 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSilentDrift: Exploiting Action Chunking for Stealthy Backdoor Attacks on Vision-Language-Action Models
Jan 20, 2026Vision-Language-Action (VLA) models are increasingly deployed in safety-critical robotic applications, yet their security vulnerabilities remain underexplored. We identify a fundamental security flaw in modern VLA systems: the combination of action chunking and delta pose representations creates an intra-chunk visual open-loop. This mechanism forces the robot to execute K-step action sequences, allowing per-step perturbations to accumulate through integration. We propose SILENTDRIFT, a stealthy black-box backdoor attack exploiting this vulnerability. Our method employs the Smootherstep function to construct perturbations with guaranteed C2 continuity, ensuring zero velocity and acceleration at trajectory boundaries to satisfy strict kinematic consistency constraints. Furthermore, our keyframe attack strategy selectively poisons only the critical approach phase, maximizing impact while minimizing trigger exposure. The resulting poisoned trajectories are visually indistinguishable from successful demonstrations. Evaluated on the LIBERO, SILENTDRIFT achieves a 93.2% Attack Success Rate with a poisoning rate under 2%, while maintaining a 95.3% Clean Task Success Rate.
ButterflyQuant: Ultra-low-bit LLM Quantization through Learnable Orthogonal Butterfly Transforms
Sep 11, 2025Large language models require massive memory footprints, severely limiting deployment on consumer hardware. Quantization reduces memory through lower numerical precision, but extreme 2-bit quantization suffers from catastrophic performance loss due to outliers in activations. Rotation-based methods such as QuIP and QuaRot apply orthogonal transforms to eliminate outliers before quantization, using computational invariance: $\mathbf{y} = \mathbf{Wx} = (\mathbf{WQ}^T)(\mathbf{Qx})$ for orthogonal $\mathbf{Q}$. However, these methods use fixed transforms--Hadamard matrices achieving optimal worst-case coherence $\mu = 1/\sqrt{n}$--that cannot adapt to specific weight distributions. We identify that different transformer layers exhibit distinct outlier patterns, motivating layer-adaptive rotations rather than one-size-fits-all approaches. We propose ButterflyQuant, which replaces Hadamard rotations with learnable butterfly transforms parameterized by continuous Givens rotation angles. Unlike Hadamard's discrete $\{+1, -1\}$ entries that are non-differentiable and prohibit gradient-based learning, butterfly transforms' continuous parameterization enables smooth optimization while guaranteeing orthogonality by construction. This orthogonal constraint ensures theoretical guarantees in outlier suppression while achieving $O(n \log n)$ computational complexity with only $\frac{n \log n}{2}$ learnable parameters. We further introduce a uniformity regularization on post-transformation activations to promote smoother distributions amenable to quantization. Learning requires only 128 calibration samples and converges in minutes on a single GPU--a negligible one-time cost. On LLaMA-2-7B with 2-bit quantization, ButterflyQuant achieves 15.4 perplexity versus 22.1 for QuaRot.
E-CAR: Efficient Continuous Autoregressive Image Generation via Multistage Modeling
Dec 19, 2024



Recent advances in autoregressive (AR) models with continuous tokens for image generation show promising results by eliminating the need for discrete tokenization. However, these models face efficiency challenges due to their sequential token generation nature and reliance on computationally intensive diffusion-based sampling. We present ECAR (Efficient Continuous Auto-Regressive Image Generation via Multistage Modeling), an approach that addresses these limitations through two intertwined innovations: (1) a stage-wise continuous token generation strategy that reduces computational complexity and provides progressively refined token maps as hierarchical conditions, and (2) a multistage flow-based distribution modeling method that transforms only partial-denoised distributions at each stage comparing to complete denoising in normal diffusion models. Holistically, ECAR operates by generating tokens at increasing resolutions while simultaneously denoising the image at each stage. This design not only reduces token-to-image transformation cost by a factor of the stage number but also enables parallel processing at the token level. Our approach not only enhances computational efficiency but also aligns naturally with image generation principles by operating in continuous token space and following a hierarchical generation process from coarse to fine details. Experimental results demonstrate that ECAR achieves comparable image quality to DiT Peebles & Xie [2023] while requiring 10$\times$ FLOPs reduction and 5$\times$ speedup to generate a 256$\times$256 image.
freePruner: A Training-free Approach for Large Multimodal Model Acceleration
Nov 23, 2024



Large Multimodal Models (LMMs) have demonstrated impressive capabilities in visual-language tasks but face significant deployment challenges due to their high computational demands. While recent token reduction methods show promise for accelerating LMMs, they typically require extensive retraining or fine-tuning, making them impractical for many state-of-the-art models, especially those with proprietary training data. We propose freePruner, a training-free token reduction approach that can be directly applied to any open-source LMM without additional training. Unlike existing methods that rely heavily on token merging operations, freePruner employs a two-stage token selection strategy: (1) identifying pivotal tokens that capture high-level semantic information using our designed contribution degree metric, and (2) selecting complementary tokens that preserve essential low-level visual details through attention pattern analysis. Extensive experiments demonstrate that freePruner achieves 2x acceleration while maintaining comparable performance across mainstream visual question-answering benchmarks in the training-free setting. Moreover, freePruner is orthogonal to and can be combined with other post-training acceleration techniques, such as post-training quantization, providing a practical solution for efficient LMM deployment.
Technique Report of CVPR 2024 PBDL Challenges
Jun 15, 2024



The intersection of physics-based vision and deep learning presents an exciting frontier for advancing computer vision technologies. By leveraging the principles of physics to inform and enhance deep learning models, we can develop more robust and accurate vision systems. Physics-based vision aims to invert the processes to recover scene properties such as shape, reflectance, light distribution, and medium properties from images. In recent years, deep learning has shown promising improvements for various vision tasks, and when combined with physics-based vision, these approaches can enhance the robustness and accuracy of vision systems. This technical report summarizes the outcomes of the Physics-Based Vision Meets Deep Learning (PBDL) 2024 challenge, held in CVPR 2024 workshop. The challenge consisted of eight tracks, focusing on Low-Light Enhancement and Detection as well as High Dynamic Range (HDR) Imaging. This report details the objectives, methodologies, and results of each track, highlighting the top-performing solutions and their innovative approaches.
LLaVA-PruMerge: Adaptive Token Reduction for Efficient Large Multimodal Models
Apr 01, 2024Large Multimodal Models (LMMs) have shown significant reasoning capabilities by connecting a visual encoder and a large language model. LMMs typically use a fixed amount of visual tokens, such as the penultimate layer features in the CLIP visual encoder, as the prefix content. Recent LMMs incorporate more complex visual inputs, such as high-resolution images and videos, which increase the number of visual tokens significantly. However, due to the design of the Transformer architecture, computational costs associated with these models tend to increase quadratically with the number of input tokens. To tackle this problem, we explore a token reduction mechanism and find, similar to prior work, that many visual tokens are spatially redundant. Based on this, we propose PruMerge, a novel adaptive visual token reduction approach, which largely reduces the number of visual tokens while maintaining comparable model performance. We first select the unpruned visual tokens based on their similarity to class tokens and spatial tokens. We then cluster the pruned tokens based on key similarity and merge the clustered tokens with the unpruned tokens to supplement their information. Empirically, when applied to LLaVA-1.5, our approach can compress the visual tokens by 18 times on average, and achieve comparable performance across diverse visual question-answering and reasoning tasks. Code and checkpoints are at https://llava-prumerge.github.io/.
Causal-DFQ: Causality Guided Data-free Network Quantization
Sep 24, 2023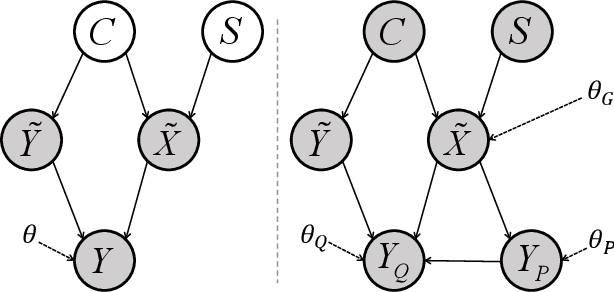
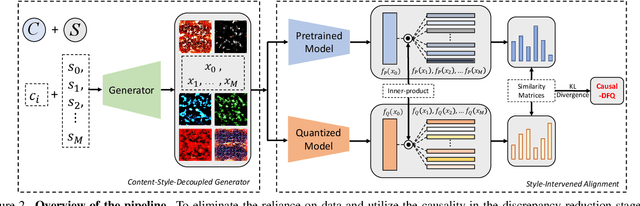
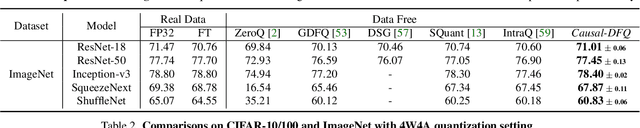
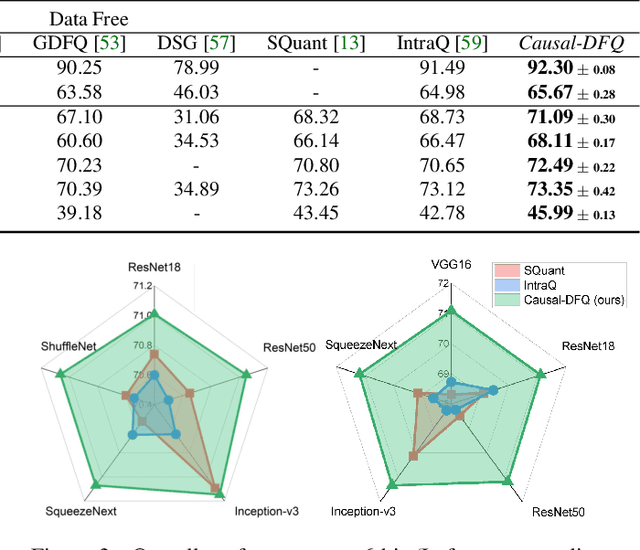
Model quantization, which aims to compress deep neural networks and accelerate inference speed, has greatly facilitated the development of cumbersome models on mobile and edge devices. There is a common assumption in quantization methods from prior works that training data is available. In practice, however, this assumption cannot always be fulfilled due to reasons of privacy and security, rendering these methods inapplicable in real-life situations. Thus, data-free network quantization has recently received significant attention in neural network compression. Causal reasoning provides an intuitive way to model causal relationships to eliminate data-driven correlations, making causality an essential component of analyzing data-free problems. However, causal formulations of data-free quantization are inadequate in the literature. To bridge this gap, we construct a causal graph to model the data generation and discrepancy reduction between the pre-trained and quantized models. Inspired by the causal understanding, we propose the Causality-guided Data-free Network Quantization method, Causal-DFQ, to eliminate the reliance on data via approaching an equilibrium of causality-driven intervened distributions. Specifically, we design a content-style-decoupled generator, synthesizing images conditioned on the relevant and irrelevant factors; then we propose a discrepancy reduction loss to align the intervened distributions of the pre-trained and quantized models. It is worth noting that our work is the first attempt towards introducing causality to data-free quantization problem. Extensive experiments demonstrate the efficacy of Causal-DFQ. The code is available at https://github.com/42Shawn/Causal-DFQ.