 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDLFR-VAE: Dynamic Latent Frame Rate VAE for Video Generation
Paper and Code

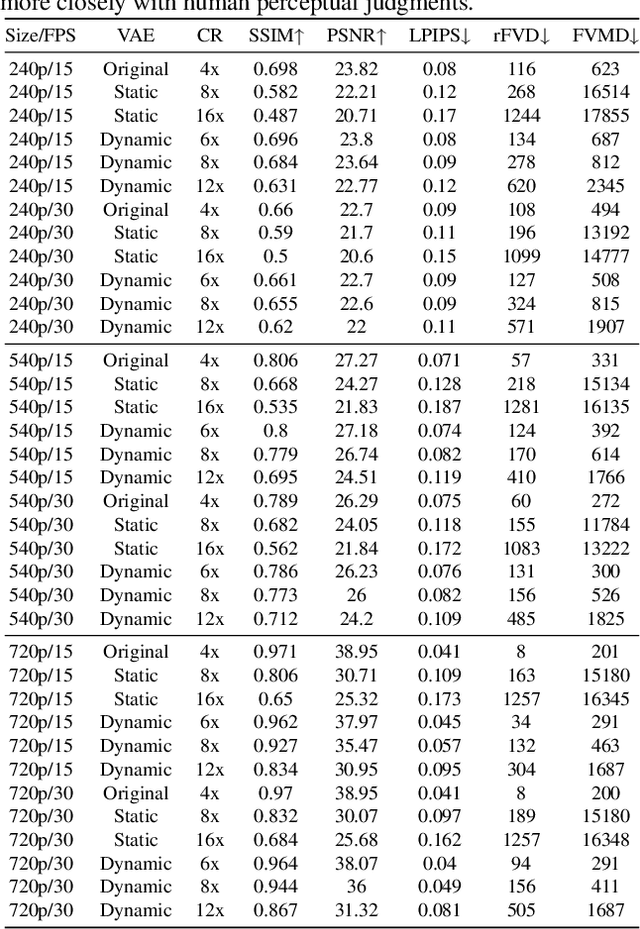

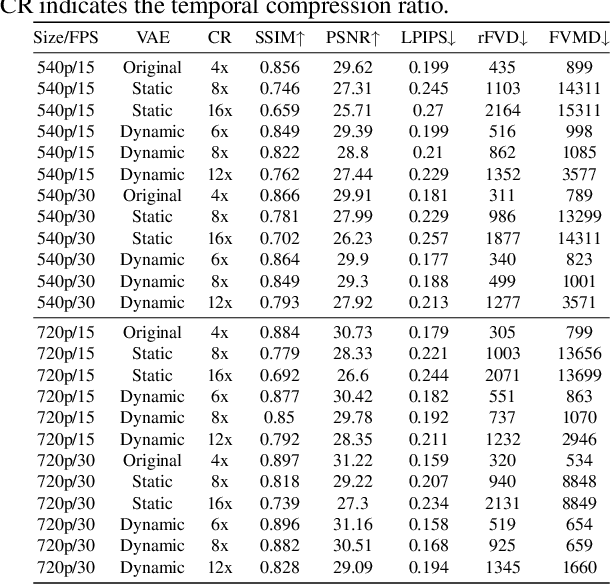
In this paper, we propose the Dynamic Latent Frame Rate VAE (DLFR-VAE), a training-free paradigm that can make use of adaptive temporal compression in latent space. While existing video generative models apply fixed compression rates via pretrained VAE, we observe that real-world video content exhibits substantial temporal non-uniformity, with high-motion segments containing more information than static scenes. Based on this insight, DLFR-VAE dynamically adjusts the latent frame rate according to the content complexity. Specifically, DLFR-VAE comprises two core innovations: (1) A Dynamic Latent Frame Rate Scheduler that partitions videos into temporal chunks and adaptively determines optimal frame rates based on information-theoretic content complexity, and (2) A training-free adaptation mechanism that transforms pretrained VAE architectures into a dynamic VAE that can process features with variable frame rates. Our simple but effective DLFR-VAE can function as a plug-and-play module, seamlessly integrating with existing video generation models and accelerating the video generation process.