 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent Zoning Network: A Unified Principle for Generative Modeling, Representation Learning, and Classification
Sep 19, 2025Generative modeling, representation learning, and classification are three core problems in machine learning (ML), yet their state-of-the-art (SoTA) solutions remain largely disjoint. In this paper, we ask: Can a unified principle address all three? Such unification could simplify ML pipelines and foster greater synergy across tasks. We introduce Latent Zoning Network (LZN) as a step toward this goal. At its core, LZN creates a shared Gaussian latent space that encodes information across all tasks. Each data type (e.g., images, text, labels) is equipped with an encoder that maps samples to disjoint latent zones, and a decoder that maps latents back to data. ML tasks are expressed as compositions of these encoders and decoders: for example, label-conditional image generation uses a label encoder and image decoder; image embedding uses an image encoder; classification uses an image encoder and label decoder. We demonstrate the promise of LZN in three increasingly complex scenarios: (1) LZN can enhance existing models (image generation): When combined with the SoTA Rectified Flow model, LZN improves FID on CIFAR10 from 2.76 to 2.59-without modifying the training objective. (2) LZN can solve tasks independently (representation learning): LZN can implement unsupervised representation learning without auxiliary loss functions, outperforming the seminal MoCo and SimCLR methods by 9.3% and 0.2%, respectively, on downstream linear classification on ImageNet. (3) LZN can solve multiple tasks simultaneously (joint generation and classification): With image and label encoders/decoders, LZN performs both tasks jointly by design, improving FID and achieving SoTA classification accuracy on CIFAR10. The code and trained models are available at https://github.com/microsoft/latent-zoning-networks. The project website is at https://zinanlin.me/blogs/latent_zoning_networks.html.
R2R: Efficiently Navigating Divergent Reasoning Paths with Small-Large Model Token Routing
May 27, 2025Large Language Models (LLMs) achieve impressive reasoning capabilities at the cost of substantial inference overhead, posing substantial deployment challenges. Although distilled Small Language Models (SLMs) significantly enhance efficiency, their performance suffers as they fail to follow LLMs' reasoning paths. Luckily, we reveal that only a small fraction of tokens genuinely diverge reasoning paths between LLMs and SLMs. Most generated tokens are either identical or exhibit neutral differences, such as minor variations in abbreviations or expressions. Leveraging this insight, we introduce **Roads to Rome (R2R)**, a neural token routing method that selectively utilizes LLMs only for these critical, path-divergent tokens, while leaving the majority of token generation to the SLM. We also develop an automatic data generation pipeline that identifies divergent tokens and generates token-level routing labels to train the lightweight router. We apply R2R to combine R1-1.5B and R1-32B models from the DeepSeek family, and evaluate on challenging math, coding, and QA benchmarks. With an average activated parameter size of 5.6B, R2R surpasses the average accuracy of R1-7B by 1.6x, outperforming even the R1-14B model. Compared to R1-32B, it delivers a 2.8x wall-clock speedup with comparable performance, advancing the Pareto frontier of test-time scaling efficiency. Our code is available at https://github.com/thu-nics/R2R.
Distilled Decoding 1: One-step Sampling of Image Auto-regressive Models with Flow Matching
Dec 24, 2024Autoregressive (AR) models have achieved state-of-the-art performance in text and image generation but suffer from slow generation due to the token-by-token process. We ask an ambitious question: can a pre-trained AR model be adapted to generate outputs in just one or two steps? If successful, this would significantly advance the development and deployment of AR models. We notice that existing works that try to speed up AR generation by generating multiple tokens at once fundamentally cannot capture the output distribution due to the conditional dependencies between tokens, limiting their effectiveness for few-step generation. To address this, we propose Distilled Decoding (DD), which uses flow matching to create a deterministic mapping from Gaussian distribution to the output distribution of the pre-trained AR model. We then train a network to distill this mapping, enabling few-step generation. DD doesn't need the training data of the original AR model, making it more practical. We evaluate DD on state-of-the-art image AR models and present promising results on ImageNet-256. For VAR, which requires 10-step generation, DD enables one-step generation (6.3$\times$ speed-up), with an acceptable increase in FID from 4.19 to 9.96. For LlamaGen, DD reduces generation from 256 steps to 1, achieving an 217.8$\times$ speed-up with a comparable FID increase from 4.11 to 11.35. In both cases, baseline methods completely fail with FID>100. DD also excels on text-to-image generation, reducing the generation from 256 steps to 2 for LlamaGen with minimal FID increase from 25.70 to 28.95. As the first work to demonstrate the possibility of one-step generation for image AR models, DD challenges the prevailing notion that AR models are inherently slow, and opens up new opportunities for efficient AR generation. The project website is at https://imagination-research.github.io/distilled-decoding.
Efficient Expert Pruning for Sparse Mixture-of-Experts Language Models: Enhancing Performance and Reducing Inference Costs
Jul 01, 2024The rapid advancement of large language models (LLMs) has led to architectures with billions to trillions of parameters, posing significant deployment challenges due to their substantial demands on memory, processing power, and energy consumption. Sparse Mixture-of-Experts (SMoE) architectures have emerged as a solution, activating only a subset of parameters per token, thereby achieving faster inference while maintaining performance. However, SMoE models still face limitations in broader deployment due to their large parameter counts and significant GPU memory requirements. In this work, we introduce a gradient-free evolutionary strategy named EEP (Efficient Expert P}runing) to enhance the pruning of experts in SMoE models. EEP relies solely on model inference (i.e., no gradient computation) and achieves greater sparsity while maintaining or even improving performance on downstream tasks. EEP can be used to reduce both the total number of experts (thus saving GPU memory) and the number of active experts (thus accelerating inference). For example, we demonstrate that pruning up to 75% of experts in Mixtral $8\times7$B-Instruct results in a substantial reduction in parameters with minimal performance loss. Remarkably, we observe improved performance on certain tasks, such as a significant increase in accuracy on the SQuAD dataset (from 53.4% to 75.4%), when pruning half of the experts. With these results, EEP not only lowers the barrier to deploying SMoE models,but also challenges the conventional understanding of model pruning by showing that fewer experts can lead to better task-specific performance without any fine-tuning. Code is available at https://github.com/imagination-research/EEP.
ViDiT-Q: Efficient and Accurate Quantization of Diffusion Transformers for Image and Video Generation
Jun 04, 2024



Diffusion transformers (DiTs) have exhibited remarkable performance in visual generation tasks, such as generating realistic images or videos based on textual instructions. However, larger model sizes and multi-frame processing for video generation lead to increased computational and memory costs, posing challenges for practical deployment on edge devices. Post-Training Quantization (PTQ) is an effective method for reducing memory costs and computational complexity. When quantizing diffusion transformers, we find that applying existing diffusion quantization methods designed for U-Net faces challenges in preserving quality. After analyzing the major challenges for quantizing diffusion transformers, we design an improved quantization scheme: "ViDiT-Q": Video and Image Diffusion Transformer Quantization) to address these issues. Furthermore, we identify highly sensitive layers and timesteps hinder quantization for lower bit-widths. To tackle this, we improve ViDiT-Q with a novel metric-decoupled mixed-precision quantization method (ViDiT-Q-MP). We validate the effectiveness of ViDiT-Q across a variety of text-to-image and video models. While baseline quantization methods fail at W8A8 and produce unreadable content at W4A8, ViDiT-Q achieves lossless W8A8 quantization. ViDiTQ-MP achieves W4A8 with negligible visual quality degradation, resulting in a 2.5x memory optimization and a 1.5x latency speedup.
MixDQ: Memory-Efficient Few-Step Text-to-Image Diffusion Models with Metric-Decoupled Mixed Precision Quantization
May 30, 2024



Diffusion models have achieved significant visual generation quality. However, their significant computational and memory costs pose challenge for their application on resource-constrained mobile devices or even desktop GPUs. Recent few-step diffusion models reduces the inference time by reducing the denoising steps. However, their memory consumptions are still excessive. The Post Training Quantization (PTQ) replaces high bit-width FP representation with low-bit integer values (INT4/8) , which is an effective and efficient technique to reduce the memory cost. However, when applying to few-step diffusion models, existing quantization methods face challenges in preserving both the image quality and text alignment. To address this issue, we propose an mixed-precision quantization framework - MixDQ. Firstly, We design specialized BOS-aware quantization method for highly sensitive text embedding quantization. Then, we conduct metric-decoupled sensitivity analysis to measure the sensitivity of each layer. Finally, we develop an integer-programming-based method to conduct bit-width allocation. While existing quantization methods fall short at W8A8, MixDQ could achieve W8A8 without performance loss, and W4A8 with negligible visual degradation. Compared with FP16, we achieve 3-4x reduction in model size and memory cost, and 1.45x latency speedup.
Linear Combination of Saved Checkpoints Makes Consistency and Diffusion Models Better
Apr 08, 2024



Diffusion Models (DM) and Consistency Models (CM) are two types of popular generative models with good generation quality on various tasks. When training DM and CM, intermediate weight checkpoints are not fully utilized and only the last converged checkpoint is used. In this work, we find that high-quality model weights often lie in a basin which cannot be reached by SGD but can be obtained by proper checkpoint averaging. Based on these observations, we propose LCSC, a simple but effective and efficient method to enhance the performance of DM and CM, by combining checkpoints along the training trajectory with coefficients deduced from evolutionary search. We demonstrate the value of LCSC through two use cases: $\textbf{(a) Reducing training cost.}$ With LCSC, we only need to train DM/CM with fewer number of iterations and/or lower batch sizes to obtain comparable sample quality with the fully trained model. For example, LCSC achieves considerable training speedups for CM (23$\times$ on CIFAR-10 and 15$\times$ on ImageNet-64). $\textbf{(b) Enhancing pre-trained models.}$ Assuming full training is already done, LCSC can further improve the generation quality or speed of the final converged models. For example, LCSC achieves better performance using 1 number of function evaluation (NFE) than the base model with 2 NFE on consistency distillation, and decreases the NFE of DM from 15 to 9 while maintaining the generation quality on CIFAR-10. Our code is available at https://github.com/imagination-research/LCSC.
A Unified Sampling Framework for Solver Searching of Diffusion Probabilistic Models
Dec 12, 2023



Recent years have witnessed the rapid progress and broad application of diffusion probabilistic models (DPMs). Sampling from DPMs can be viewed as solving an ordinary differential equation (ODE). Despite the promising performance, the generation of DPMs usually consumes much time due to the large number of function evaluations (NFE). Though recent works have accelerated the sampling to around 20 steps with high-order solvers, the sample quality with less than 10 NFE can still be improved. In this paper, we propose a unified sampling framework (USF) to study the optional strategies for solver. Under this framework, we further reveal that taking different solving strategies at different timesteps may help further decrease the truncation error, and a carefully designed \emph{solver schedule} has the potential to improve the sample quality by a large margin. Therefore, we propose a new sampling framework based on the exponential integral formulation that allows free choices of solver strategy at each step and design specific decisions for the framework. Moreover, we propose $S^3$, a predictor-based search method that automatically optimizes the solver schedule to get a better time-quality trade-off of sampling. We demonstrate that $S^3$ can find outstanding solver schedules which outperform the state-of-the-art sampling methods on CIFAR-10, CelebA, ImageNet, and LSUN-Bedroom datasets. Specifically, we achieve 2.69 FID with 10 NFE and 6.86 FID with 5 NFE on CIFAR-10 dataset, outperforming the SOTA method significantly. We further apply $S^3$ to Stable-Diffusion model and get an acceleration ratio of 2$\times$, showing the feasibility of sampling in very few steps without retraining the neural network.
OMS-DPM: Optimizing the Model Schedule for Diffusion Probabilistic Models
Jun 15, 2023

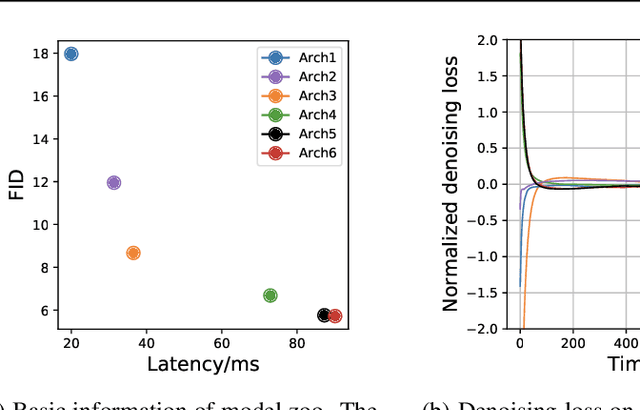

Diffusion probabilistic models (DPMs) are a new class of generative models that have achieved state-of-the-art generation quality in various domains. Despite the promise, one major drawback of DPMs is the slow generation speed due to the large number of neural network evaluations required in the generation process. In this paper, we reveal an overlooked dimension -- model schedule -- for optimizing the trade-off between generation quality and speed. More specifically, we observe that small models, though having worse generation quality when used alone, could outperform large models in certain generation steps. Therefore, unlike the traditional way of using a single model, using different models in different generation steps in a carefully designed \emph{model schedule} could potentially improve generation quality and speed \emph{simultaneously}. We design OMS-DPM, a predictor-based search algorithm, to optimize the model schedule given an arbitrary generation time budget and a set of pre-trained models. We demonstrate that OMS-DPM can find model schedules that improve generation quality and speed than prior state-of-the-art methods across CIFAR-10, CelebA, ImageNet, and LSUN datasets. When applied to the public checkpoints of the Stable Diffusion model, we are able to accelerate the sampling by 2$\times$ while maintaining the generation quality.
Dynamic Ensemble of Low-fidelity Experts: Mitigating NAS "Cold-Start"
Feb 02, 2023Predictor-based Neural Architecture Search (NAS) employs an architecture performance predictor to improve the sample efficiency. However, predictor-based NAS suffers from the severe ``cold-start'' problem, since a large amount of architecture-performance data is required to get a working predictor. In this paper, we focus on exploiting information in cheaper-to-obtain performance estimations (i.e., low-fidelity information) to mitigate the large data requirements of predictor training. Despite the intuitiveness of this idea, we observe that using inappropriate low-fidelity information even damages the prediction ability and different search spaces have different preferences for low-fidelity information types. To solve the problem and better fuse beneficial information provided by different types of low-fidelity information, we propose a novel dynamic ensemble predictor framework that comprises two steps. In the first step, we train different sub-predictors on different types of available low-fidelity information to extract beneficial knowledge as low-fidelity experts. In the second step, we learn a gating network to dynamically output a set of weighting coefficients conditioned on each input neural architecture, which will be used to combine the predictions of different low-fidelity experts in a weighted sum. The overall predictor is optimized on a small set of actual architecture-performance data to fuse the knowledge from different low-fidelity experts to make the final prediction. We conduct extensive experiments across five search spaces with different architecture encoders under various experimental settings. Our method can easily be incorporated into existing predictor-based NAS frameworks to discover better architectures.