 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne Token, Two Fates: A Unified Framework via Vision Token Manipulation Against MLLMs Hallucination
Mar 11, 2026Current training-free methods tackle MLLM hallucination with separate strategies: either enhancing visual signals or suppressing text inertia. However, these separate methods are insufficient due to critical trade-offs: simply enhancing vision often fails against strong language prior, while suppressing language can introduce extra image-irrelevant noise. Moreover, we find their naive combination is also ineffective, necessitating a unified framework. We propose such a framework by focusing on the core asset: the vision token. Our design leverages two key insights: (1) augmented images offer complementary visual semantics, and (2) removing vision tokens (information-gap) isolates hallucination tendencies more precisely than distorting images (modality-gap). Based on these, our framework uses vision tokens in two distinct ways, both operating on latent representations: our Synergistic Visual Calibration (SVC) module incorporates augmented tokens to strengthen visual representations, while our Causal Representation Calibration (CRC) module uses pruned tokens to create latent-space negative samples for correcting internal model biases. By harmonizing these two roles, our framework effectively restores the vision-language balance, significantly reducing object hallucinations, improving POPE accuracy by an average of 2% absolute on LLaVA-1.5 across multiple benchmarks with only a 1.06x inference latency overhead.
When Shared Knowledge Hurts: Spectral Over-Accumulation in Model Merging
Feb 05, 2026Model merging combines multiple fine-tuned models into a single model by adding their weight updates, providing a lightweight alternative to retraining. Existing methods primarily target resolving conflicts between task updates, leaving the failure mode of over-counting shared knowledge unaddressed. We show that when tasks share aligned spectral directions (i.e., overlapping singular vectors), a simple linear combination repeatedly accumulates these directions, inflating the singular values and biasing the merged model toward shared subspaces. To mitigate this issue, we propose Singular Value Calibration (SVC), a training-free and data-free post-processing method that quantifies subspace overlap and rescales inflated singular values to restore a balanced spectrum. Across vision and language benchmarks, SVC consistently improves strong merging baselines and achieves state-of-the-art performance. Furthermore, by modifying only the singular values, SVC improves the performance of Task Arithmetic by 13.0%. Code is available at: https://github.com/lyymuwu/SVC.
Decomposing and Composing: Towards Efficient Vision-Language Continual Learning via Rank-1 Expert Pool in a Single LoRA
Jan 30, 2026Continual learning (CL) in vision-language models (VLMs) faces significant challenges in improving task adaptation and avoiding catastrophic forgetting. Existing methods usually have heavy inference burden or rely on external knowledge, while Low-Rank Adaptation (LoRA) has shown potential in reducing these issues by enabling parameter-efficient tuning. However, considering directly using LoRA to alleviate the catastrophic forgetting problem is non-trivial, we introduce a novel framework that restructures a single LoRA module as a decomposable Rank-1 Expert Pool. Our method learns to dynamically compose a sparse, task-specific update by selecting from this expert pool, guided by the semantics of the [CLS] token. In addition, we propose an Activation-Guided Orthogonal (AGO) loss that orthogonalizes critical parts of LoRA weights across tasks. This sparse composition and orthogonalization enable fewer parameter updates, resulting in domain-aware learning while minimizing inter-task interference and maintaining downstream task performance. Extensive experiments across multiple settings demonstrate state-of-the-art results in all metrics, surpassing zero-shot upper bounds in generalization. Notably, it reduces trainable parameters by 96.7% compared to the baseline method, eliminating reliance on external datasets or task-ID discriminators. The merged LoRAs retain less weights and incur no inference latency, making our method computationally lightweight.
Divide-and-Conquer for Enhancing Unlabeled Learning, Stability, and Plasticity in Semi-supervised Continual Learning
Aug 07, 2025Semi-supervised continual learning (SSCL) seeks to leverage both labeled and unlabeled data in a sequential learning setup, aiming to reduce annotation costs while managing continual data arrival. SSCL introduces complex challenges, including ensuring effective unlabeled learning (UL), while balancing memory stability (MS) and learning plasticity (LP). Previous SSCL efforts have typically focused on isolated aspects of the three, while this work presents USP, a divide-and-conquer framework designed to synergistically enhance these three aspects: (1) Feature Space Reservation (FSR) strategy for LP, which constructs reserved feature locations for future classes by shaping old classes into an equiangular tight frame; (2) Divide-and-Conquer Pseudo-labeling (DCP) approach for UL, which assigns reliable pseudo-labels across both high- and low-confidence unlabeled data; and (3) Class-mean-anchored Unlabeled Distillation (CUD) for MS, which reuses DCP's outputs to anchor unlabeled data to stable class means for distillation to prevent forgetting. Comprehensive evaluations show USP outperforms prior SSCL methods, with gains up to 5.94% in the last accuracy, validating its effectiveness. The code is available at https://github.com/NJUyued/USP4SSCL.
PC$^2$: Pseudo-Classification Based Pseudo-Captioning for Noisy Correspondence Learning in Cross-Modal Retrieval
Aug 02, 2024



In the realm of cross-modal retrieval, seamlessly integrating diverse modalities within multimedia remains a formidable challenge, especially given the complexities introduced by noisy correspondence learning (NCL). Such noise often stems from mismatched data pairs, which is a significant obstacle distinct from traditional noisy labels. This paper introduces Pseudo-Classification based Pseudo-Captioning (PC$^2$) framework to address this challenge. PC$^2$ offers a threefold strategy: firstly, it establishes an auxiliary "pseudo-classification" task that interprets captions as categorical labels, steering the model to learn image-text semantic similarity through a non-contrastive mechanism. Secondly, unlike prevailing margin-based techniques, capitalizing on PC$^2$'s pseudo-classification capability, we generate pseudo-captions to provide more informative and tangible supervision for each mismatched pair. Thirdly, the oscillation of pseudo-classification is borrowed to assistant the correction of correspondence. In addition to technical contributions, we develop a realistic NCL dataset called Noise of Web (NoW), which could be a new powerful NCL benchmark where noise exists naturally. Empirical evaluations of PC$^2$ showcase marked improvements over existing state-of-the-art robust cross-modal retrieval techniques on both simulated and realistic datasets with various NCL settings. The contributed dataset and source code are released at https://github.com/alipay/PC2-NoiseofWeb.
An LLM-Assisted Easy-to-Trigger Backdoor Attack on Code Completion Models: Injecting Disguised Vulnerabilities against Strong Detection
Jun 10, 2024Large Language Models (LLMs) have transformed code completion tasks, providing context-based suggestions to boost developer productivity in software engineering. As users often fine-tune these models for specific applications, poisoning and backdoor attacks can covertly alter the model outputs. To address this critical security challenge, we introduce CodeBreaker, a pioneering LLM-assisted backdoor attack framework on code completion models. Unlike recent attacks that embed malicious payloads in detectable or irrelevant sections of the code (e.g., comments), CodeBreaker leverages LLMs (e.g., GPT-4) for sophisticated payload transformation (without affecting functionalities), ensuring that both the poisoned data for fine-tuning and generated code can evade strong vulnerability detection. CodeBreaker stands out with its comprehensive coverage of vulnerabilities, making it the first to provide such an extensive set for evaluation. Our extensive experimental evaluations and user studies underline the strong attack performance of CodeBreaker across various settings, validating its superiority over existing approaches. By integrating malicious payloads directly into the source code with minimal transformation, CodeBreaker challenges current security measures, underscoring the critical need for more robust defenses for code completion.
PG-LBO: Enhancing High-Dimensional Bayesian Optimization with Pseudo-Label and Gaussian Process Guidance
Dec 28, 2023Variational Autoencoder based Bayesian Optimization (VAE-BO) has demonstrated its excellent performance in addressing high-dimensional structured optimization problems. However, current mainstream methods overlook the potential of utilizing a pool of unlabeled data to construct the latent space, while only concentrating on designing sophisticated models to leverage the labeled data. Despite their effective usage of labeled data, these methods often require extra network structures, additional procedure, resulting in computational inefficiency. To address this issue, we propose a novel method to effectively utilize unlabeled data with the guidance of labeled data. Specifically, we tailor the pseudo-labeling technique from semi-supervised learning to explicitly reveal the relative magnitudes of optimization objective values hidden within the unlabeled data. Based on this technique, we assign appropriate training weights to unlabeled data to enhance the construction of a discriminative latent space. Furthermore, we treat the VAE encoder and the Gaussian Process (GP) in Bayesian optimization as a unified deep kernel learning process, allowing the direct utilization of labeled data, which we term as Gaussian Process guidance. This directly and effectively integrates the goal of improving GP accuracy into the VAE training, thereby guiding the construction of the latent space. The extensive experiments demonstrate that our proposed method outperforms existing VAE-BO algorithms in various optimization scenarios. Our code will be published at https://github.com/TaicaiChen/PG-LBO.
Roll With the Punches: Expansion and Shrinkage of Soft Label Selection for Semi-supervised Fine-Grained Learning
Dec 19, 2023While semi-supervised learning (SSL) has yielded promising results, the more realistic SSL scenario remains to be explored, in which the unlabeled data exhibits extremely high recognition difficulty, e.g., fine-grained visual classification in the context of SSL (SS-FGVC). The increased recognition difficulty on fine-grained unlabeled data spells disaster for pseudo-labeling accuracy, resulting in poor performance of the SSL model. To tackle this challenge, we propose Soft Label Selection with Confidence-Aware Clustering based on Class Transition Tracking (SoC) by reconstructing the pseudo-label selection process by jointly optimizing Expansion Objective and Shrinkage Objective, which is based on a soft label manner. Respectively, the former objective encourages soft labels to absorb more candidate classes to ensure the attendance of ground-truth class, while the latter encourages soft labels to reject more noisy classes, which is theoretically proved to be equivalent to entropy minimization. In comparisons with various state-of-the-art methods, our approach demonstrates its superior performance in SS-FGVC. Checkpoints and source code are available at https://github.com/NJUyued/SoC4SS-FGVC.
Towards Semi-supervised Learning with Non-random Missing Labels
Aug 17, 2023Semi-supervised learning (SSL) tackles the label missing problem by enabling the effective usage of unlabeled data. While existing SSL methods focus on the traditional setting, a practical and challenging scenario called label Missing Not At Random (MNAR) is usually ignored. In MNAR, the labeled and unlabeled data fall into different class distributions resulting in biased label imputation, which deteriorates the performance of SSL models. In this work, class transition tracking based Pseudo-Rectifying Guidance (PRG) is devised for MNAR. We explore the class-level guidance information obtained by the Markov random walk, which is modeled on a dynamically created graph built over the class tracking matrix. PRG unifies the historical information of class distribution and class transitions caused by the pseudo-rectifying procedure to maintain the model's unbiased enthusiasm towards assigning pseudo-labels to all classes, so as the quality of pseudo-labels on both popular classes and rare classes in MNAR could be improved. Finally, we show the superior performance of PRG across a variety of MNAR scenarios, outperforming the latest SSL approaches combining bias removal solutions by a large margin. Code and model weights are available at https://github.com/NJUyued/PRG4SSL-MNAR.
RDA: Reciprocal Distribution Alignment for Robust Semi-supervised Learning
Aug 12, 2022
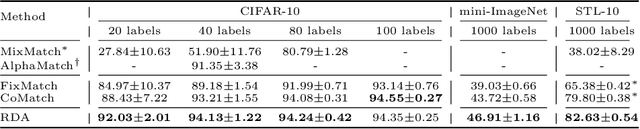
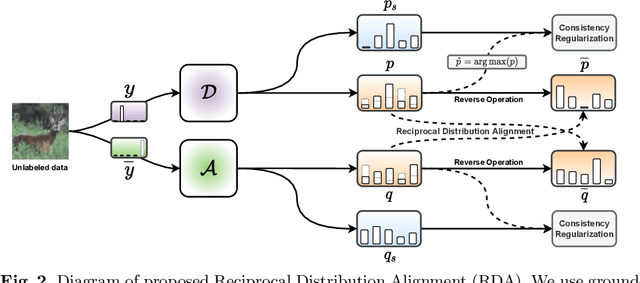

In this work, we propose Reciprocal Distribution Alignment (RDA) to address semi-supervised learning (SSL), which is a hyperparameter-free framework that is independent of confidence threshold and works with both the matched (conventionally) and the mismatched class distributions. Distribution mismatch is an often overlooked but more general SSL scenario where the labeled and the unlabeled data do not fall into the identical class distribution. This may lead to the model not exploiting the labeled data reliably and drastically degrade the performance of SSL methods, which could not be rescued by the traditional distribution alignment. In RDA, we enforce a reciprocal alignment on the distributions of the predictions from two classifiers predicting pseudo-labels and complementary labels on the unlabeled data. These two distributions, carrying complementary information, could be utilized to regularize each other without any prior of class distribution. Moreover, we theoretically show that RDA maximizes the input-output mutual information. Our approach achieves promising performance in SSL under a variety of scenarios of mismatched distributions, as well as the conventional matched SSL setting. Our code is available at: https://github.com/NJUyued/RDA4RobustSSL.