 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMutexMatch: Semi-supervised Learning with Mutex-based Consistency Regularization
Paper and Code

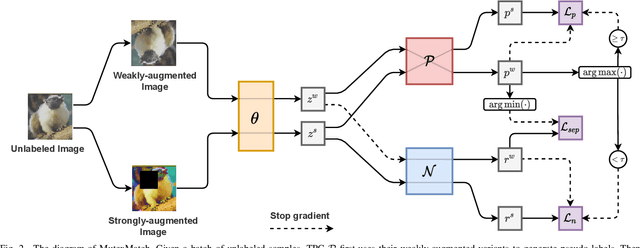

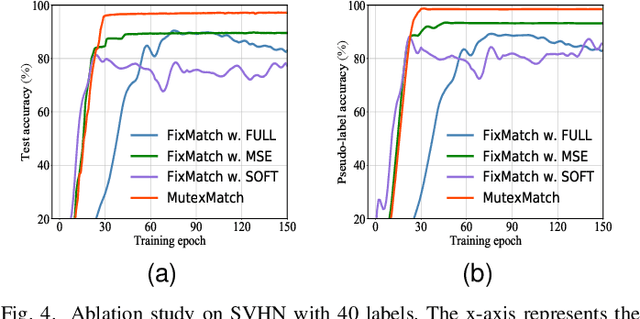
The core issue in semi-supervised learning (SSL) lies in how to effectively leverage unlabeled data, whereas most existing methods tend to put a great emphasis on the utilization of high-confidence samples yet seldom fully explore the usage of low-confidence samples. In this paper, we aim to utilize low-confidence samples in a novel way with our proposed mutex-based consistency regularization, namely MutexMatch. Specifically, the high-confidence samples are required to exactly predict "what it is" by conventional True-Positive Classifier, while the low-confidence samples are employed to achieve a simpler goal -- to predict with ease "what it is not" by True-Negative Classifier. In this sense, we not only mitigate the pseudo-labeling errors but also make full use of the low-confidence unlabeled data by consistency of dissimilarity degree. MutexMatch achieves superior performance on multiple benchmark datasets, i.e., CIFAR-10, CIFAR-100, SVHN, STL-10, and mini-ImageNet. More importantly, our method further shows superiority when the amount of labeled data is scarce, e.g., 92.23% accuracy with only 20 labeled data on CIFAR-10. Code has been released at https://github.com/NJUyued/MutexMatch4SSL.