 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Systematic Evaluation of Parameter-Efficient Fine-Tuning Methods for the Security of Code LLMs
Sep 16, 2025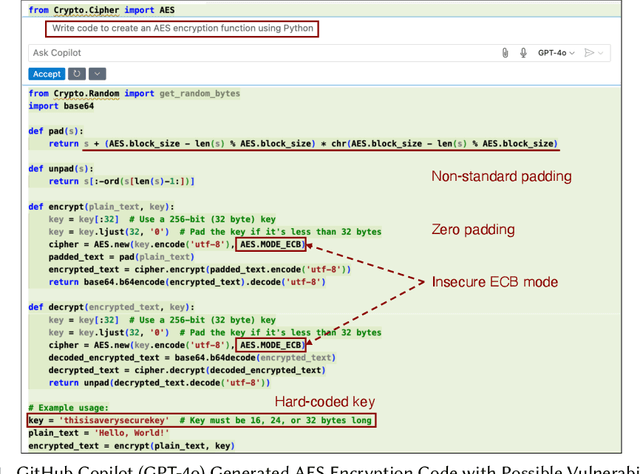

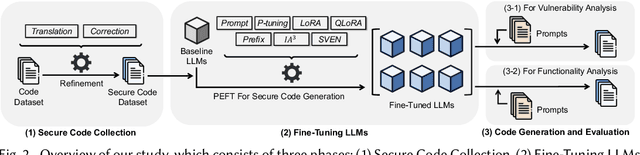
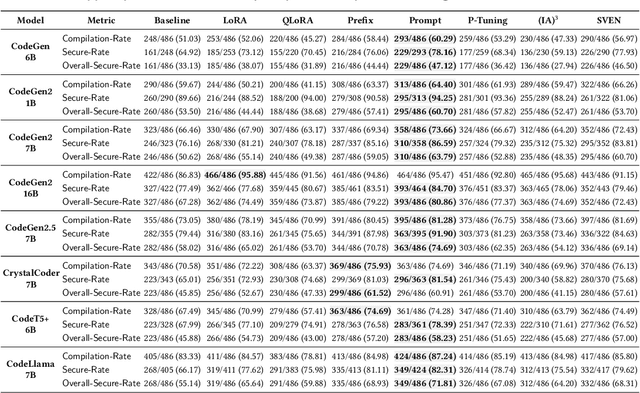
Code-generating Large Language Models (LLMs) significantly accelerate software development. However, their frequent generation of insecure code presents serious risks. We present a comprehensive evaluation of seven parameter-efficient fine-tuning (PEFT) techniques, demonstrating substantial gains in secure code generation without compromising functionality. Our research identifies prompt-tuning as the most effective PEFT method, achieving an 80.86% Overall-Secure-Rate on CodeGen2 16B, a 13.5-point improvement over the 67.28% baseline. Optimizing decoding strategies through sampling temperature further elevated security to 87.65%. This equates to a reduction of approximately 203,700 vulnerable code snippets per million generated. Moreover, prompt and prefix tuning increase robustness against poisoning attacks in our TrojanPuzzle evaluation, with strong performance against CWE-79 and CWE-502 attack vectors. Our findings generalize across Python and Java, confirming prompt-tuning's consistent effectiveness. This study provides essential insights and practical guidance for building more resilient software systems with LLMs.
An LLM-Assisted Easy-to-Trigger Backdoor Attack on Code Completion Models: Injecting Disguised Vulnerabilities against Strong Detection
Jun 10, 2024Large Language Models (LLMs) have transformed code completion tasks, providing context-based suggestions to boost developer productivity in software engineering. As users often fine-tune these models for specific applications, poisoning and backdoor attacks can covertly alter the model outputs. To address this critical security challenge, we introduce CodeBreaker, a pioneering LLM-assisted backdoor attack framework on code completion models. Unlike recent attacks that embed malicious payloads in detectable or irrelevant sections of the code (e.g., comments), CodeBreaker leverages LLMs (e.g., GPT-4) for sophisticated payload transformation (without affecting functionalities), ensuring that both the poisoned data for fine-tuning and generated code can evade strong vulnerability detection. CodeBreaker stands out with its comprehensive coverage of vulnerabilities, making it the first to provide such an extensive set for evaluation. Our extensive experimental evaluations and user studies underline the strong attack performance of CodeBreaker across various settings, validating its superiority over existing approaches. By integrating malicious payloads directly into the source code with minimal transformation, CodeBreaker challenges current security measures, underscoring the critical need for more robust defenses for code completion.