 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Lower Bit Multiplication for Convolutional Neural Network Training
Jun 04, 2020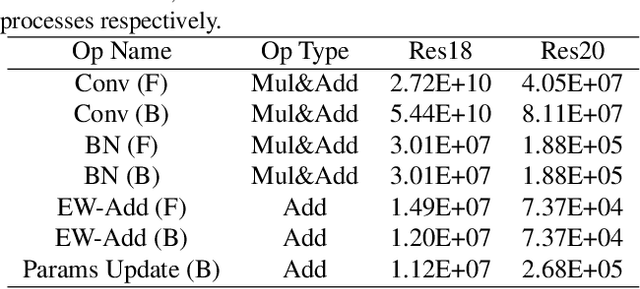
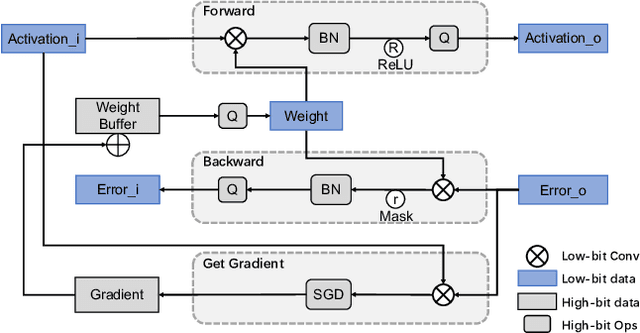
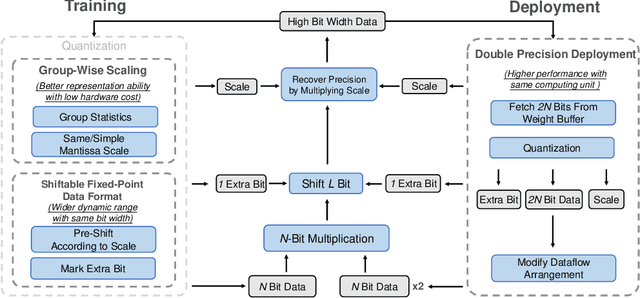
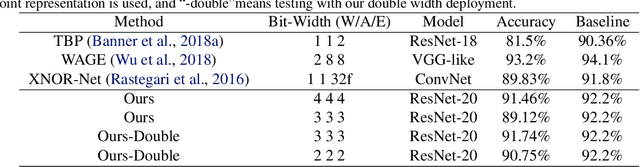
Convolutional Neural Networks (CNNs) have been widely used in many fields. However, the training process costs much energy and time, in which the convolution operations consume the major part. In this paper, we propose a fixed-point training framework, in order to reduce the data bit-width for the convolution multiplications. Firstly, we propose two constrained group-wise scaling methods that can be implemented with low hardware cost. Secondly, to overcome the challenge of trading off overflow and rounding error, a shiftable fixed-point data format is used in this framework. Finally, we propose a double-width deployment technique to boost inference performance with the same bit-width hardware multiplier. The experimental results show that the input data of convolution in the training process can be quantized to 2-bit for CIFAR-10 dataset, 6-bit for ImageNet dataset, with negligible accuracy degradation. Furthermore, our fixed-point train-ing framework has the potential to save at least 75% energy of the computation in the training process.
Enabling Efficient and Flexible FPGA Virtualization for Deep Learning in the Cloud
Mar 26, 2020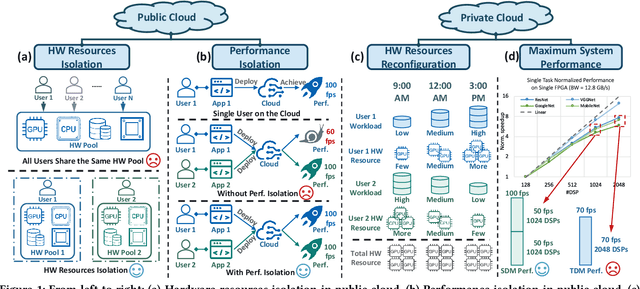
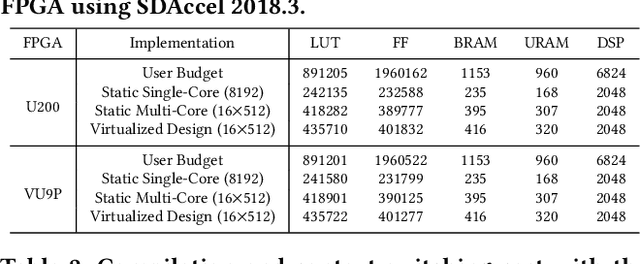
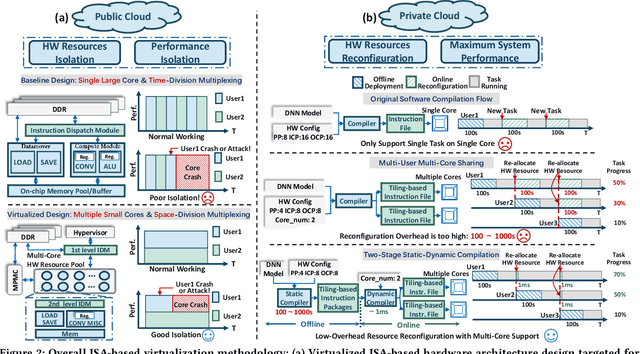
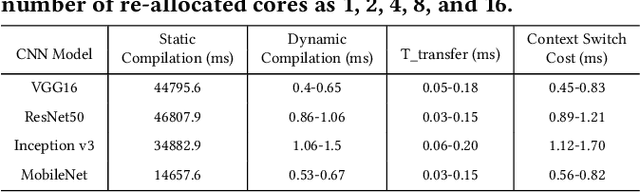
FPGAs have shown great potential in providing low-latency and energy-efficient solutions for deep neural network (DNN) inference applications. Currently, the majority of FPGA-based DNN accelerators in the cloud run in a time-division multiplexing way for multiple users sharing a single FPGA, and require re-compilation with $\sim$100 s overhead. Such designs lead to poor isolation and heavy performance loss for multiple users, which are far away from providing efficient and flexible FPGA virtualization for neither public nor private cloud scenarios. To solve these problems, we introduce a novel virtualization framework for instruction architecture set (ISA) based on DNN accelerators by sharing a single FPGA. We enable the isolation by introducing a two-level instruction dispatch module and a multi-core based hardware resources pool. Such designs provide isolated and runtime-programmable hardware resources, further leading to performance isolation for multiple users. On the other hand, to overcome the heavy re-compilation overheads, we propose a tiling-based instruction frame package design and two-stage static-dynamic compilation. Only the light-weight runtime information is re-compiled with $\sim$1 ms overhead, thus the performance is guaranteed for the private cloud. Our extensive experimental results show that the proposed virtualization design achieves 1.07-1.69x and 1.88-3.12x throughput improvement over previous static designs using the single-core and the multi-core architectures, respectively.