 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSALAD: Achieve High-Sparsity Attention via Efficient Linear Attention Tuning for Video Diffusion Transformer
Jan 23, 2026Diffusion Transformers have recently demonstrated remarkable performance in video generation. However, the long input sequences result in high computational latency due to the quadratic complexity of full attention. Various sparse attention mechanisms have been proposed. Training-free sparse attention is constrained by limited sparsity and thus offers modest acceleration, whereas training-based methods can reach much higher sparsity but demand substantial data and computation for training. In this work, we propose SALAD, introducing a lightweight linear attention branch in parallel with the sparse attention. By incorporating an input-dependent gating mechanism to finely balance the two branches, our method attains 90% sparsity and 1.72x inference speedup, while maintaining generation quality comparable to the full attention baseline. Moreover, our finetuning process is highly efficient, requiring only 2,000 video samples and 1,600 training steps with a batch size of 8.
VocabTailor: Dynamic Vocabulary Selection for Downstream Tasks in Small Language Models
Aug 21, 2025Small Language Models (SLMs) provide computational advantages in resource-constrained environments, yet memory limitations remain a critical bottleneck for edge device deployment. A substantial portion of SLMs' memory footprint stems from vocabulary-related components, particularly embeddings and language modeling (LM) heads, due to large vocabulary sizes. Existing static vocabulary pruning, while reducing memory usage, suffers from rigid, one-size-fits-all designs that cause information loss from the prefill stage and a lack of flexibility. In this work, we identify two key principles underlying the vocabulary reduction challenge: the lexical locality principle, the observation that only a small subset of tokens is required during any single inference, and the asymmetry in computational characteristics between vocabulary-related components of SLM. Based on these insights, we introduce VocabTailor, a novel decoupled dynamic vocabulary selection framework that addresses memory constraints through offloading embedding and implements a hybrid static-dynamic vocabulary selection strategy for LM Head, enabling on-demand loading of vocabulary components. Comprehensive experiments across diverse downstream tasks demonstrate that VocabTailor achieves a reduction of up to 99% in the memory usage of vocabulary-related components with minimal or no degradation in task performance, substantially outperforming existing static vocabulary pruning.
DLFR-VAE: Dynamic Latent Frame Rate VAE for Video Generation
Feb 17, 2025
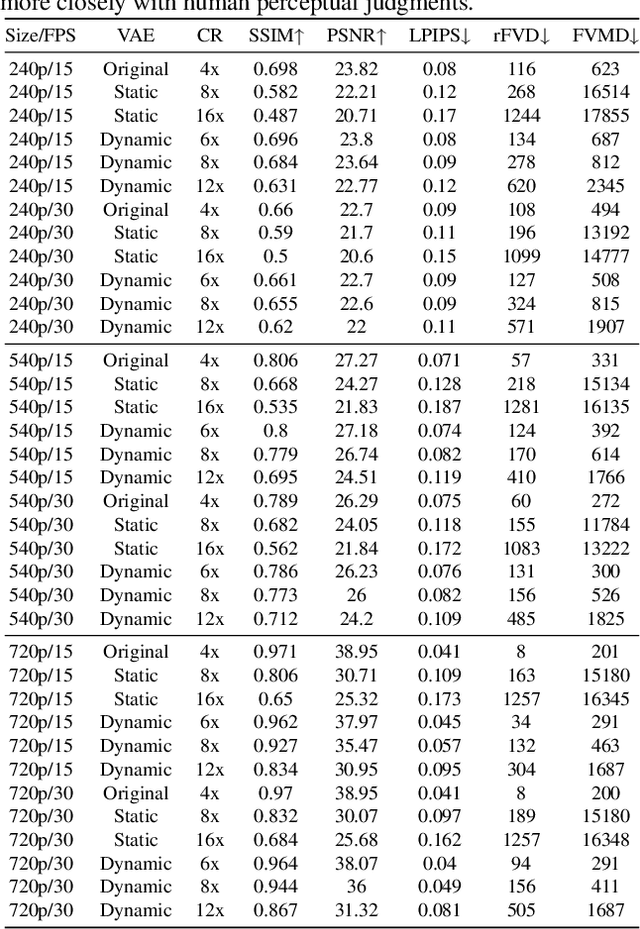

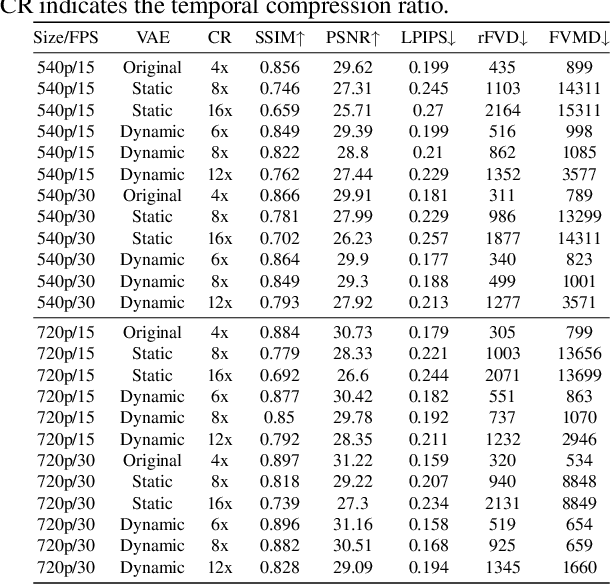
In this paper, we propose the Dynamic Latent Frame Rate VAE (DLFR-VAE), a training-free paradigm that can make use of adaptive temporal compression in latent space. While existing video generative models apply fixed compression rates via pretrained VAE, we observe that real-world video content exhibits substantial temporal non-uniformity, with high-motion segments containing more information than static scenes. Based on this insight, DLFR-VAE dynamically adjusts the latent frame rate according to the content complexity. Specifically, DLFR-VAE comprises two core innovations: (1) A Dynamic Latent Frame Rate Scheduler that partitions videos into temporal chunks and adaptively determines optimal frame rates based on information-theoretic content complexity, and (2) A training-free adaptation mechanism that transforms pretrained VAE architectures into a dynamic VAE that can process features with variable frame rates. Our simple but effective DLFR-VAE can function as a plug-and-play module, seamlessly integrating with existing video generation models and accelerating the video generation process.
E-CAR: Efficient Continuous Autoregressive Image Generation via Multistage Modeling
Dec 19, 2024



Recent advances in autoregressive (AR) models with continuous tokens for image generation show promising results by eliminating the need for discrete tokenization. However, these models face efficiency challenges due to their sequential token generation nature and reliance on computationally intensive diffusion-based sampling. We present ECAR (Efficient Continuous Auto-Regressive Image Generation via Multistage Modeling), an approach that addresses these limitations through two intertwined innovations: (1) a stage-wise continuous token generation strategy that reduces computational complexity and provides progressively refined token maps as hierarchical conditions, and (2) a multistage flow-based distribution modeling method that transforms only partial-denoised distributions at each stage comparing to complete denoising in normal diffusion models. Holistically, ECAR operates by generating tokens at increasing resolutions while simultaneously denoising the image at each stage. This design not only reduces token-to-image transformation cost by a factor of the stage number but also enables parallel processing at the token level. Our approach not only enhances computational efficiency but also aligns naturally with image generation principles by operating in continuous token space and following a hierarchical generation process from coarse to fine details. Experimental results demonstrate that ECAR achieves comparable image quality to DiT Peebles & Xie [2023] while requiring 10$\times$ FLOPs reduction and 5$\times$ speedup to generate a 256$\times$256 image.
ViDiT-Q: Efficient and Accurate Quantization of Diffusion Transformers for Image and Video Generation
Jun 04, 2024



Diffusion transformers (DiTs) have exhibited remarkable performance in visual generation tasks, such as generating realistic images or videos based on textual instructions. However, larger model sizes and multi-frame processing for video generation lead to increased computational and memory costs, posing challenges for practical deployment on edge devices. Post-Training Quantization (PTQ) is an effective method for reducing memory costs and computational complexity. When quantizing diffusion transformers, we find that applying existing diffusion quantization methods designed for U-Net faces challenges in preserving quality. After analyzing the major challenges for quantizing diffusion transformers, we design an improved quantization scheme: "ViDiT-Q": Video and Image Diffusion Transformer Quantization) to address these issues. Furthermore, we identify highly sensitive layers and timesteps hinder quantization for lower bit-widths. To tackle this, we improve ViDiT-Q with a novel metric-decoupled mixed-precision quantization method (ViDiT-Q-MP). We validate the effectiveness of ViDiT-Q across a variety of text-to-image and video models. While baseline quantization methods fail at W8A8 and produce unreadable content at W4A8, ViDiT-Q achieves lossless W8A8 quantization. ViDiTQ-MP achieves W4A8 with negligible visual quality degradation, resulting in a 2.5x memory optimization and a 1.5x latency speedup.
MixDQ: Memory-Efficient Few-Step Text-to-Image Diffusion Models with Metric-Decoupled Mixed Precision Quantization
May 30, 2024



Diffusion models have achieved significant visual generation quality. However, their significant computational and memory costs pose challenge for their application on resource-constrained mobile devices or even desktop GPUs. Recent few-step diffusion models reduces the inference time by reducing the denoising steps. However, their memory consumptions are still excessive. The Post Training Quantization (PTQ) replaces high bit-width FP representation with low-bit integer values (INT4/8) , which is an effective and efficient technique to reduce the memory cost. However, when applying to few-step diffusion models, existing quantization methods face challenges in preserving both the image quality and text alignment. To address this issue, we propose an mixed-precision quantization framework - MixDQ. Firstly, We design specialized BOS-aware quantization method for highly sensitive text embedding quantization. Then, we conduct metric-decoupled sensitivity analysis to measure the sensitivity of each layer. Finally, we develop an integer-programming-based method to conduct bit-width allocation. While existing quantization methods fall short at W8A8, MixDQ could achieve W8A8 without performance loss, and W4A8 with negligible visual degradation. Compared with FP16, we achieve 3-4x reduction in model size and memory cost, and 1.45x latency speedup.