 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRankFlow: A Multi-Role Collaborative Reranking Workflow Utilizing Large Language Models
Feb 04, 2025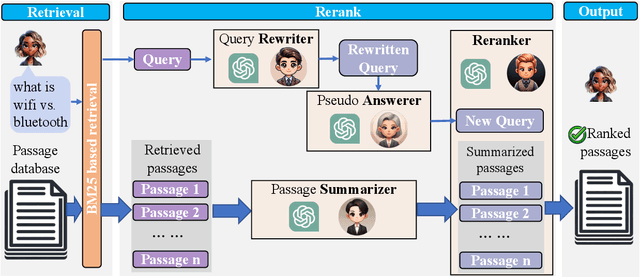
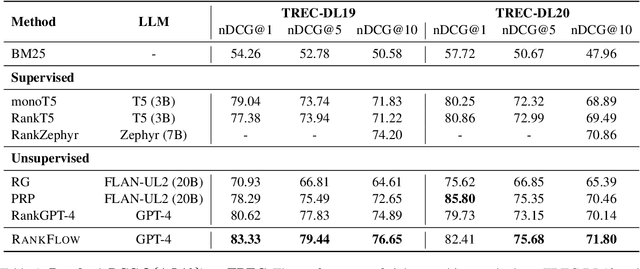
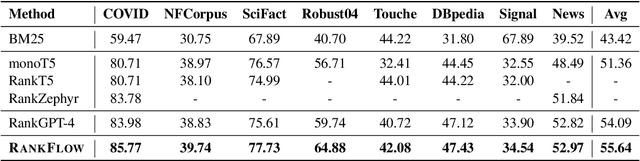
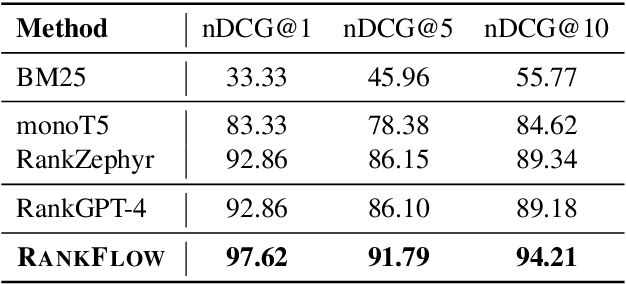
In an Information Retrieval (IR) system, reranking plays a critical role by sorting candidate passages according to their relevance to a specific query. This process demands a nuanced understanding of the variations among passages linked to the query. In this work, we introduce RankFlow, a multi-role reranking workflow that leverages the capabilities of Large Language Models (LLMs) and role specializations to improve reranking performance. RankFlow enlists LLMs to fulfill four distinct roles: the query Rewriter, the pseudo Answerer, the passage Summarizer, and the Reranker. This orchestrated approach enables RankFlow to: (1) accurately interpret queries, (2) draw upon LLMs' extensive pre-existing knowledge, (3) distill passages into concise versions, and (4) assess passages in a comprehensive manner, resulting in notably better reranking results. Our experimental results reveal that RankFlow outperforms existing leading approaches on widely recognized IR benchmarks, such as TREC-DL, BEIR, and NovelEval. Additionally, we investigate the individual contributions of each role in RankFlow. Code is available at https://github.com/jincan333/RankFlow.
National Origin Discrimination in Deep-learning-powered Automated Resume Screening
Jul 13, 2023Many companies and organizations have started to use some form of AIenabled auto mated tools to assist in their hiring process, e.g. screening resumes, interviewing candi dates, performance evaluation. While those AI tools have greatly improved human re source operations efficiency and provided conveniences to job seekers as well, there are increasing concerns on unfair treatment to candidates, caused by underlying bias in AI systems. Laws around equal opportunity and fairness, like GDPR, CCPA, are introduced or under development, in attempt to regulate AI. However, it is difficult to implement AI regulations in practice, as technologies are constantly advancing and the risk perti nent to their applications can fail to be recognized. This study examined deep learning methods, a recent technology breakthrough, with focus on their application to automated resume screening. One impressive performance of deep learning methods is the represen tation of individual words as lowdimensional numerical vectors, called word embedding, which are learned from aggregated global wordword cooccurrence statistics from a cor pus, like Wikipedia or Google news. The resulting word representations possess interest ing linear substructures of the word vector space and have been widely used in down stream tasks, like resume screening. However, word embedding inherits and reinforces the stereotyping from the training corpus, as deep learning models essentially learn a probability distribution of words and their relations from history data. Our study finds out that if we rely on such deeplearningpowered automated resume screening tools, it may lead to decisions favoring or disfavoring certain demographic groups and raise eth ical, even legal, concerns. To address the issue, we developed bias mitigation method. Extensive experiments on real candidate resumes are conducted to validate our study