 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman-aligned Chess with a Bit of Search
Oct 04, 2024
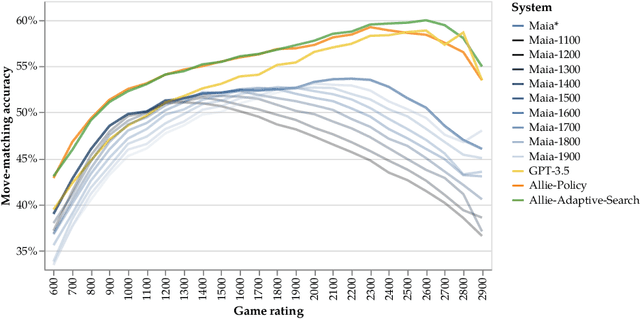

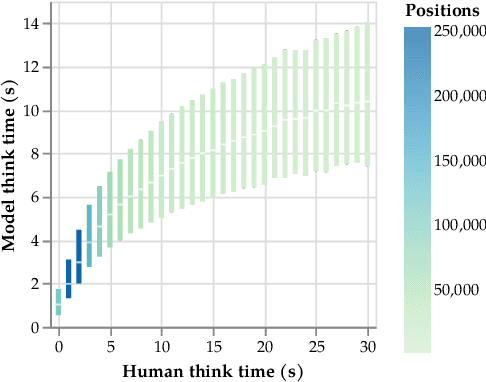
Chess has long been a testbed for AI's quest to match human intelligence, and in recent years, chess AI systems have surpassed the strongest humans at the game. However, these systems are not human-aligned; they are unable to match the skill levels of all human partners or model human-like behaviors beyond piece movement. In this paper, we introduce Allie, a chess-playing AI designed to bridge the gap between artificial and human intelligence in this classic game. Allie is trained on log sequences of real chess games to model the behaviors of human chess players across the skill spectrum, including non-move behaviors such as pondering times and resignations In offline evaluations, we find that Allie exhibits humanlike behavior: it outperforms the existing state-of-the-art in human chess move prediction and "ponders" at critical positions. The model learns to reliably assign reward at each game state, which can be used at inference as a reward function in a novel time-adaptive Monte-Carlo tree search (MCTS) procedure, where the amount of search depends on how long humans would think in the same positions. Adaptive search enables remarkable skill calibration; in a large-scale online evaluation against players with ratings from 1000 to 2600 Elo, our adaptive search method leads to a skill gap of only 49 Elo on average, substantially outperforming search-free and standard MCTS baselines. Against grandmaster-level (2500 Elo) opponents, Allie with adaptive search exhibits the strength of a fellow grandmaster, all while learning exclusively from humans.
Modeling Boundedly Rational Agents with Latent Inference Budgets
Dec 07, 2023We study the problem of modeling a population of agents pursuing unknown goals subject to unknown computational constraints. In standard models of bounded rationality, sub-optimal decision-making is simulated by adding homoscedastic noise to optimal decisions rather than explicitly simulating constrained inference. In this work, we introduce a latent inference budget model (L-IBM) that models agents' computational constraints explicitly, via a latent variable (inferred jointly with a model of agents' goals) that controls the runtime of an iterative inference algorithm. L-IBMs make it possible to learn agent models using data from diverse populations of suboptimal actors. In three modeling tasks -- inferring navigation goals from routes, inferring communicative intents from human utterances, and predicting next moves in human chess games -- we show that L-IBMs match or outperform Boltzmann models of decision-making under uncertainty. Inferred inference budgets are themselves meaningful, efficient to compute, and correlated with measures of player skill, partner skill and task difficulty.
Regularized Conventions: Equilibrium Computation as a Model of Pragmatic Reasoning
Nov 16, 2023
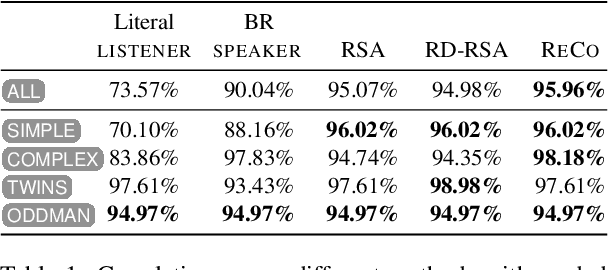

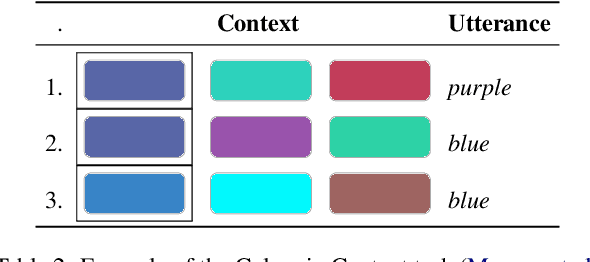
We present a model of pragmatic language understanding, where utterances are produced and understood by searching for regularized equilibria of signaling games. In this model (which we call ReCo, for Regularized Conventions), speakers and listeners search for contextually appropriate utterance--meaning mappings that are both close to game-theoretically optimal conventions and close to a shared, ''default'' semantics. By characterizing pragmatic communication as equilibrium search, we obtain principled sampling algorithms and formal guarantees about the trade-off between communicative success and naturalness. Across several datasets capturing real and idealized human judgments about pragmatic implicatures, ReCo matches or improves upon predictions made by best response and rational speech act models of language understanding.
The Consensus Game: Language Model Generation via Equilibrium Search
Oct 13, 2023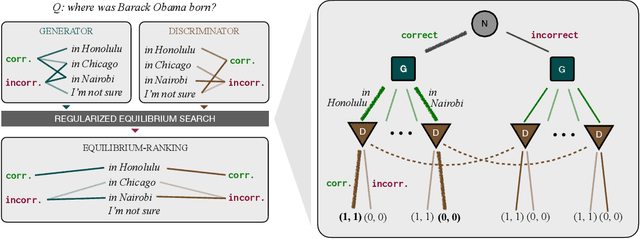
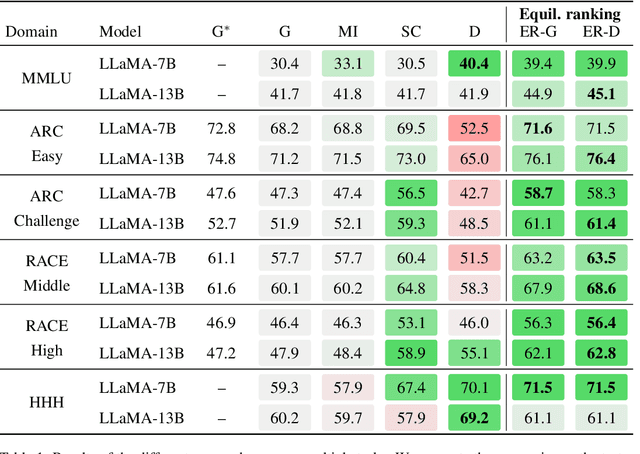
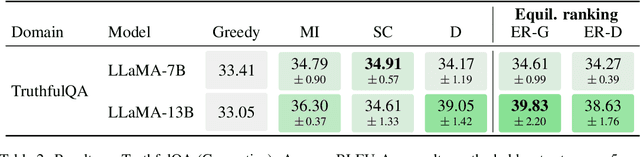
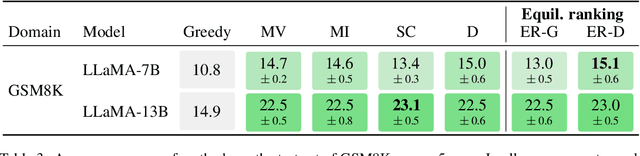
When applied to question answering and other text generation tasks, language models (LMs) may be queried generatively (by sampling answers from their output distribution) or discriminatively (by using them to score or rank a set of candidate outputs). These procedures sometimes yield very different predictions. How do we reconcile mutually incompatible scoring procedures to obtain coherent LM predictions? We introduce a new, a training-free, game-theoretic procedure for language model decoding. Our approach casts language model decoding as a regularized imperfect-information sequential signaling game - which we term the CONSENSUS GAME - in which a GENERATOR seeks to communicate an abstract correctness parameter using natural language sentences to a DISCRIMINATOR. We develop computational procedures for finding approximate equilibria of this game, resulting in a decoding algorithm we call EQUILIBRIUM-RANKING. Applied to a large number of tasks (including reading comprehension, commonsense reasoning, mathematical problem-solving, and dialog), EQUILIBRIUM-RANKING consistently, and sometimes substantially, improves performance over existing LM decoding procedures - on multiple benchmarks, we observe that applying EQUILIBRIUM-RANKING to LLaMA-7B outperforms the much larger LLaMA-65B and PaLM-540B models. These results highlight the promise of game-theoretic tools for addressing fundamental challenges of truthfulness and consistency in LMs.
AutoReply: Detecting Nonsense in Dialogue Introspectively with Discriminative Replies
Nov 22, 2022
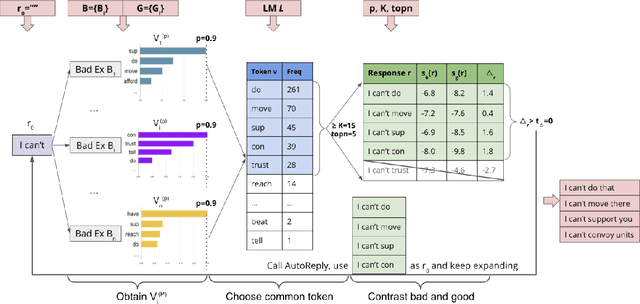
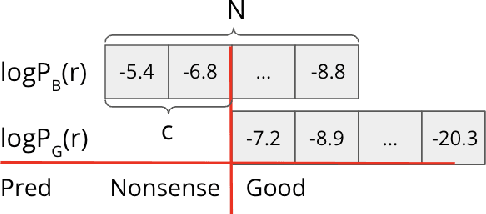

Existing approaches built separate classifiers to detect nonsense in dialogues. In this paper, we show that without external classifiers, dialogue models can detect errors in their own messages introspectively, by calculating the likelihood of replies that are indicative of poor messages. For example, if an agent believes its partner is likely to respond "I don't understand" to a candidate message, that message may not make sense, so an alternative message should be chosen. We evaluate our approach on a dataset from the game Diplomacy, which contains long dialogues richly grounded in the game state, on which existing models make many errors. We first show that hand-crafted replies can be effective for the task of detecting nonsense in applications as complex as Diplomacy. We then design AutoReply, an algorithm to search for such discriminative replies automatically, given a small number of annotated dialogue examples. We find that AutoReply-generated replies outperform handcrafted replies and perform on par with carefully fine-tuned large supervised models. Results also show that one single reply without much computation overheads can also detect dialogue nonsense reasonably well.
Mastering the Game of No-Press Diplomacy via Human-Regularized Reinforcement Learning and Planning
Oct 11, 2022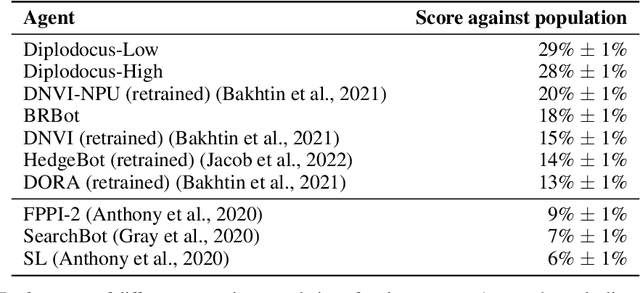

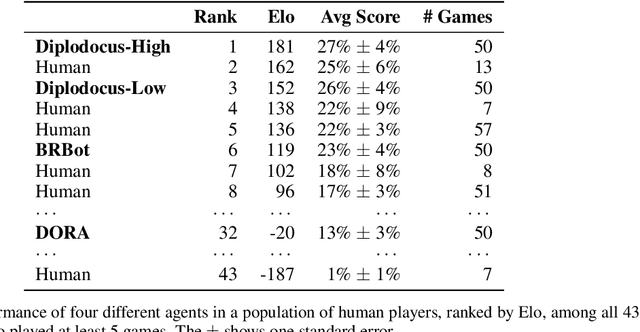
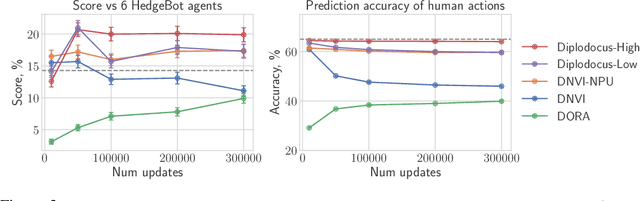
No-press Diplomacy is a complex strategy game involving both cooperation and competition that has served as a benchmark for multi-agent AI research. While self-play reinforcement learning has resulted in numerous successes in purely adversarial games like chess, Go, and poker, self-play alone is insufficient for achieving optimal performance in domains involving cooperation with humans. We address this shortcoming by first introducing a planning algorithm we call DiL-piKL that regularizes a reward-maximizing policy toward a human imitation-learned policy. We prove that this is a no-regret learning algorithm under a modified utility function. We then show that DiL-piKL can be extended into a self-play reinforcement learning algorithm we call RL-DiL-piKL that provides a model of human play while simultaneously training an agent that responds well to this human model. We used RL-DiL-piKL to train an agent we name Diplodocus. In a 200-game no-press Diplomacy tournament involving 62 human participants spanning skill levels from beginner to expert, two Diplodocus agents both achieved a higher average score than all other participants who played more than two games, and ranked first and third according to an Elo ratings model.
Modeling Strong and Human-Like Gameplay with KL-Regularized Search
Dec 14, 2021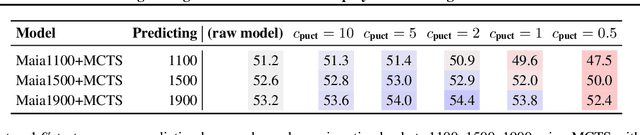
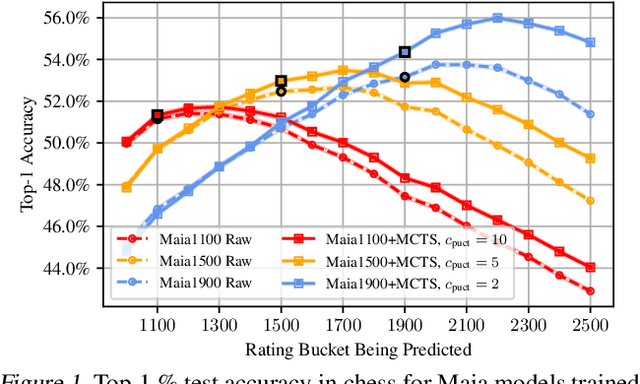

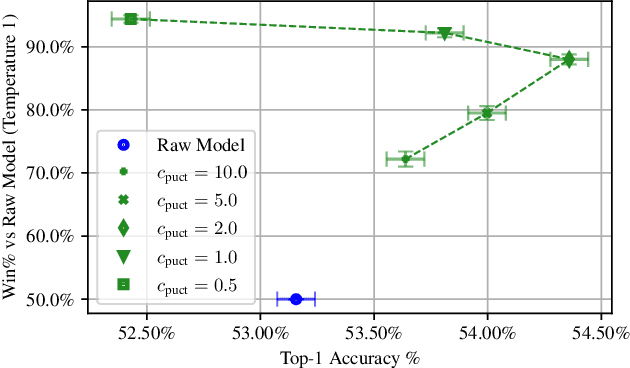
We consider the task of building strong but human-like policies in multi-agent decision-making problems, given examples of human behavior. Imitation learning is effective at predicting human actions but may not match the strength of expert humans, while self-play learning and search techniques (e.g. AlphaZero) lead to strong performance but may produce policies that are difficult for humans to understand and coordinate with. We show in chess and Go that regularizing search policies based on the KL divergence from an imitation-learned policy by applying Monte Carlo tree search produces policies that have higher human prediction accuracy and are stronger than the imitation policy. We then introduce a novel regret minimization algorithm that is regularized based on the KL divergence from an imitation-learned policy, and show that applying this algorithm to no-press Diplomacy yields a policy that maintains the same human prediction accuracy as imitation learning while being substantially stronger.
Multitasking Inhibits Semantic Drift
Apr 15, 2021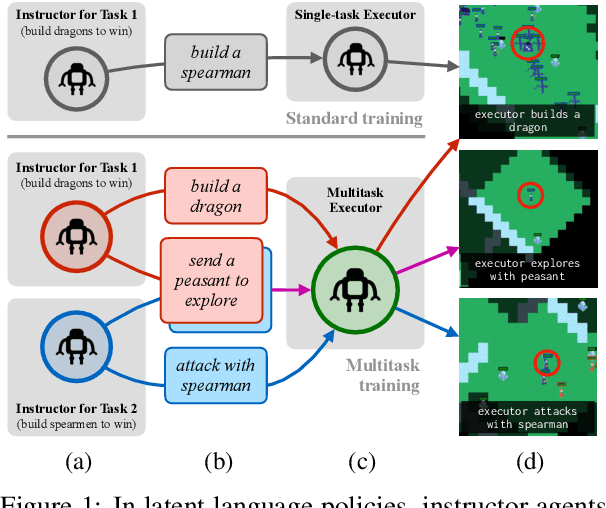



When intelligent agents communicate to accomplish shared goals, how do these goals shape the agents' language? We study the dynamics of learning in latent language policies (LLPs), in which instructor agents generate natural-language subgoal descriptions and executor agents map these descriptions to low-level actions. LLPs can solve challenging long-horizon reinforcement learning problems and provide a rich model for studying task-oriented language use. But previous work has found that LLP training is prone to semantic drift (use of messages in ways inconsistent with their original natural language meanings). Here, we demonstrate theoretically and empirically that multitask training is an effective counter to this problem: we prove that multitask training eliminates semantic drift in a well-studied family of signaling games, and show that multitask training of neural LLPs in a complex strategy game reduces drift and while improving sample efficiency.
Straight to the Tree: Constituency Parsing with Neural Syntactic Distance
Jun 11, 2018


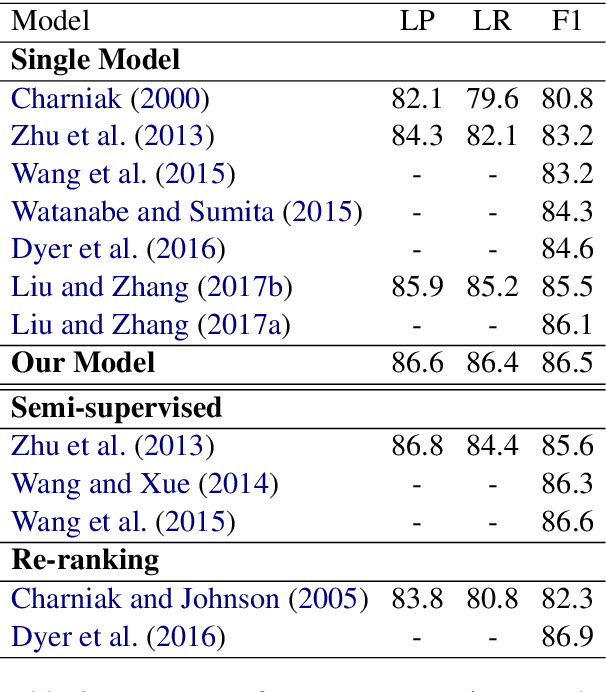
In this work, we propose a novel constituency parsing scheme. The model predicts a vector of real-valued scalars, named syntactic distances, for each split position in the input sentence. The syntactic distances specify the order in which the split points will be selected, recursively partitioning the input, in a top-down fashion. Compared to traditional shift-reduce parsing schemes, our approach is free from the potential problem of compounding errors, while being faster and easier to parallelize. Our model achieves competitive performance amongst single model, discriminative parsers in the PTB dataset and outperforms previous models in the CTB dataset.
Boundary-Seeking Generative Adversarial Networks
Feb 21, 2018

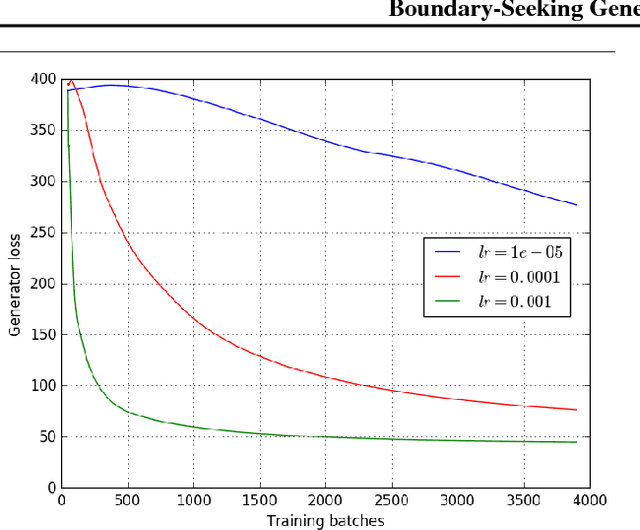
Generative adversarial networks (GANs) are a learning framework that rely on training a discriminator to estimate a measure of difference between a target and generated distributions. GANs, as normally formulated, rely on the generated samples being completely differentiable w.r.t. the generative parameters, and thus do not work for discrete data. We introduce a method for training GANs with discrete data that uses the estimated difference measure from the discriminator to compute importance weights for generated samples, thus providing a policy gradient for training the generator. The importance weights have a strong connection to the decision boundary of the discriminator, and we call our method boundary-seeking GANs (BGANs). We demonstrate the effectiveness of the proposed algorithm with discrete image and character-based natural language generation. In addition, the boundary-seeking objective extends to continuous data, which can be used to improve stability of training, and we demonstrate this on Celeba, Large-scale Scene Understanding (LSUN) bedrooms, and Imagenet without conditioning.