 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Primitives are a Spatial Language for VLMs
May 12, 2026Vision-language models (VLMs) exhibit a striking paradox: they can generate executable code that reconstructs a 3D scene from geometric primitives with correct object counts, classes, and approximate positions, yet the same models fail at simpler spatial questions on the same image. We show that 3D geometric primitives (cubes, spheres, cylinders, expressed in executable code) serve as a powerful intermediate representation for spatial understanding, and exploit this through three contributions. First, we introduce \textbf{\textsc{SpatialBabel}}, a benchmark evaluating fourteen VLMs on primitive-based 3D scene reconstruction across six \emph{scene-code languages} (programming languages and declarative formats for 3D primitive scenes), revealing that a single model's object-detection F1 can vary by up to $5.7\times$ across languages. Second, we propose \textbf{Code-CoT} (Code Chain-of-Thought), a training-free inference strategy that routes spatial reasoning through primitive-based code generation. Code-CoT lifts the SpatialBabel-QA-Score by up to $+6.4$\% on primitive scenes and real-photo CV-Bench-3D accuracy by $+5.0$\% for VLMs with strong coding capabilities. Third, we propose \textbf{S$^{3}$-FT} (Self-Supervised Spatial Fine-Tuning), which self-supervisedly distills primitive spatial knowledge into general visual reasoning by parsing the model's own Three.js primitive-reconstructions into structured annotations and fine-tuning on the result, with \emph{no human labels and no teacher model}. Training on primitive images alone, S$^3$-FT improves Qwen3-VL-8B by $+4.6$ to $+8.6$\% on SpatialBabel-Primitive-QA, $+9.7$\% on CV-Bench-2D, and $+17$\% on HallusionBench; the recipe transfers across model families. These results establish geometric primitives in code as both a diagnostic and a transferable spatial vocabulary for VLMs. We will release all artifacts upon publication.
LLM Agents Enable User-Governed Personalization Beyond Platform Boundaries
May 10, 2026Personalization today is fundamentally platform-centric: services build user representations from the behavioral fragments they observe. Yet no platform can construct a complete picture of the user, as competitive incentives, legal constraints, user privacy concerns, and epistemic limits create persistent data barriers. This paper argues for a shift from platform-centric personalization to user-governed personalization, where only the user can integrate fragmented contexts across platforms and the offline world. The key asymmetry lies in data access: only users can aggregate their own cross-platform and offline information. Large language model (LLM) agents make such integration practically feasible for the first time by enabling reasoning over heterogeneous personal data and transforming users' cross-context information into actionable personalization capabilities. We provide proof-of-concept evidence that users equipped with cross-platform data exports and an off-the-shelf LLM agent can outperform single-platform personalization baselines. We conclude by outlining a research agenda for building scalable user-governed personalization systems.
Fairness-Aware Beamforming for Polarimetric ISAC Systems with Polarization-Reconfigurable Antennas
Mar 18, 2026Polarization diversity offers significant flexibility for enhancing integrated sensing and communications (ISAC). However, conventional dual-polarized arrays typically require dedicated radio-frequency (RF) chains for each polarization branch, leading to prohibitive hardware costs. To address this, polarization-reconfigurable (PR) antennas have emerged as a cost-effective alternative, enabling polarization flexibility with reduced hardware complexity by driving two polarization branches with a single RF chain. In this paper, we investigate fairness-aware beamforming for ISAC systems equipped with PR antennas. Specifically, we jointly optimize the transmit beamforming and PR control coefficients to maximize the minimum signal-to-interference-plus-noise ratio (SINR) for communication users and the minimum signal-to-clutter-plus-noise ratio (SCNR) for sensing targets. The resulting problem is highly nonconvex and nonsmooth due to the strong coupling among optimization variables in the max-min objective, as well as the nonconvex spherical constraints imposed by the PR antennas. To tackle this, we derive an equivalent smooth reformulation by introducing auxiliary variables and transforming the minimum operators into inequality constraints. Subsequently, we develop an exact-penalty product Riemannian manifold gradient descent (EP-PRMGD) algorithm, which integrates an exact penalty method with Riemannian optimization to guarantee convergence to a Karush-Kuhn-Tucker (KKT) point. Numerical results demonstrate that the proposed PR-enabled ISAC scheme achieves performance comparable to dual-polarized architectures while utilizing only half the RF chains, thereby validating its effectiveness in balancing fairness and hardware efficiency.
Cooperative Double IRS aided Secure Communication for MIMO-OFDM Systems
Jan 27, 2026Cooperative double intelligent reflecting surface (double-IRS) has emerged as a promising approach for enhancing physical layer security (PLS) in MIMO systems. However, existing studies are limited to narrowband scenarios and fail to address wideband MIMO-OFDM. In this regime, frequency-flat IRS phases and cascaded IRS links cause severe coupling, rendering narrowband designs inapplicable. To overcome this challenge, we introduce cooperative double-IRS-assisted wideband MIMO-OFDM and propose an efficient manifold-based solution. By regarding the power and constant modulus constraints as Riemannian manifolds, we reformulate the non-convex secrecy sum rate maximization as an unconstrained optimization on a product manifold. Building on this formulation, we further develop a product Riemannian gradient descent (PRGD) algorithm with guaranteed stationary convergence. Simulation results demonstrate that the proposed scheme effectively resolves the OFDM coupling issue and achieves significant secrecy rate gains, outperforming single-IRS and distributed multi-IRS benchmarks by 32.0% and 22.3%, respectively.
Joint Analog Beamforming and Antenna Position Design for Secure Communication systems With Movable Antennas
Nov 19, 2025Movable antennas (MA) are a novel technology that allows for the flexible adjustment of antenna positions within a specified region, thereby enhancing the performance of wireless communication systems. In this paper, we explore the use of MA to improve physical layer security in an analog beamforming (AB) communication system. Our goal is to maximize the secrecy rate by jointly optimizing the transmit AB and MA position, subject to constant modulus (CM) constraints on the AB and position constraints for the MA. The resulting problem is non-convex, and we propose a penalty product manifold (PPM) method to solve it efficiently. Specifically, we convert the inequality constraints related to MA position into a penalty function using smoothing techniques, thereby reformulating the problem as an unconstrained optimization on the product manifold space (PMS). We then derive a parallel conjugate gradient descent (PCGD) algorithm to update both the AB and MA position on the PMS. This method is efficient, providing an analytical solution at each step and ensuring convergence to a KKT point. Simulation results show that the MA system achieves a higher secrecy rate than systems with fixed-position antennas.
Movable IRS-Aided ISAC Systems: Joint Beamforming and Position Optimization
Sep 05, 2025Driven by intelligent reflecting surface (IRS) and movable antenna (MA) technologies, movable IRS (MIRS) has been proposed to improve the adaptability and performance of conventional IRS, enabling flexible adjustment of the IRS reflecting element positions. This paper investigates MIRS-aided integrated sensing and communication (ISAC) systems. The objective is to minimize the power required for satisfying the quality-of-service (QoS) of sensing and communication by jointly optimizing the MIRS element positions, IRS reflection coefficients, transmit beamforming, and receive filters. To balance the performance-cost trade-off, we proposed two MIRS schemes: element-wise control and array-wise control, where the positions of individual reflecting elements and arrays consisting of multiple elements are controllable, respectively. To address the joint beamforming and position optimization, a product Riemannian manifold optimization (PRMO) method is proposed, where the variables are updated over a constructed product Riemannian manifold space (PRMS) in parallel via penalty-based transformation and Riemannian Broyden-Fletcher-Goldfarb-Shanno (RBFGS) algorithm. Simulation results demonstrate that the proposed MIRS outperforms conventional IRS in power minimization with both element-wise control and array-wise control. Specifically, with different system parameters, the minimum power is achieved by the MIRS with the element-wise control scheme, while suboptimal solution and higher computational efficiency are achieved by the MIRS with array-wise control scheme.
RankFlow: A Multi-Role Collaborative Reranking Workflow Utilizing Large Language Models
Feb 04, 2025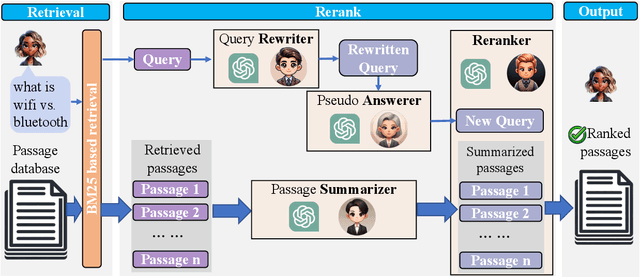
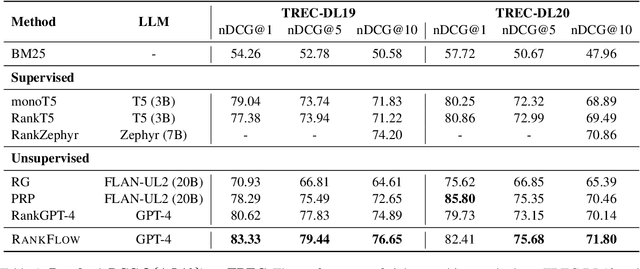
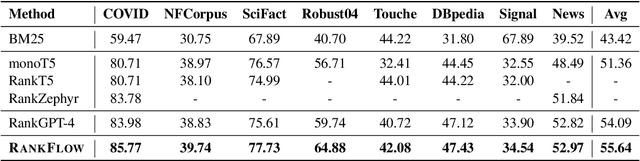
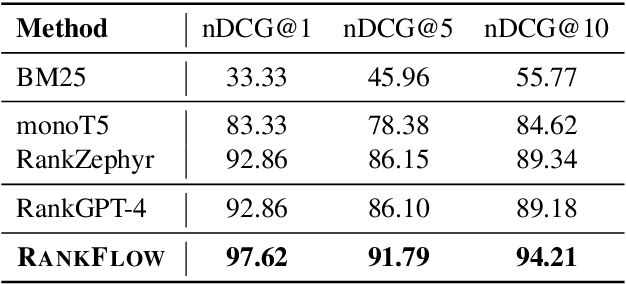
In an Information Retrieval (IR) system, reranking plays a critical role by sorting candidate passages according to their relevance to a specific query. This process demands a nuanced understanding of the variations among passages linked to the query. In this work, we introduce RankFlow, a multi-role reranking workflow that leverages the capabilities of Large Language Models (LLMs) and role specializations to improve reranking performance. RankFlow enlists LLMs to fulfill four distinct roles: the query Rewriter, the pseudo Answerer, the passage Summarizer, and the Reranker. This orchestrated approach enables RankFlow to: (1) accurately interpret queries, (2) draw upon LLMs' extensive pre-existing knowledge, (3) distill passages into concise versions, and (4) assess passages in a comprehensive manner, resulting in notably better reranking results. Our experimental results reveal that RankFlow outperforms existing leading approaches on widely recognized IR benchmarks, such as TREC-DL, BEIR, and NovelEval. Additionally, we investigate the individual contributions of each role in RankFlow. Code is available at https://github.com/jincan333/RankFlow.
Joint Beamforming and Antenna Position Design for IRS-Aided Multi-User Movable Antenna Systems
Oct 01, 2024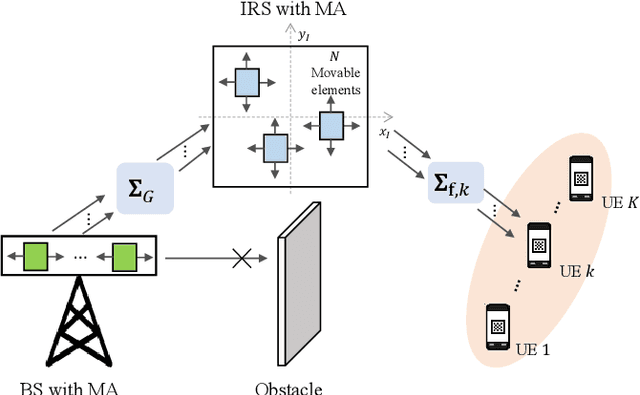
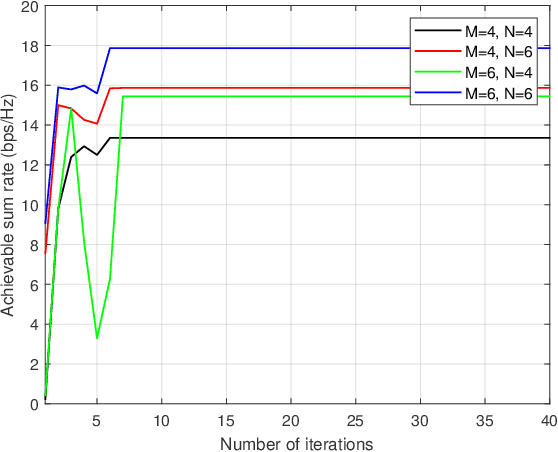
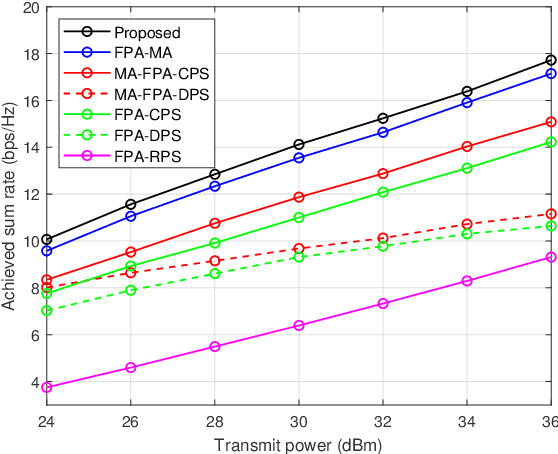
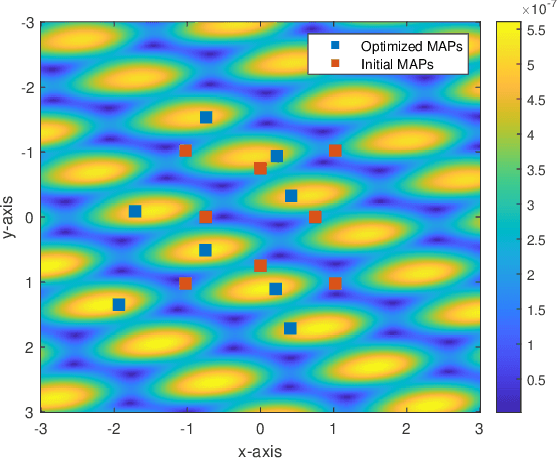
Intelligent reflecting surface (IRS) and movable antenna (MA) technologies have been proposed to enhance wireless communications by creating favorable channel conditions. This paper investigates the joint beamforming and antenna position design for an MA-enabled IRS (MA-IRS)-aided multi-user multiple-input single-output (MU-MISO) communication system, where the MA-IRS is deployed to aid the communication between the MA-enabled base station (BS) and user equipment (UE). In contrast to conventional fixed position antenna (FPA)-enabled IRS (FPA-IRS), the MA-IRS enhances the wireless channel by controlling the positions of the reflecting elements. To verify the system's effectiveness and optimize its performance, we formulate a sum-rate maximization problem with a minimum rate threshold constraint for the MU-MISO communication. To tackle the non-convex problem, a product Riemannian manifold optimization (PRMO) method is proposed for the joint design of the beamforming and MA positions. Specifically, a product Riemannian manifold space (PRMS) is constructed and the corresponding Riemannian gradient is derived for updating the variables, and the Riemannian exact penalty (REP) method and a Riemannian Broyden-Fletcher-Goldfarb-Shanno (RBFGS) algorithm is derived to obtain a feasible solution over the PRMS. Simulation results demonstrate that compared with the conventional FPA-IRS-aided MU-MISO communication, the reflecting elements of the MA-IRS can move to the positions with higher channel gain, thus enhancing the system performance. Furthermore, it is shown that integrating MA with IRS leads to higher performance gains compared to integrating MA with BS.
APEER: Automatic Prompt Engineering Enhances Large Language Model Reranking
Jun 20, 2024Large Language Models (LLMs) have significantly enhanced Information Retrieval (IR) across various modules, such as reranking. Despite impressive performance, current zero-shot relevance ranking with LLMs heavily relies on human prompt engineering. Existing automatic prompt engineering algorithms primarily focus on language modeling and classification tasks, leaving the domain of IR, particularly reranking, underexplored. Directly applying current prompt engineering algorithms to relevance ranking is challenging due to the integration of query and long passage pairs in the input, where the ranking complexity surpasses classification tasks. To reduce human effort and unlock the potential of prompt optimization in reranking, we introduce a novel automatic prompt engineering algorithm named APEER. APEER iteratively generates refined prompts through feedback and preference optimization. Extensive experiments with four LLMs and ten datasets demonstrate the substantial performance improvement of APEER over existing state-of-the-art (SoTA) manual prompts. Furthermore, we find that the prompts generated by APEER exhibit better transferability across diverse tasks and LLMs. Code is available at https://github.com/jincan333/APEER.
FOSS: A Self-Learned Doctor for Query Optimizer
Dec 11, 2023



Various works have utilized deep reinforcement learning (DRL) to address the query optimization problem in database system. They either learn to construct plans from scratch in a bottom-up manner or guide the plan generation behavior of traditional optimizer using hints. While these methods have achieved some success, they face challenges in either low training efficiency or limited plan search space. To address these challenges, we introduce FOSS, a novel DRL-based framework for query optimization. FOSS initiates optimization from the original plan generated by a traditional optimizer and incrementally refines suboptimal nodes of the plan through a sequence of actions. Additionally, we devise an asymmetric advantage model to evaluate the advantage between two plans. We integrate it with a traditional optimizer to form a simulated environment. Leveraging this simulated environment, FOSS can bootstrap itself to rapidly generate a large amount of high-quality simulated experiences. FOSS then learns and improves its optimization capability from these simulated experiences. We evaluate the performance of FOSS on Join Order Benchmark, TPC-DS, and Stack Overflow. The experimental results demonstrate that FOSS outperforms the state-of-the-art methods in terms of latency performance and optimization time. Compared to PostgreSQL, FOSS achieves savings ranging from 15% to 83% in total latency across different benchmarks.