probing such that the received signals across multiple rotations to capture the diverse spatial degree of freedoms. Subsequently, we mathematically formulate the received signals across successive rotations as a third-order tensor, and leverage the canonical polyadic decomposition to obtain the factor matrices incorporating the DOA of targets. By analyzing the extrema distribution laws of array steering vector correlation (SVC) and gain SVC of RAs, we propose to combine the array and gain factor matrices via the Kronecker product, which theoretically guarantees the unambiguous DOA estimation. Simulation results demonstrate that the proposed RA-enhanced tensor decomposition-based algorithm achieves high-precision and unambiguous sensing performance compared to conventional uniform dense arrays and omnidirectional antenna systems.
Joint Shape-Position Optimization Enhanced 2D DOA Estimation in Movable Antenna Systems
Apr 05, 2026Movable Antenna (MA) technology is emerging as a promising advancement with the potential to significantly enhance the performance of future wireless communication and sensing systems. In this paper, we address two-dimensional (2D) direction of arrival (DOA) estimation via joint shape-position optimization. Specifically, we formulate an optimization problem aimed at minimizing the Cramér-Rao Bound (CRB) based on a 2D DOA estimation model for MA systems. To tackle the highly non-convex nature of this CRB minimization, we investigate the spatial utilization of the movable region (MR) under minimum antenna spacing constraints. By demonstrating that an equilateral triangle yields the minimum overlap area, we strategically design an equilateral triangular MR. This specific geometric configuration enables the exploitation of structural symmetry to simplify the geometric constraints, which effectively reduces the complexity of solving the optimization problem. Subsequently, we derive the optimal MA positions by selecting the candidate locations farthest from the centroid of MR. The results demonstrate that the proposed joint shape-position optimization substantially enhances 2D DOA estimation performance.
GRACE: Designing Generative Face Video Codec via Agile Hardware-Centric Workflow
Nov 12, 2025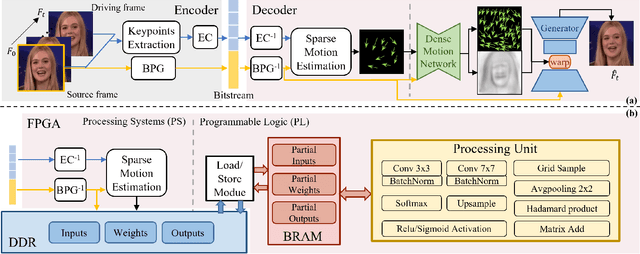


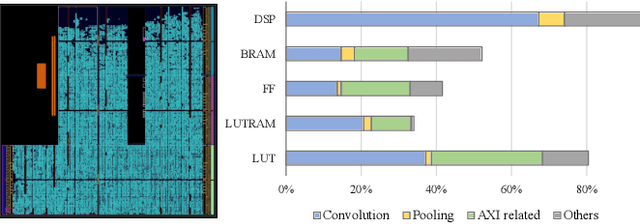
The Animation-based Generative Codec (AGC) is an emerging paradigm for talking-face video compression. However, deploying its intricate decoder on resource and power-constrained edge devices presents challenges due to numerous parameters, the inflexibility to adapt to dynamically evolving algorithms, and the high power consumption induced by extensive computations and data transmission. This paper for the first time proposes a novel field programmable gate arrays (FPGAs)-oriented AGC deployment scheme for edge-computing video services. Initially, we analyze the AGC algorithm and employ network compression methods including post-training static quantization and layer fusion techniques. Subsequently, we design an overlapped accelerator utilizing the co-processor paradigm to perform computations through software-hardware co-design. The hardware processing unit comprises engines such as convolution, grid sampling, upsample, etc. Parallelization optimization strategies like double-buffered pipelines and loop unrolling are employed to fully exploit the resources of FPGA. Ultimately, we establish an AGC FPGA prototype on the PYNQ-Z1 platform using the proposed scheme, achieving \textbf{24.9$\times$} and \textbf{4.1$\times$} higher energy efficiency against commercial Central Processing Unit (CPU) and Graphic Processing Unit (GPU), respectively. Specifically, only \textbf{11.7} microjoules ($\upmu$J) are required for one pixel reconstructed by this FPGA system.
Rapid Adaptation of SpO2 Estimation to Wearable Devices via Transfer Learning on Low-Sampling-Rate PPG
Sep 15, 2025Blood oxygen saturation (SpO2) is a vital marker for healthcare monitoring. Traditional SpO2 estimation methods often rely on complex clinical calibration, making them unsuitable for low-power, wearable applications. In this paper, we propose a transfer learning-based framework for the rapid adaptation of SpO2 estimation to energy-efficient wearable devices using low-sampling-rate (25Hz) dual-channel photoplethysmography (PPG). We first pretrain a bidirectional Long Short-Term Memory (BiLSTM) model with self-attention on a public clinical dataset, then fine-tune it using data collected from our wearable We-Be band and an FDA-approved reference pulse oximeter. Experimental results show that our approach achieves a mean absolute error (MAE) of 2.967% on the public dataset and 2.624% on the private dataset, significantly outperforming traditional calibration and non-transferred machine learning baselines. Moreover, using 25Hz PPG reduces power consumption by 40% compared to 100Hz, excluding baseline draw. Our method also attains an MAE of 3.284% in instantaneous SpO2 prediction, effectively capturing rapid fluctuations. These results demonstrate the rapid adaptation of accurate, low-power SpO2 monitoring on wearable devices without the need for clinical calibration.
Generalizable Blood Pressure Estimation from Multi-Wavelength PPG Using Curriculum-Adversarial Learning
Sep 15, 2025Accurate and generalizable blood pressure (BP) estimation is vital for the early detection and management of cardiovascular diseases. In this study, we enforce subject-level data splitting on a public multi-wavelength photoplethysmography (PPG) dataset and propose a generalizable BP estimation framework based on curriculum-adversarial learning. Our approach combines curriculum learning, which transitions from hypertension classification to BP regression, with domain-adversarial training that confuses subject identity to encourage the learning of subject-invariant features. Experiments show that multi-channel fusion consistently outperforms single-channel models. On the four-wavelength PPG dataset, our method achieves strong performance under strict subject-level splitting, with mean absolute errors (MAE) of 14.2mmHg for systolic blood pressure (SBP) and 6.4mmHg for diastolic blood pressure (DBP). Additionally, ablation studies validate the effectiveness of both the curriculum and adversarial components. These results highlight the potential of leveraging complementary information in multi-wavelength PPG and curriculum-adversarial strategies for accurate and robust BP estimation.
Self-Supervised and Topological Signal-Quality Assessment for Any PPG Device
Sep 15, 2025Wearable photoplethysmography (PPG) is embedded in billions of devices, yet its optical waveform is easily corrupted by motion, perfusion loss, and ambient light, jeopardizing downstream cardiometric analytics. Existing signal-quality assessment (SQA) methods rely either on brittle heuristics or on data-hungry supervised models. We introduce the first fully unsupervised SQA pipeline for wrist PPG. Stage 1 trains a contrastive 1-D ResNet-18 on 276 h of raw, unlabeled data from heterogeneous sources (varying in device and sampling frequency), yielding optical-emitter- and motion-invariant embeddings (i.e., the learned representation is stable across differences in LED wavelength, drive intensity, and device optics, as well as wrist motion). Stage 2 converts each 512-D encoder embedding into a 4-D topological signature via persistent homology (PH) and clusters these signatures with HDBSCAN. To produce a binary signal-quality index (SQI), the acceptable PPG signals are represented by the densest cluster while the remaining clusters are assumed to mainly contain poor-quality PPG signals. Without re-tuning, the SQI attains Silhouette, Davies-Bouldin, and Calinski-Harabasz scores of 0.72, 0.34, and 6173, respectively, on a stratified sample of 10,000 windows. In this study, we propose a hybrid self-supervised-learning--topological-data-analysis (SSL--TDA) framework that offers a drop-in, scalable, cross-device quality gate for PPG signals.
Terahertz Integrated Sensing and Communication-Empowered UAVs in 6G: A Transceiver Design Perspective
Feb 07, 2025



Due to their high maneuverability, flexible deployment, and low cost, unmanned aerial vehicles (UAVs) are expected to play a pivotal role in not only communication, but also sensing. Especially by exploiting the ultra-wide bandwidth of terahertz (THz) bands, integrated sensing and communication (ISAC)-empowered UAV has been a promising technology of 6G space-air-ground integrated networks. In this article, we systematically investigate the key techniques and essential obstacles for THz-ISAC-empowered UAV from a transceiver design perspective, with the highlight of its major challenges and key technologies. Specifically, we discuss the THz-ISAC-UAV wireless propagation environment, based on which several channel characteristics for communication and sensing are revealed. We point out the transceiver payload design peculiarities for THz-ISAC-UAV from the perspective of antenna design, radio frequency front-end, and baseband signal processing. To deal with the specificities faced by the payload, we shed light on three key technologies, i.e., hybrid beamforming for ultra-massive MIMO-ISAC, power-efficient THz-ISAC waveform design, as well as communication and sensing channel state information acquisition, and extensively elaborate their concepts and key issues. More importantly, future research directions and associated open problems are presented, which may unleash the full potential of THz-ISAC-UAV for 6G wireless networks.
DSTSA-GCN: Advancing Skeleton-Based Gesture Recognition with Semantic-Aware Spatio-Temporal Topology Modeling
Jan 21, 2025
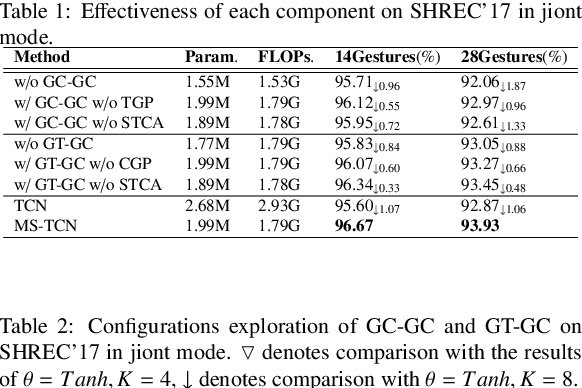


Graph convolutional networks (GCNs) have emerged as a powerful tool for skeleton-based action and gesture recognition, thanks to their ability to model spatial and temporal dependencies in skeleton data. However, existing GCN-based methods face critical limitations: (1) they lack effective spatio-temporal topology modeling that captures dynamic variations in skeletal motion, and (2) they struggle to model multiscale structural relationships beyond local joint connectivity. To address these issues, we propose a novel framework called Dynamic Spatial-Temporal Semantic Awareness Graph Convolutional Network (DSTSA-GCN). DSTSA-GCN introduces three key modules: Group Channel-wise Graph Convolution (GC-GC), Group Temporal-wise Graph Convolution (GT-GC), and Multi-Scale Temporal Convolution (MS-TCN). GC-GC and GT-GC operate in parallel to independently model channel-specific and frame-specific correlations, enabling robust topology learning that accounts for temporal variations. Additionally, both modules employ a grouping strategy to adaptively capture multiscale structural relationships. Complementing this, MS-TCN enhances temporal modeling through group-wise temporal convolutions with diverse receptive fields. Extensive experiments demonstrate that DSTSA-GCN significantly improves the topology modeling capabilities of GCNs, achieving state-of-the-art performance on benchmark datasets for gesture and action recognition, including SHREC17 Track, DHG-14\/28, NTU-RGB+D, and NTU-RGB+D-120.
DeepSeek-V3 Technical Report
Dec 27, 2024



We present DeepSeek-V3, a strong Mixture-of-Experts (MoE) language model with 671B total parameters with 37B activated for each token. To achieve efficient inference and cost-effective training, DeepSeek-V3 adopts Multi-head Latent Attention (MLA) and DeepSeekMoE architectures, which were thoroughly validated in DeepSeek-V2. Furthermore, DeepSeek-V3 pioneers an auxiliary-loss-free strategy for load balancing and sets a multi-token prediction training objective for stronger performance. We pre-train DeepSeek-V3 on 14.8 trillion diverse and high-quality tokens, followed by Supervised Fine-Tuning and Reinforcement Learning stages to fully harness its capabilities. Comprehensive evaluations reveal that DeepSeek-V3 outperforms other open-source models and achieves performance comparable to leading closed-source models. Despite its excellent performance, DeepSeek-V3 requires only 2.788M H800 GPU hours for its full training. In addition, its training process is remarkably stable. Throughout the entire training process, we did not experience any irrecoverable loss spikes or perform any rollbacks. The model checkpoints are available at https://github.com/deepseek-ai/DeepSeek-V3.