 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlightLLM: Efficient Large Language Model Inference with a Complete Mapping Flow on FPGAs
Jan 09, 2024



Transformer-based Large Language Models (LLMs) have made a significant impact on various domains. However, LLMs' efficiency suffers from both heavy computation and memory overheads. Compression techniques like sparsification and quantization are commonly used to mitigate the gap between LLM's computation/memory overheads and hardware capacity. However, existing GPU and transformer-based accelerators cannot efficiently process compressed LLMs, due to the following unresolved challenges: low computational efficiency, underutilized memory bandwidth, and large compilation overheads. This paper proposes FlightLLM, enabling efficient LLMs inference with a complete mapping flow on FPGAs. In FlightLLM, we highlight an innovative solution that the computation and memory overhead of LLMs can be solved by utilizing FPGA-specific resources (e.g., DSP48 and heterogeneous memory hierarchy). We propose a configurable sparse DSP chain to support different sparsity patterns with high computation efficiency. Second, we propose an always-on-chip decode scheme to boost memory bandwidth with mixed-precision support. Finally, to make FlightLLM available for real-world LLMs, we propose a length adaptive compilation method to reduce the compilation overhead. Implemented on the Xilinx Alveo U280 FPGA, FlightLLM achieves 6.0$\times$ higher energy efficiency and 1.8$\times$ better cost efficiency against commercial GPUs (e.g., NVIDIA V100S) on modern LLMs (e.g., LLaMA2-7B) using vLLM and SmoothQuant under the batch size of one. FlightLLM beats NVIDIA A100 GPU with 1.2$\times$ higher throughput using the latest Versal VHK158 FPGA.
Human Transcription Quality Improvement
Sep 24, 2023High quality transcription data is crucial for training automatic speech recognition (ASR) systems. However, the existing industry-level data collection pipelines are expensive to researchers, while the quality of crowdsourced transcription is low. In this paper, we propose a reliable method to collect speech transcriptions. We introduce two mechanisms to improve transcription quality: confidence estimation based reprocessing at labeling stage, and automatic word error correction at post-labeling stage. We collect and release LibriCrowd - a large-scale crowdsourced dataset of audio transcriptions on 100 hours of English speech. Experiment shows the Transcription WER is reduced by over 50%. We further investigate the impact of transcription error on ASR model performance and found a strong correlation. The transcription quality improvement provides over 10% relative WER reduction for ASR models. We release the dataset and code to benefit the research community.
* 5 pages, 3 figures, 5 tables, INTERSPEECH 2023
HTEC: Human Transcription Error Correction
Sep 18, 2023



High-quality human transcription is essential for training and improving Automatic Speech Recognition (ASR) models. Recent study~\cite{libricrowd} has found that every 1% worse transcription Word Error Rate (WER) increases approximately 2% ASR WER by using the transcriptions to train ASR models. Transcription errors are inevitable for even highly-trained annotators. However, few studies have explored human transcription correction. Error correction methods for other problems, such as ASR error correction and grammatical error correction, do not perform sufficiently for this problem. Therefore, we propose HTEC for Human Transcription Error Correction. HTEC consists of two stages: Trans-Checker, an error detection model that predicts and masks erroneous words, and Trans-Filler, a sequence-to-sequence generative model that fills masked positions. We propose a holistic list of correction operations, including four novel operations handling deletion errors. We further propose a variant of embeddings that incorporates phoneme information into the input of the transformer. HTEC outperforms other methods by a large margin and surpasses human annotators by 2.2% to 4.5% in WER. Finally, we deployed HTEC to assist human annotators and showed HTEC is particularly effective as a co-pilot, which improves transcription quality by 15.1% without sacrificing transcription velocity.
Enabling Efficient and Flexible FPGA Virtualization for Deep Learning in the Cloud
Mar 26, 2020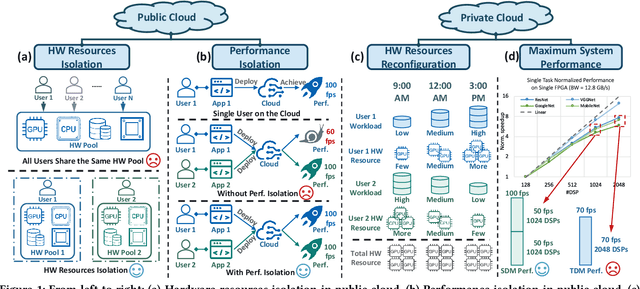
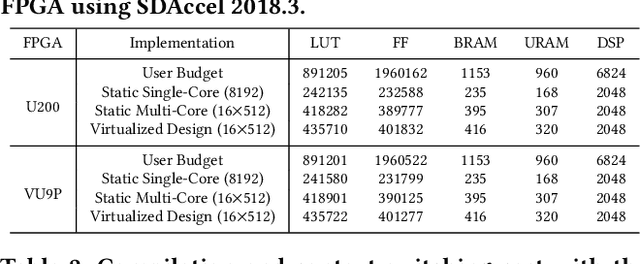
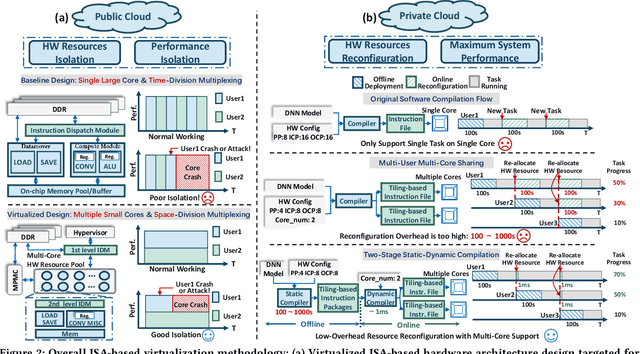
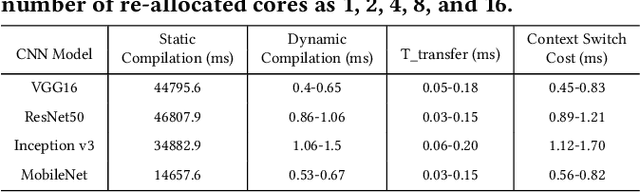
FPGAs have shown great potential in providing low-latency and energy-efficient solutions for deep neural network (DNN) inference applications. Currently, the majority of FPGA-based DNN accelerators in the cloud run in a time-division multiplexing way for multiple users sharing a single FPGA, and require re-compilation with $\sim$100 s overhead. Such designs lead to poor isolation and heavy performance loss for multiple users, which are far away from providing efficient and flexible FPGA virtualization for neither public nor private cloud scenarios. To solve these problems, we introduce a novel virtualization framework for instruction architecture set (ISA) based on DNN accelerators by sharing a single FPGA. We enable the isolation by introducing a two-level instruction dispatch module and a multi-core based hardware resources pool. Such designs provide isolated and runtime-programmable hardware resources, further leading to performance isolation for multiple users. On the other hand, to overcome the heavy re-compilation overheads, we propose a tiling-based instruction frame package design and two-stage static-dynamic compilation. Only the light-weight runtime information is re-compiled with $\sim$1 ms overhead, thus the performance is guaranteed for the private cloud. Our extensive experimental results show that the proposed virtualization design achieves 1.07-1.69x and 1.88-3.12x throughput improvement over previous static designs using the single-core and the multi-core architectures, respectively.