 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRankFlow: A Multi-Role Collaborative Reranking Workflow Utilizing Large Language Models
Feb 04, 2025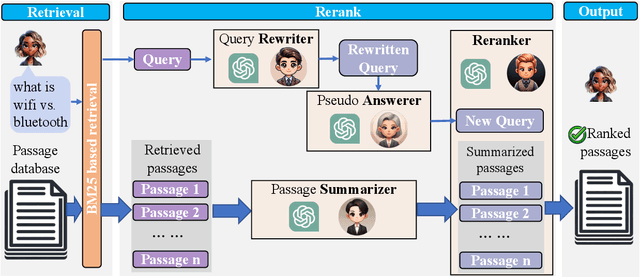
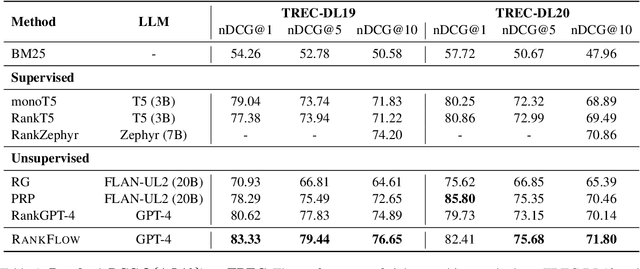
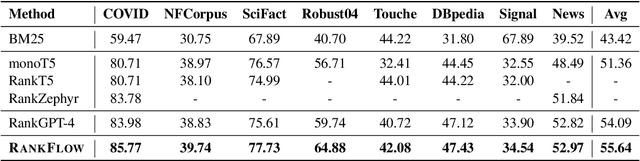
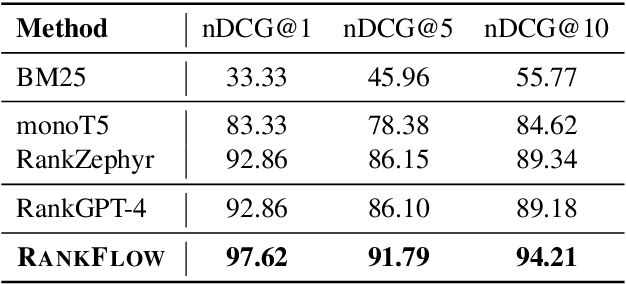
In an Information Retrieval (IR) system, reranking plays a critical role by sorting candidate passages according to their relevance to a specific query. This process demands a nuanced understanding of the variations among passages linked to the query. In this work, we introduce RankFlow, a multi-role reranking workflow that leverages the capabilities of Large Language Models (LLMs) and role specializations to improve reranking performance. RankFlow enlists LLMs to fulfill four distinct roles: the query Rewriter, the pseudo Answerer, the passage Summarizer, and the Reranker. This orchestrated approach enables RankFlow to: (1) accurately interpret queries, (2) draw upon LLMs' extensive pre-existing knowledge, (3) distill passages into concise versions, and (4) assess passages in a comprehensive manner, resulting in notably better reranking results. Our experimental results reveal that RankFlow outperforms existing leading approaches on widely recognized IR benchmarks, such as TREC-DL, BEIR, and NovelEval. Additionally, we investigate the individual contributions of each role in RankFlow. Code is available at https://github.com/jincan333/RankFlow.
GALOT: Generative Active Learning via Optimizable Zero-shot Text-to-image Generation
Dec 18, 2024Active Learning (AL) represents a crucial methodology within machine learning, emphasizing the identification and utilization of the most informative samples for efficient model training. However, a significant challenge of AL is its dependence on the limited labeled data samples and data distribution, resulting in limited performance. To address this limitation, this paper integrates the zero-shot text-to-image (T2I) synthesis and active learning by designing a novel framework that can efficiently train a machine learning (ML) model sorely using the text description. Specifically, we leverage the AL criteria to optimize the text inputs for generating more informative and diverse data samples, annotated by the pseudo-label crafted from text, then served as a synthetic dataset for active learning. This approach reduces the cost of data collection and annotation while increasing the efficiency of model training by providing informative training samples, enabling a novel end-to-end ML task from text description to vision models. Through comprehensive evaluations, our framework demonstrates consistent and significant improvements over traditional AL methods.
Universally Harmonizing Differential Privacy Mechanisms for Federated Learning: Boosting Accuracy and Convergence
Jul 24, 2024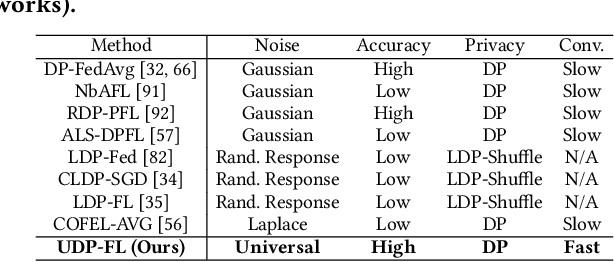
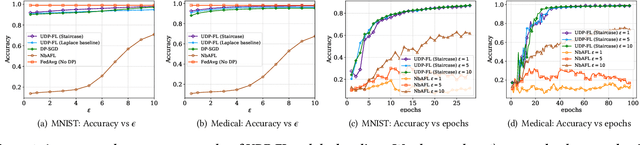
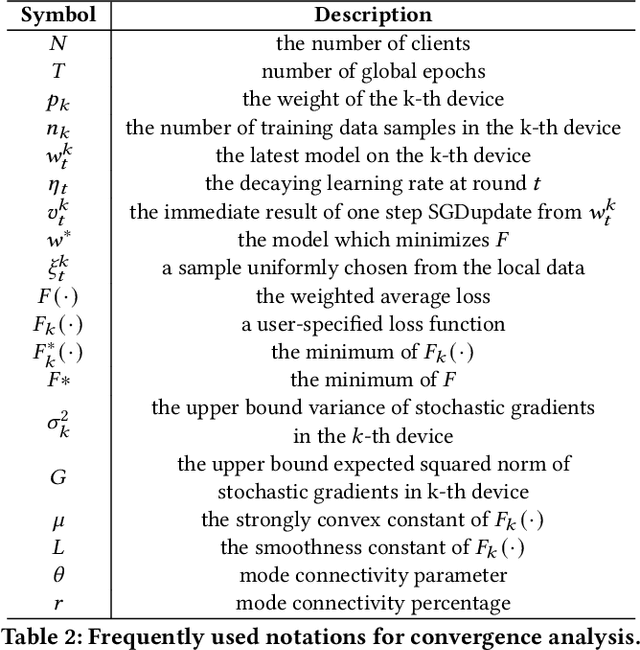
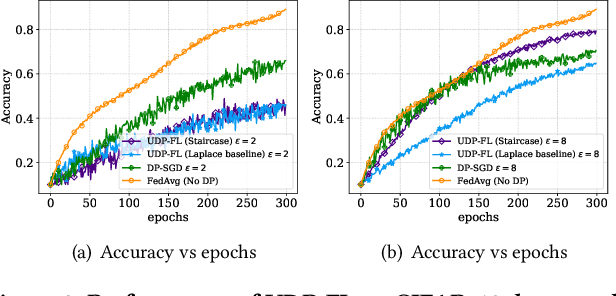
Differentially private federated learning (DP-FL) is a promising technique for collaborative model training while ensuring provable privacy for clients. However, optimizing the tradeoff between privacy and accuracy remains a critical challenge. To our best knowledge, we propose the first DP-FL framework (namely UDP-FL), which universally harmonizes any randomization mechanism (e.g., an optimal one) with the Gaussian Moments Accountant (viz. DP-SGD) to significantly boost accuracy and convergence. Specifically, UDP-FL demonstrates enhanced model performance by mitigating the reliance on Gaussian noise. The key mediator variable in this transformation is the R\'enyi Differential Privacy notion, which is carefully used to harmonize privacy budgets. We also propose an innovative method to theoretically analyze the convergence for DP-FL (including our UDP-FL ) based on mode connectivity analysis. Moreover, we evaluate our UDP-FL through extensive experiments benchmarked against state-of-the-art (SOTA) methods, demonstrating superior performance on both privacy guarantees and model performance. Notably, UDP-FL exhibits substantial resilience against different inference attacks, indicating a significant advance in safeguarding sensitive data in federated learning environments.