 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLlama-Nemotron: Efficient Reasoning Models
May 02, 2025



We introduce the Llama-Nemotron series of models, an open family of heterogeneous reasoning models that deliver exceptional reasoning capabilities, inference efficiency, and an open license for enterprise use. The family comes in three sizes -- Nano (8B), Super (49B), and Ultra (253B) -- and performs competitively with state-of-the-art reasoning models such as DeepSeek-R1 while offering superior inference throughput and memory efficiency. In this report, we discuss the training procedure for these models, which entails using neural architecture search from Llama 3 models for accelerated inference, knowledge distillation, and continued pretraining, followed by a reasoning-focused post-training stage consisting of two main parts: supervised fine-tuning and large scale reinforcement learning. Llama-Nemotron models are the first open-source models to support a dynamic reasoning toggle, allowing users to switch between standard chat and reasoning modes during inference. To further support open research and facilitate model development, we provide the following resources: 1. We release the Llama-Nemotron reasoning models -- LN-Nano, LN-Super, and LN-Ultra -- under the commercially permissive NVIDIA Open Model License Agreement. 2. We release the complete post-training dataset: Llama-Nemotron-Post-Training-Dataset. 3. We also release our training codebases: NeMo, NeMo-Aligner, and Megatron-LM.
MixDQ: Memory-Efficient Few-Step Text-to-Image Diffusion Models with Metric-Decoupled Mixed Precision Quantization
May 30, 2024



Diffusion models have achieved significant visual generation quality. However, their significant computational and memory costs pose challenge for their application on resource-constrained mobile devices or even desktop GPUs. Recent few-step diffusion models reduces the inference time by reducing the denoising steps. However, their memory consumptions are still excessive. The Post Training Quantization (PTQ) replaces high bit-width FP representation with low-bit integer values (INT4/8) , which is an effective and efficient technique to reduce the memory cost. However, when applying to few-step diffusion models, existing quantization methods face challenges in preserving both the image quality and text alignment. To address this issue, we propose an mixed-precision quantization framework - MixDQ. Firstly, We design specialized BOS-aware quantization method for highly sensitive text embedding quantization. Then, we conduct metric-decoupled sensitivity analysis to measure the sensitivity of each layer. Finally, we develop an integer-programming-based method to conduct bit-width allocation. While existing quantization methods fall short at W8A8, MixDQ could achieve W8A8 without performance loss, and W4A8 with negligible visual degradation. Compared with FP16, we achieve 3-4x reduction in model size and memory cost, and 1.45x latency speedup.
Understanding GNN Computational Graph: A Coordinated Computation, IO, and Memory Perspective
Oct 18, 2021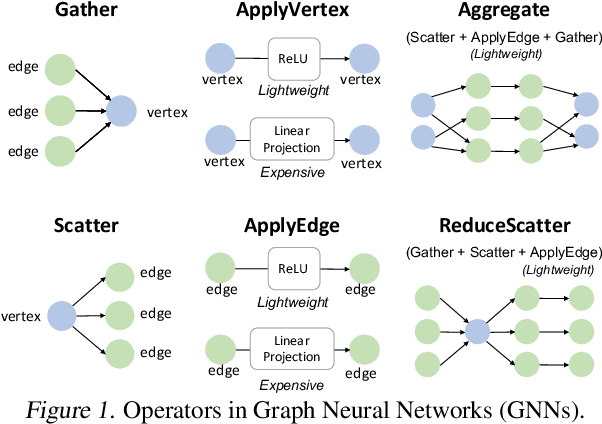
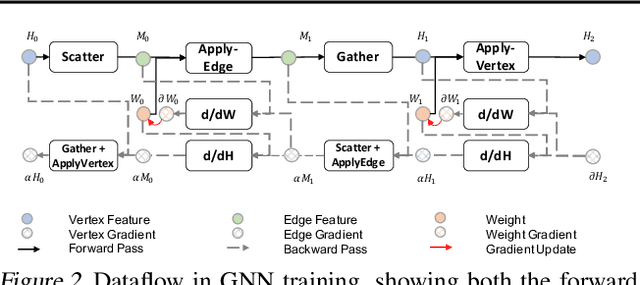
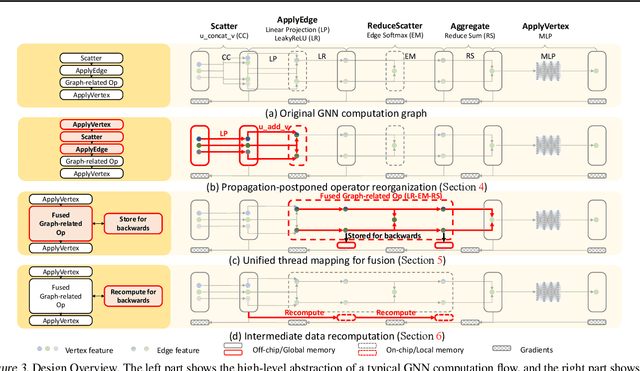
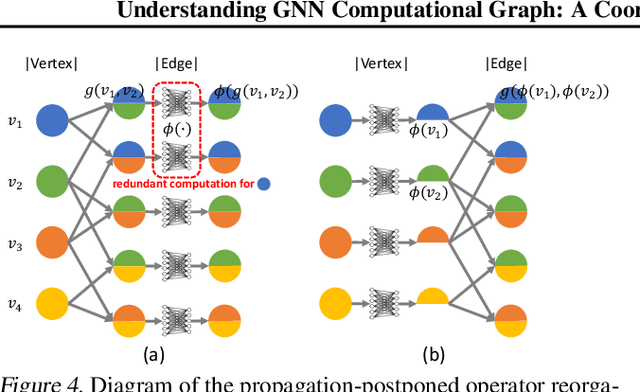
Graph Neural Networks (GNNs) have been widely used in various domains, and GNNs with sophisticated computational graph lead to higher latency and larger memory consumption. Optimizing the GNN computational graph suffers from: (1) Redundant neural operator computation. The same data are propagated through the graph structure to perform the same neural operation multiple times in GNNs, leading to redundant computation which accounts for 92.4% of total operators. (2) Inconsistent thread mapping. Efficient thread mapping schemes for vertex-centric and edge-centric operators are different. This inconsistency prohibits operator fusion to reduce memory IO. (3) Excessive intermediate data. For GNN training which is usually performed concurrently with inference, intermediate data must be stored for the backward pass, consuming 91.9% of the total memory requirement. To tackle these challenges, we propose following designs to optimize the GNN computational graph from a novel coordinated computation, IO, and memory perspective: (1) Propagation-postponed operator reorganization. We reorganize operators to perform neural operations before the propagation, thus the redundant computation is eliminated. (2) Unified thread mapping for fusion. We propose a unified thread mapping scheme for both vertex- and edge-centric operators to enable fusion and reduce IO. (3) Intermediate data recomputation. Intermediate data are recomputed during the backward pass to reduce the total memory consumption. Extensive experimental results on three typical GNN models show that, we achieve up to 2.75x end-to-end speedup, 6.89x less memory IO, and 7.73x less memory consumption over state-of-the-art frameworks.
Machine Learning for Electronic Design Automation: A Survey
Jan 10, 2021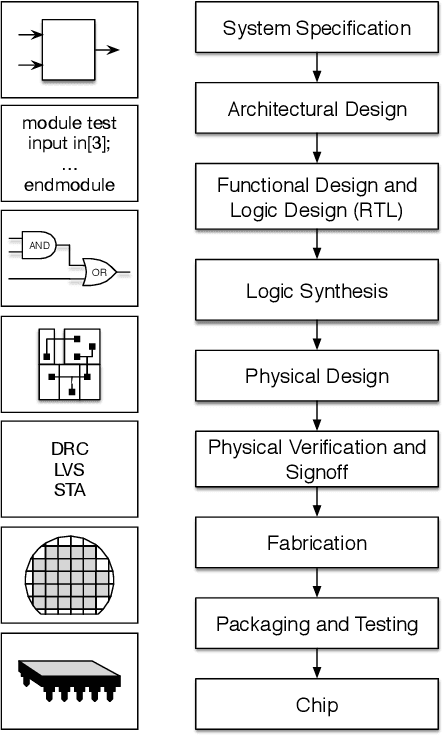

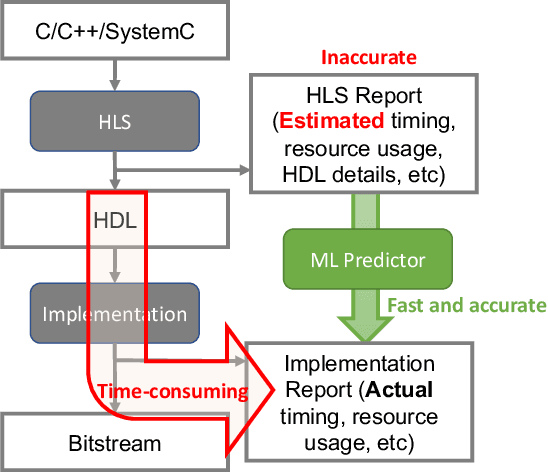
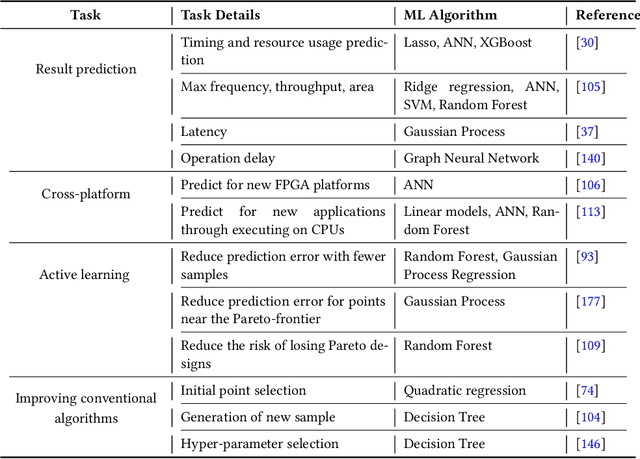
With the down-scaling of CMOS technology, the design complexity of very large-scale integrated (VLSI) is increasing. Although the application of machine learning (ML) techniques in electronic design automation (EDA) can trace its history back to the 90s, the recent breakthrough of ML and the increasing complexity of EDA tasks have aroused more interests in incorporating ML to solve EDA tasks. In this paper, we present a comprehensive review of existing ML for EDA studies, organized following the EDA hierarchy.