 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNVIDIA Nemotron 3: Efficient and Open Intelligence
Dec 24, 2025We introduce the Nemotron 3 family of models - Nano, Super, and Ultra. These models deliver strong agentic, reasoning, and conversational capabilities. The Nemotron 3 family uses a Mixture-of-Experts hybrid Mamba-Transformer architecture to provide best-in-class throughput and context lengths of up to 1M tokens. Super and Ultra models are trained with NVFP4 and incorporate LatentMoE, a novel approach that improves model quality. The two larger models also include MTP layers for faster text generation. All Nemotron 3 models are post-trained using multi-environment reinforcement learning enabling reasoning, multi-step tool use, and support granular reasoning budget control. Nano, the smallest model, outperforms comparable models in accuracy while remaining extremely cost-efficient for inference. Super is optimized for collaborative agents and high-volume workloads such as IT ticket automation. Ultra, the largest model, provides state-of-the-art accuracy and reasoning performance. Nano is released together with its technical report and this white paper, while Super and Ultra will follow in the coming months. We will openly release the model weights, pre- and post-training software, recipes, and all data for which we hold redistribution rights.
Llama-Nemotron: Efficient Reasoning Models
May 02, 2025



We introduce the Llama-Nemotron series of models, an open family of heterogeneous reasoning models that deliver exceptional reasoning capabilities, inference efficiency, and an open license for enterprise use. The family comes in three sizes -- Nano (8B), Super (49B), and Ultra (253B) -- and performs competitively with state-of-the-art reasoning models such as DeepSeek-R1 while offering superior inference throughput and memory efficiency. In this report, we discuss the training procedure for these models, which entails using neural architecture search from Llama 3 models for accelerated inference, knowledge distillation, and continued pretraining, followed by a reasoning-focused post-training stage consisting of two main parts: supervised fine-tuning and large scale reinforcement learning. Llama-Nemotron models are the first open-source models to support a dynamic reasoning toggle, allowing users to switch between standard chat and reasoning modes during inference. To further support open research and facilitate model development, we provide the following resources: 1. We release the Llama-Nemotron reasoning models -- LN-Nano, LN-Super, and LN-Ultra -- under the commercially permissive NVIDIA Open Model License Agreement. 2. We release the complete post-training dataset: Llama-Nemotron-Post-Training-Dataset. 3. We also release our training codebases: NeMo, NeMo-Aligner, and Megatron-LM.
FFN Fusion: Rethinking Sequential Computation in Large Language Models
Mar 24, 2025We introduce FFN Fusion, an architectural optimization technique that reduces sequential computation in large language models by identifying and exploiting natural opportunities for parallelization. Our key insight is that sequences of Feed-Forward Network (FFN) layers, particularly those remaining after the removal of specific attention layers, can often be parallelized with minimal accuracy impact. We develop a principled methodology for identifying and fusing such sequences, transforming them into parallel operations that significantly reduce inference latency while preserving model behavior. Applying these techniques to Llama-3.1-405B-Instruct, we create Llama-Nemotron-Ultra-253B-Base (Ultra-253B-Base), an efficient and soon-to-be publicly available model that achieves a 1.71X speedup in inference latency and 35X lower per-token cost while maintaining strong performance across benchmarks. Through extensive experiments on models from 49B to 253B parameters, we demonstrate that FFN Fusion becomes increasingly effective at larger scales and can complement existing optimization techniques like quantization and pruning. Most intriguingly, we find that even full transformer blocks containing both attention and FFN layers can sometimes be parallelized, suggesting new directions for neural architecture design.
Puzzle: Distillation-Based NAS for Inference-Optimized LLMs
Dec 03, 2024
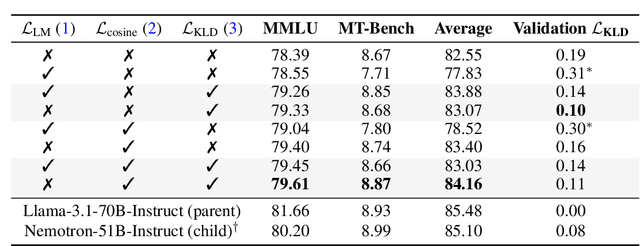

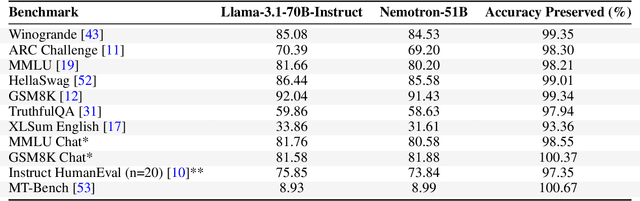
Large language models (LLMs) have demonstrated remarkable capabilities, but their adoption is limited by high computational costs during inference. While increasing parameter counts enhances accuracy, it also widens the gap between state-of-the-art capabilities and practical deployability. We present Puzzle, a framework to accelerate LLM inference on specific hardware while preserving their capabilities. Through an innovative application of neural architecture search (NAS) at an unprecedented scale, Puzzle systematically optimizes models with tens of billions of parameters under hardware constraints. Our approach utilizes blockwise local knowledge distillation (BLD) for parallel architecture exploration and employs mixed-integer programming for precise constraint optimization. We demonstrate the real-world impact of our framework through Llama-3.1-Nemotron-51B-Instruct (Nemotron-51B), a publicly available model derived from Llama-3.1-70B-Instruct. Nemotron-51B achieves a 2.17x inference throughput speedup, fitting on a single NVIDIA H100 GPU while preserving 98.4% of the original model's capabilities. Nemotron-51B currently stands as the most accurate language model capable of inference on a single GPU with large batch sizes. Remarkably, this transformation required just 45B training tokens, compared to over 15T tokens used for the 70B model it was derived from. This establishes a new paradigm where powerful models can be optimized for efficient deployment with only negligible compromise of their capabilities, demonstrating that inference performance, not parameter count alone, should guide model selection. With the release of Nemotron-51B and the presentation of the Puzzle framework, we provide practitioners immediate access to state-of-the-art language modeling capabilities at significantly reduced computational costs.
Diverse Demonstrations Improve In-context Compositional Generalization
Dec 20, 2022In-context learning has shown great success in i.i.d semantic parsing splits, where the training and test sets are drawn from the same distribution. In this setup, models are typically prompted with demonstrations that are similar to the input question. However, in the setup of compositional generalization, where models are tested on outputs with structures that are absent from the training set, selecting similar demonstrations is insufficient, as often no example will be similar enough to the input. In this work, we propose a method to select diverse demonstrations that aims to collectively cover all of the structures required in the output program, in order to encourage the model to generalize to new structures from these demonstrations. We empirically show that combining diverse demonstrations with in-context learning substantially improves performance across three compositional generalization semantic parsing datasets in the pure in-context learning setup and when combined with finetuning.