 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGALOT: Generative Active Learning via Optimizable Zero-shot Text-to-image Generation
Dec 18, 2024Active Learning (AL) represents a crucial methodology within machine learning, emphasizing the identification and utilization of the most informative samples for efficient model training. However, a significant challenge of AL is its dependence on the limited labeled data samples and data distribution, resulting in limited performance. To address this limitation, this paper integrates the zero-shot text-to-image (T2I) synthesis and active learning by designing a novel framework that can efficiently train a machine learning (ML) model sorely using the text description. Specifically, we leverage the AL criteria to optimize the text inputs for generating more informative and diverse data samples, annotated by the pseudo-label crafted from text, then served as a synthetic dataset for active learning. This approach reduces the cost of data collection and annotation while increasing the efficiency of model training by providing informative training samples, enabling a novel end-to-end ML task from text description to vision models. Through comprehensive evaluations, our framework demonstrates consistent and significant improvements over traditional AL methods.
Universally Harmonizing Differential Privacy Mechanisms for Federated Learning: Boosting Accuracy and Convergence
Jul 24, 2024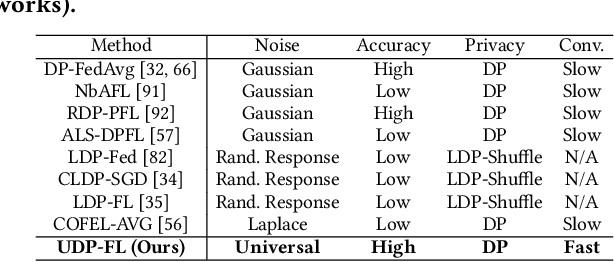
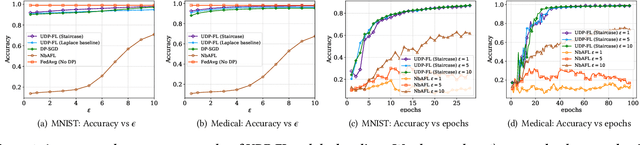
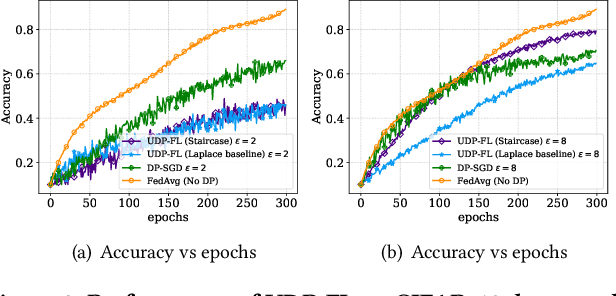
Differentially private federated learning (DP-FL) is a promising technique for collaborative model training while ensuring provable privacy for clients. However, optimizing the tradeoff between privacy and accuracy remains a critical challenge. To our best knowledge, we propose the first DP-FL framework (namely UDP-FL), which universally harmonizes any randomization mechanism (e.g., an optimal one) with the Gaussian Moments Accountant (viz. DP-SGD) to significantly boost accuracy and convergence. Specifically, UDP-FL demonstrates enhanced model performance by mitigating the reliance on Gaussian noise. The key mediator variable in this transformation is the R\'enyi Differential Privacy notion, which is carefully used to harmonize privacy budgets. We also propose an innovative method to theoretically analyze the convergence for DP-FL (including our UDP-FL ) based on mode connectivity analysis. Moreover, we evaluate our UDP-FL through extensive experiments benchmarked against state-of-the-art (SOTA) methods, demonstrating superior performance on both privacy guarantees and model performance. Notably, UDP-FL exhibits substantial resilience against different inference attacks, indicating a significant advance in safeguarding sensitive data in federated learning environments.
An LLM-Assisted Easy-to-Trigger Backdoor Attack on Code Completion Models: Injecting Disguised Vulnerabilities against Strong Detection
Jun 10, 2024Large Language Models (LLMs) have transformed code completion tasks, providing context-based suggestions to boost developer productivity in software engineering. As users often fine-tune these models for specific applications, poisoning and backdoor attacks can covertly alter the model outputs. To address this critical security challenge, we introduce CodeBreaker, a pioneering LLM-assisted backdoor attack framework on code completion models. Unlike recent attacks that embed malicious payloads in detectable or irrelevant sections of the code (e.g., comments), CodeBreaker leverages LLMs (e.g., GPT-4) for sophisticated payload transformation (without affecting functionalities), ensuring that both the poisoned data for fine-tuning and generated code can evade strong vulnerability detection. CodeBreaker stands out with its comprehensive coverage of vulnerabilities, making it the first to provide such an extensive set for evaluation. Our extensive experimental evaluations and user studies underline the strong attack performance of CodeBreaker across various settings, validating its superiority over existing approaches. By integrating malicious payloads directly into the source code with minimal transformation, CodeBreaker challenges current security measures, underscoring the critical need for more robust defenses for code completion.
Certifying Adapters: Enabling and Enhancing the Certification of Classifier Adversarial Robustness
May 25, 2024
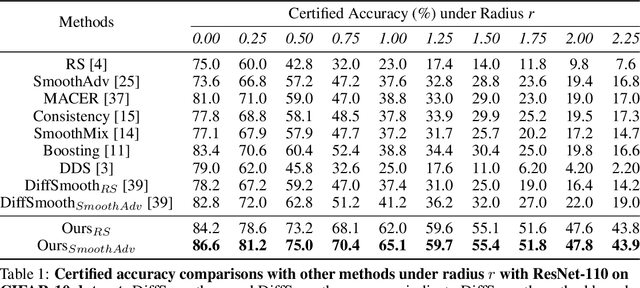
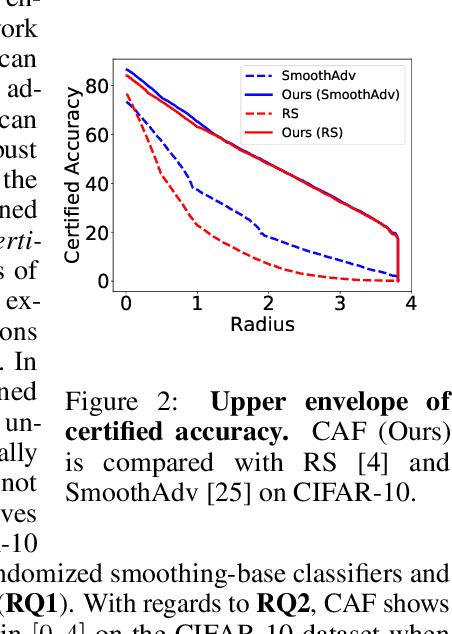

Randomized smoothing has become a leading method for achieving certified robustness in deep classifiers against l_{p}-norm adversarial perturbations. Current approaches for achieving certified robustness, such as data augmentation with Gaussian noise and adversarial training, require expensive training procedures that tune large models for different Gaussian noise levels and thus cannot leverage high-performance pre-trained neural networks. In this work, we introduce a novel certifying adapters framework (CAF) that enables and enhances the certification of classifier adversarial robustness. Our approach makes few assumptions about the underlying training algorithm or feature extractor and is thus broadly applicable to different feature extractor architectures (e.g., convolutional neural networks or vision transformers) and smoothing algorithms. We show that CAF (a) enables certification in uncertified models pre-trained on clean datasets and (b) substantially improves the performance of certified classifiers via randomized smoothing and SmoothAdv at multiple radii in CIFAR-10 and ImageNet. We demonstrate that CAF achieves improved certified accuracies when compared to methods based on random or denoised smoothing, and that CAF is insensitive to certifying adapter hyperparameters. Finally, we show that an ensemble of adapters enables a single pre-trained feature extractor to defend against a range of noise perturbation scales.
Text-CRS: A Generalized Certified Robustness Framework against Textual Adversarial Attacks
Jul 31, 2023
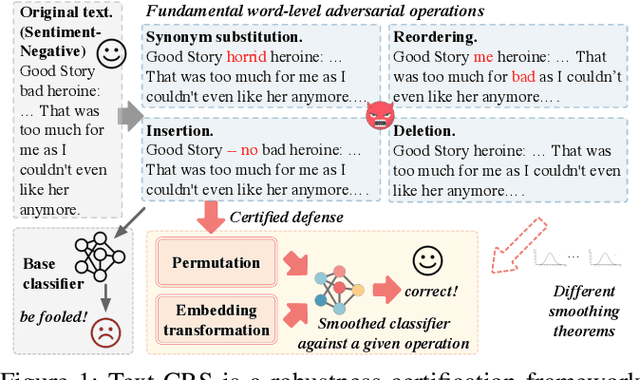
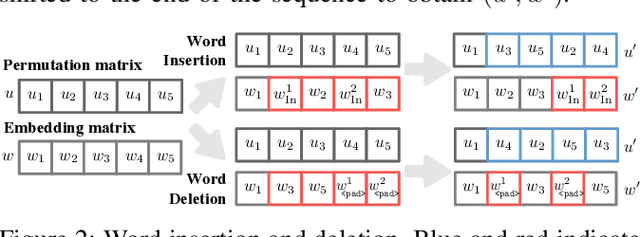
The language models, especially the basic text classification models, have been shown to be susceptible to textual adversarial attacks such as synonym substitution and word insertion attacks. To defend against such attacks, a growing body of research has been devoted to improving the model robustness. However, providing provable robustness guarantees instead of empirical robustness is still widely unexplored. In this paper, we propose Text-CRS, a generalized certified robustness framework for natural language processing (NLP) based on randomized smoothing. To our best knowledge, existing certified schemes for NLP can only certify the robustness against $\ell_0$ perturbations in synonym substitution attacks. Representing each word-level adversarial operation (i.e., synonym substitution, word reordering, insertion, and deletion) as a combination of permutation and embedding transformation, we propose novel smoothing theorems to derive robustness bounds in both permutation and embedding space against such adversarial operations. To further improve certified accuracy and radius, we consider the numerical relationships between discrete words and select proper noise distributions for the randomized smoothing. Finally, we conduct substantial experiments on multiple language models and datasets. Text-CRS can address all four different word-level adversarial operations and achieve a significant accuracy improvement. We also provide the first benchmark on certified accuracy and radius of four word-level operations, besides outperforming the state-of-the-art certification against synonym substitution attacks.
Certifiable Black-Box Attack: Ensuring Provably Successful Attack for Adversarial Examples
Apr 10, 2023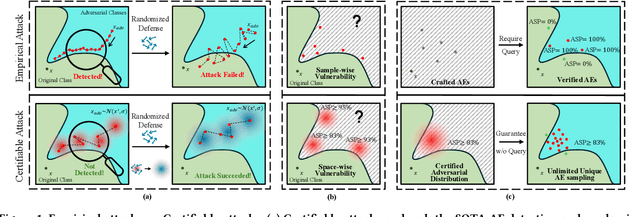

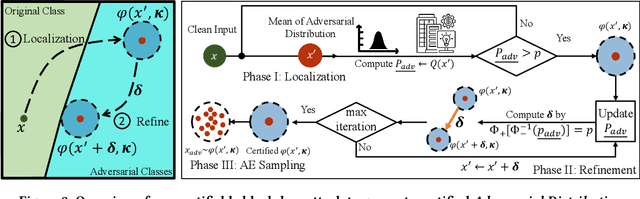
Black-box adversarial attacks have shown strong potential to subvert machine learning models. Existing black-box adversarial attacks craft the adversarial examples by iteratively querying the target model and/or leveraging the transferability of a local surrogate model. Whether such attack can succeed remains unknown to the adversary when empirically designing the attack. In this paper, to our best knowledge, we take the first step to study a new paradigm of adversarial attacks -- certifiable black-box attack that can guarantee the attack success rate of the crafted adversarial examples. Specifically, we revise the randomized smoothing to establish novel theories for ensuring the attack success rate of the adversarial examples. To craft the adversarial examples with the certifiable attack success rate (CASR) guarantee, we design several novel techniques, including a randomized query method to query the target model, an initialization method with smoothed self-supervised perturbation to derive certifiable adversarial examples, and a geometric shifting method to reduce the perturbation size of the certifiable adversarial examples for better imperceptibility. We have comprehensively evaluated the performance of the certifiable black-box attack on CIFAR10 and ImageNet datasets against different levels of defenses. Both theoretical and experimental results have validated the effectiveness of the proposed certifiable attack.
Certified Adversarial Robustness via Anisotropic Randomized Smoothing
Jul 12, 2022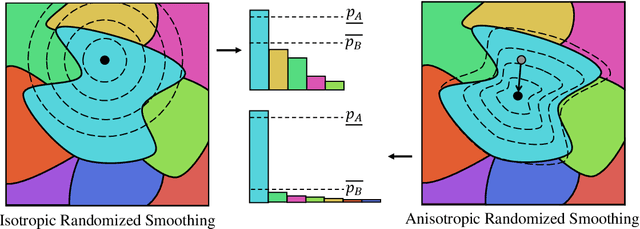



Randomized smoothing has achieved great success for certified robustness against adversarial perturbations. Given any arbitrary classifier, randomized smoothing can guarantee the classifier's prediction over the perturbed input with provable robustness bound by injecting noise into the classifier. However, all of the existing methods rely on fixed i.i.d. probability distribution to generate noise for all dimensions of the data (e.g., all the pixels in an image), which ignores the heterogeneity of inputs and data dimensions. Thus, existing randomized smoothing methods cannot provide optimal protection for all the inputs. To address this limitation, we propose the first anisotropic randomized smoothing method which ensures provable robustness guarantee based on pixel-wise noise distributions. Also, we design a novel CNN-based noise generator to efficiently fine-tune the pixel-wise noise distributions for all the pixels in each input. Experimental results demonstrate that our method significantly outperforms the state-of-the-art randomized smoothing methods.
UniCR: Universally Approximated Certified Robustness via Randomized Smoothing
Jul 10, 2022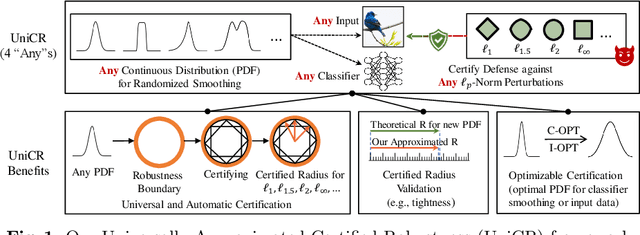
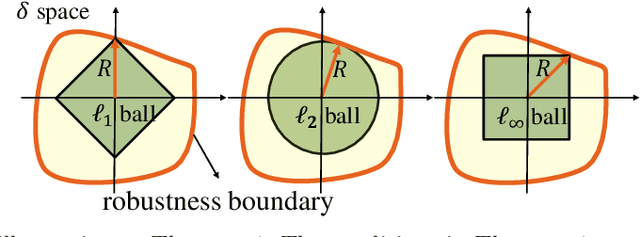
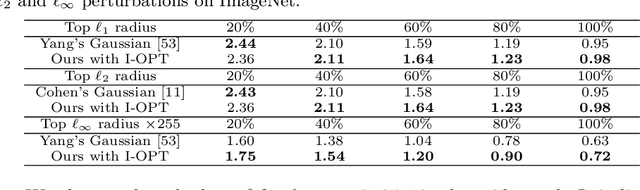
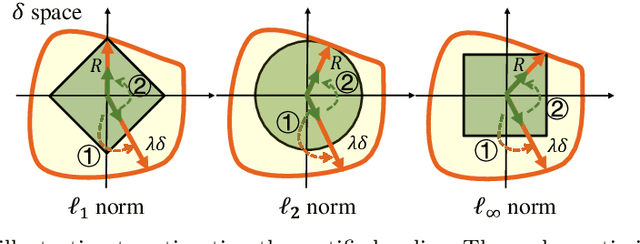
We study certified robustness of machine learning classifiers against adversarial perturbations. In particular, we propose the first universally approximated certified robustness (UniCR) framework, which can approximate the robustness certification of any input on any classifier against any $\ell_p$ perturbations with noise generated by any continuous probability distribution. Compared with the state-of-the-art certified defenses, UniCR provides many significant benefits: (1) the first universal robustness certification framework for the above 4 'any's; (2) automatic robustness certification that avoids case-by-case analysis, (3) tightness validation of certified robustness, and (4) optimality validation of noise distributions used by randomized smoothing. We conduct extensive experiments to validate the above benefits of UniCR and the advantages of UniCR over state-of-the-art certified defenses against $\ell_p$ perturbations.
An Eye for an Eye: Defending against Gradient-based Attacks with Gradients
Feb 02, 2022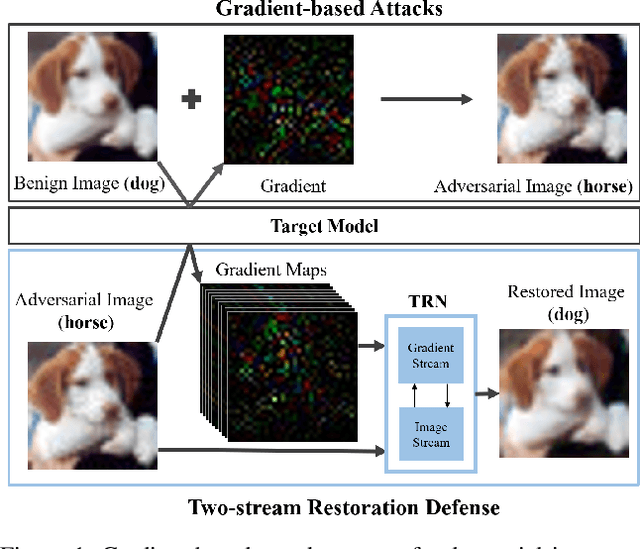
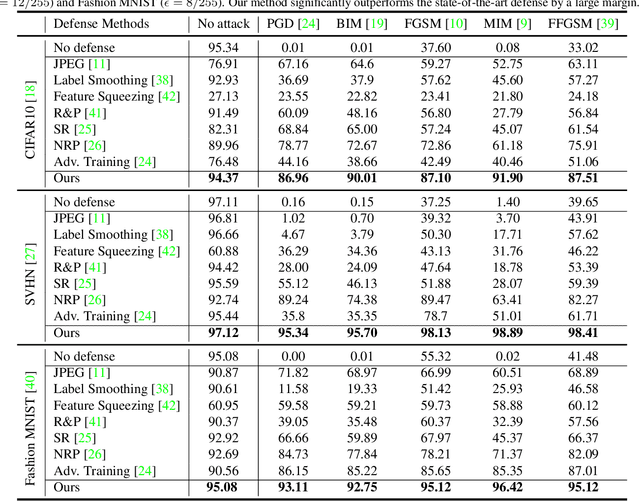
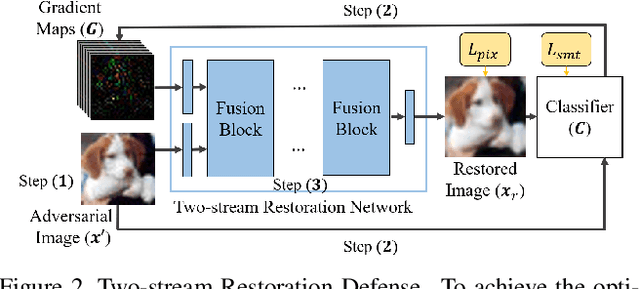
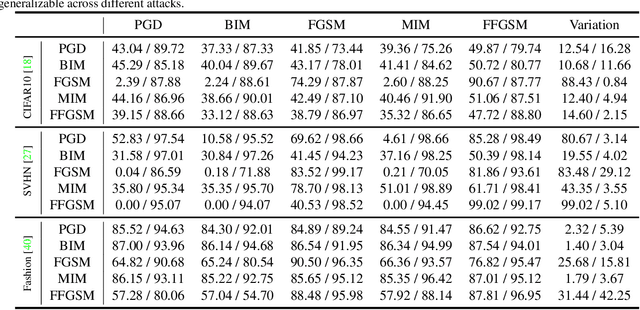
Deep learning models have been shown to be vulnerable to adversarial attacks. In particular, gradient-based attacks have demonstrated high success rates recently. The gradient measures how each image pixel affects the model output, which contains critical information for generating malicious perturbations. In this paper, we show that the gradients can also be exploited as a powerful weapon to defend against adversarial attacks. By using both gradient maps and adversarial images as inputs, we propose a Two-stream Restoration Network (TRN) to restore the adversarial images. To optimally restore the perturbed images with two streams of inputs, a Gradient Map Estimation Mechanism is proposed to estimate the gradients of adversarial images, and a Fusion Block is designed in TRN to explore and fuse the information in two streams. Once trained, our TRN can defend against a wide range of attack methods without significantly degrading the performance of benign inputs. Also, our method is generalizable, scalable, and hard to bypass. Experimental results on CIFAR10, SVHN, and Fashion MNIST demonstrate that our method outperforms state-of-the-art defense methods.