 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNemotron 3 Nano Omni: Efficient and Open Multimodal Intelligence
Apr 27, 2026We introduce Nemotron 3 Nano Omni, the latest model in the Nemotron multimodal series and the first to natively support audio inputs alongside text, images, and video. Nemotron 3 Nano Omni delivers consistent accuracy improvements over its predecessor, Nemotron Nano V2 VL, across all modalities, enabled by advances in architecture, training data and recipes. In particular, Nemotron 3 delivers leading results in real-world document understanding, long audio-video comprehension, and agentic computer use. Built on the highly efficient Nemotron 3 Nano 30B-A3B backbone, Nemotron 3 Nano Omni further incorporates innovative multimodal token-reduction techniques to deliver substantially lower inference latency and higher throughput than other models of similar size. We are releasing model checkpoints in BF16, FP8, and FP4 formats, along with portions of the training data and codebase to facilitate further research and development.
Nemotron 3 Super: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Apr 14, 2026We describe the pre-training, post-training, and quantization of Nemotron 3 Super, a 120 billion (active 12 billion) parameter hybrid Mamba-Attention Mixture-of-Experts model. Nemotron 3 Super is the first model in the Nemotron 3 family to 1) be pre-trained in NVFP4, 2) leverage LatentMoE, a new Mixture-of-Experts architecture that optimizes for both accuracy per FLOP and accuracy per parameter, and 3) include MTP layers for inference acceleration through native speculative decoding. We pre-trained Nemotron 3 Super on 25 trillion tokens followed by post-training using supervised fine tuning (SFT) and reinforcement learning (RL). The final model supports up to 1M context length and achieves comparable accuracy on common benchmarks, while also achieving up to 2.2x and 7.5x higher inference throughput compared to GPT-OSS-120B and Qwen3.5-122B, respectively. Nemotron 3 Super datasets, along with the base, post-trained, and quantized checkpoints, are open-sourced on HuggingFace.
NVIDIA Nemotron 3: Efficient and Open Intelligence
Dec 24, 2025We introduce the Nemotron 3 family of models - Nano, Super, and Ultra. These models deliver strong agentic, reasoning, and conversational capabilities. The Nemotron 3 family uses a Mixture-of-Experts hybrid Mamba-Transformer architecture to provide best-in-class throughput and context lengths of up to 1M tokens. Super and Ultra models are trained with NVFP4 and incorporate LatentMoE, a novel approach that improves model quality. The two larger models also include MTP layers for faster text generation. All Nemotron 3 models are post-trained using multi-environment reinforcement learning enabling reasoning, multi-step tool use, and support granular reasoning budget control. Nano, the smallest model, outperforms comparable models in accuracy while remaining extremely cost-efficient for inference. Super is optimized for collaborative agents and high-volume workloads such as IT ticket automation. Ultra, the largest model, provides state-of-the-art accuracy and reasoning performance. Nano is released together with its technical report and this white paper, while Super and Ultra will follow in the coming months. We will openly release the model weights, pre- and post-training software, recipes, and all data for which we hold redistribution rights.
Nemotron 3 Nano: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Dec 23, 2025We present Nemotron 3 Nano 30B-A3B, a Mixture-of-Experts hybrid Mamba-Transformer language model. Nemotron 3 Nano was pretrained on 25 trillion text tokens, including more than 3 trillion new unique tokens over Nemotron 2, followed by supervised fine tuning and large-scale RL on diverse environments. Nemotron 3 Nano achieves better accuracy than our previous generation Nemotron 2 Nano while activating less than half of the parameters per forward pass. It achieves up to 3.3x higher inference throughput than similarly-sized open models like GPT-OSS-20B and Qwen3-30B-A3B-Thinking-2507, while also being more accurate on popular benchmarks. Nemotron 3 Nano demonstrates enhanced agentic, reasoning, and chat abilities and supports context lengths up to 1M tokens. We release both our pretrained Nemotron 3 Nano 30B-A3B Base and post-trained Nemotron 3 Nano 30B-A3B checkpoints on Hugging Face.
NVIDIA Nemotron Nano V2 VL
Nov 07, 2025We introduce Nemotron Nano V2 VL, the latest model of the Nemotron vision-language series designed for strong real-world document understanding, long video comprehension, and reasoning tasks. Nemotron Nano V2 VL delivers significant improvements over our previous model, Llama-3.1-Nemotron-Nano-VL-8B, across all vision and text domains through major enhancements in model architecture, datasets, and training recipes. Nemotron Nano V2 VL builds on Nemotron Nano V2, a hybrid Mamba-Transformer LLM, and innovative token reduction techniques to achieve higher inference throughput in long document and video scenarios. We are releasing model checkpoints in BF16, FP8, and FP4 formats and sharing large parts of our datasets, recipes and training code.
Llama-Nemotron: Efficient Reasoning Models
May 02, 2025



We introduce the Llama-Nemotron series of models, an open family of heterogeneous reasoning models that deliver exceptional reasoning capabilities, inference efficiency, and an open license for enterprise use. The family comes in three sizes -- Nano (8B), Super (49B), and Ultra (253B) -- and performs competitively with state-of-the-art reasoning models such as DeepSeek-R1 while offering superior inference throughput and memory efficiency. In this report, we discuss the training procedure for these models, which entails using neural architecture search from Llama 3 models for accelerated inference, knowledge distillation, and continued pretraining, followed by a reasoning-focused post-training stage consisting of two main parts: supervised fine-tuning and large scale reinforcement learning. Llama-Nemotron models are the first open-source models to support a dynamic reasoning toggle, allowing users to switch between standard chat and reasoning modes during inference. To further support open research and facilitate model development, we provide the following resources: 1. We release the Llama-Nemotron reasoning models -- LN-Nano, LN-Super, and LN-Ultra -- under the commercially permissive NVIDIA Open Model License Agreement. 2. We release the complete post-training dataset: Llama-Nemotron-Post-Training-Dataset. 3. We also release our training codebases: NeMo, NeMo-Aligner, and Megatron-LM.
AutoReply: Detecting Nonsense in Dialogue Introspectively with Discriminative Replies
Nov 22, 2022
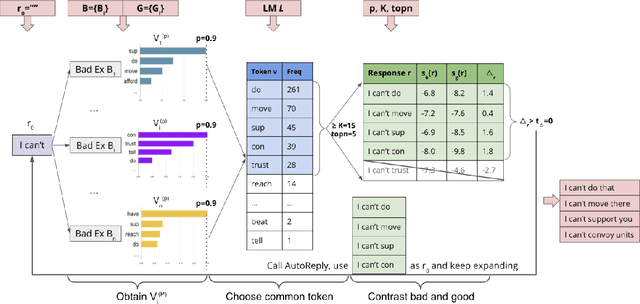
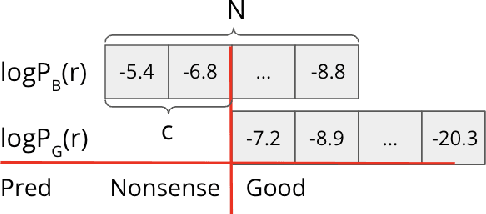

Existing approaches built separate classifiers to detect nonsense in dialogues. In this paper, we show that without external classifiers, dialogue models can detect errors in their own messages introspectively, by calculating the likelihood of replies that are indicative of poor messages. For example, if an agent believes its partner is likely to respond "I don't understand" to a candidate message, that message may not make sense, so an alternative message should be chosen. We evaluate our approach on a dataset from the game Diplomacy, which contains long dialogues richly grounded in the game state, on which existing models make many errors. We first show that hand-crafted replies can be effective for the task of detecting nonsense in applications as complex as Diplomacy. We then design AutoReply, an algorithm to search for such discriminative replies automatically, given a small number of annotated dialogue examples. We find that AutoReply-generated replies outperform handcrafted replies and perform on par with carefully fine-tuned large supervised models. Results also show that one single reply without much computation overheads can also detect dialogue nonsense reasonably well.
XLEnt: Mining a Large Cross-lingual Entity Dataset with Lexical-Semantic-Phonetic Word Alignment
Apr 17, 2021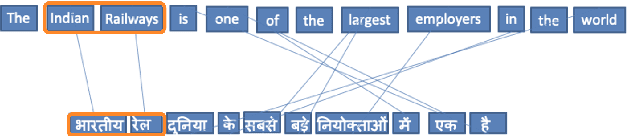
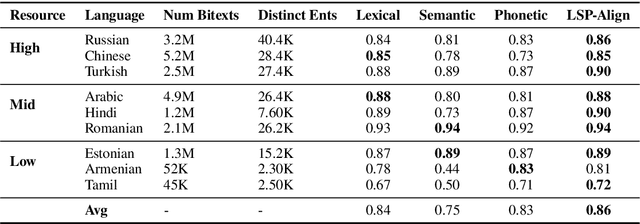
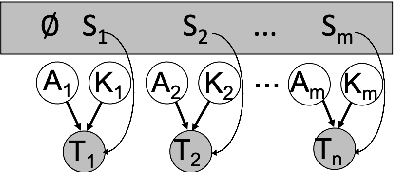
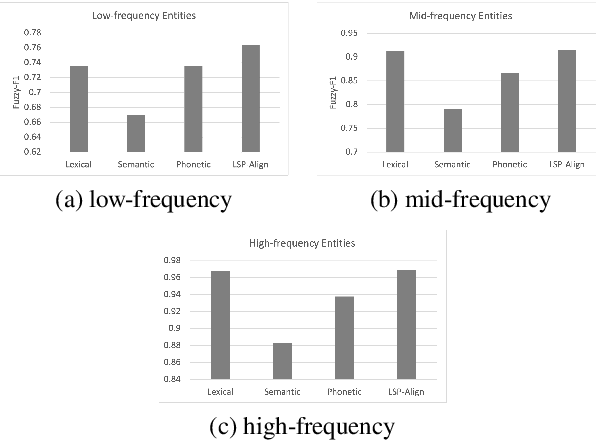
Cross-lingual named-entity lexicon are an important resource to multilingual NLP tasks such as machine translation and cross-lingual wikification. While knowledge bases contain a large number of entities in high-resource languages such as English and French, corresponding entities for lower-resource languages are often missing. To address this, we propose Lexical-Semantic-Phonetic Align (LSP-Align), a technique to automatically mine cross-lingual entity lexicon from the web. We demonstrate LSP-Align outperforms baselines at extracting cross-lingual entity pairs and mine 164 million entity pairs from 120 different languages aligned with English. We release these cross-lingual entity pairs along with the massively multilingual tagged named entity corpus as a resource to the NLP community.
Towards Understanding the Optimal Behaviors of Deep Active Learning Algorithms
Dec 29, 2020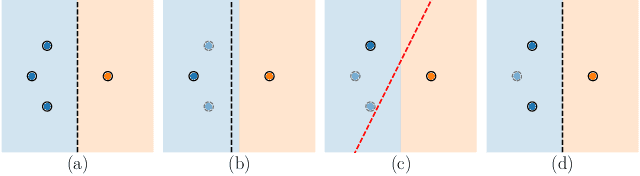

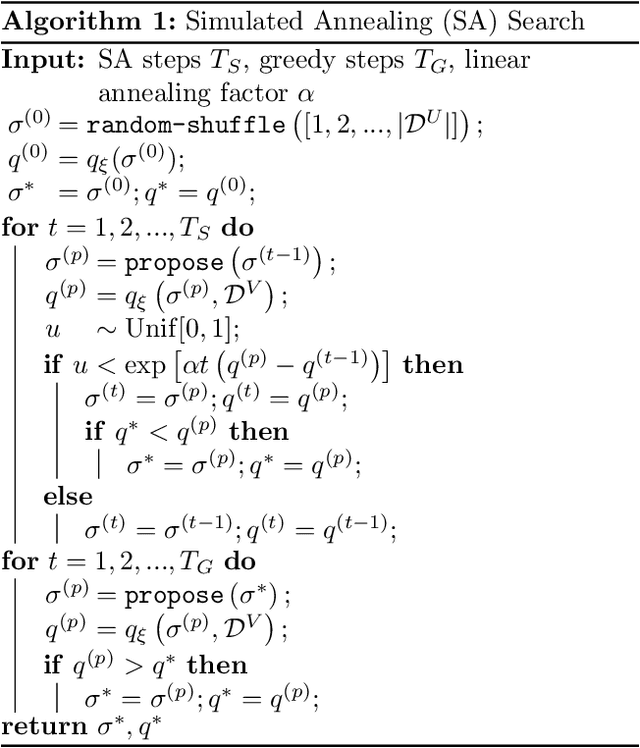
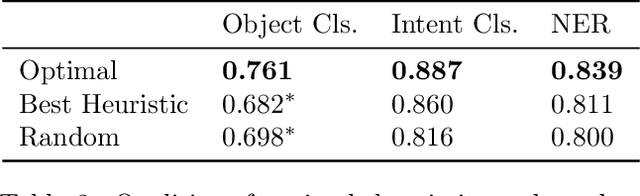
Active learning (AL) algorithms may achieve better performance with fewer data because the model guides the data selection process. While many algorithms have been proposed, there is little study on what the optimal AL algorithm looks like, which would help researchers understand where their models fall short and iterate on the design. In this paper, we present a simulated annealing algorithm to search for this optimal oracle and analyze it for several different tasks. We present several qualitative and quantitative insights into the optimal behavior and contrast this behavior with those of various heuristics. When augmented by with one particular insight, heuristics perform consistently better. We hope that our findings can better inform future active learning research. The code for the experiments is available at https://github.com/YilunZhou/optimal-active-learning.