 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUI-Venus-1.5 Technical Report
Feb 09, 2026GUI agents have emerged as a powerful paradigm for automating interactions in digital environments, yet achieving both broad generality and consistently strong task performance remains challenging.In this report, we present UI-Venus-1.5, a unified, end-to-end GUI Agent designed for robust real-world applications.The proposed model family comprises two dense variants (2B and 8B) and one mixture-of-experts variant (30B-A3B) to meet various downstream application scenarios.Compared to our previous version, UI-Venus-1.5 introduces three key technical advances: (1) a comprehensive Mid-Training stage leveraging 10 billion tokens across 30+ datasets to establish foundational GUI semantics; (2) Online Reinforcement Learning with full-trajectory rollouts, aligning training objectives with long-horizon, dynamic navigation in large-scale environments; and (3) a single unified GUI Agent constructed via Model Merging, which synthesizes domain-specific models (grounding, web, and mobile) into one cohesive checkpoint. Extensive evaluations demonstrate that UI-Venus-1.5 establishes new state-of-the-art performance on benchmarks such as ScreenSpot-Pro (69.6%), VenusBench-GD (75.0%), and AndroidWorld (77.6%), significantly outperforming previous strong baselines. In addition, UI-Venus-1.5 demonstrates robust navigation capabilities across a variety of Chinese mobile apps, effectively executing user instructions in real-world scenarios. Code: https://github.com/inclusionAI/UI-Venus; Model: https://huggingface.co/collections/inclusionAI/ui-venus
VenusBench-GD: A Comprehensive Multi-Platform GUI Benchmark for Diverse Grounding Tasks
Dec 18, 2025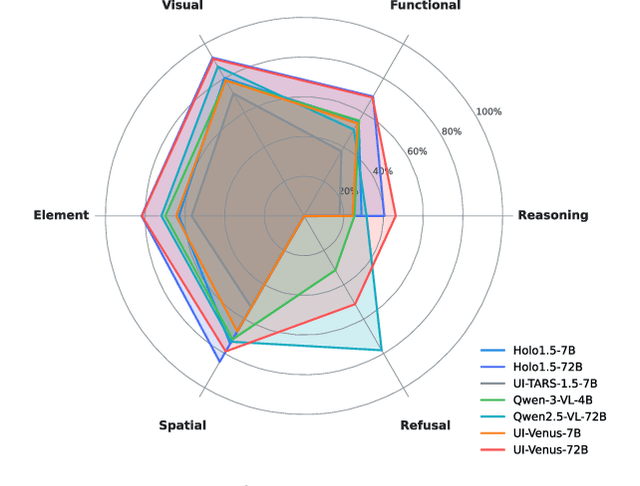
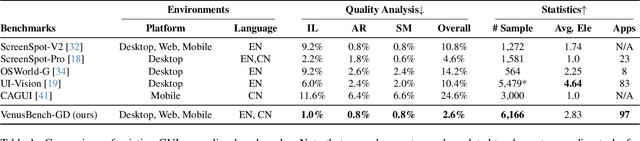
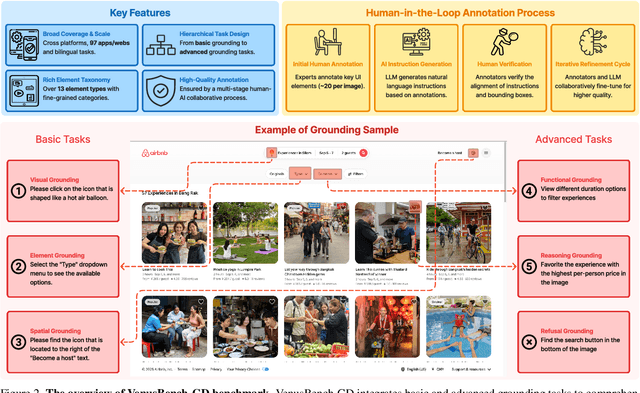
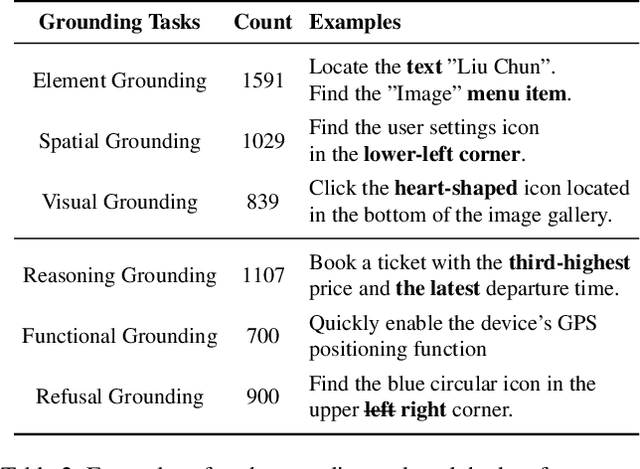
GUI grounding is a critical component in building capable GUI agents. However, existing grounding benchmarks suffer from significant limitations: they either provide insufficient data volume and narrow domain coverage, or focus excessively on a single platform and require highly specialized domain knowledge. In this work, we present VenusBench-GD, a comprehensive, bilingual benchmark for GUI grounding that spans multiple platforms, enabling hierarchical evaluation for real-word applications. VenusBench-GD contributes as follows: (i) we introduce a large-scale, cross-platform benchmark with extensive coverage of applications, diverse UI elements, and rich annotated data, (ii) we establish a high-quality data construction pipeline for grounding tasks, achieving higher annotation accuracy than existing benchmarks, and (iii) we extend the scope of element grounding by proposing a hierarchical task taxonomy that divides grounding into basic and advanced categories, encompassing six distinct subtasks designed to evaluate models from complementary perspectives. Our experimental findings reveal critical insights: general-purpose multimodal models now match or even surpass specialized GUI models on basic grounding tasks. In contrast, advanced tasks, still favor GUI-specialized models, though they exhibit significant overfitting and poor robustness. These results underscore the necessity of comprehensive, multi-tiered evaluation frameworks.
Efficient Transfer Learning for Video-language Foundation Models
Nov 18, 2024



Pre-trained vision-language models provide a robust foundation for efficient transfer learning across various downstream tasks. In the field of video action recognition, mainstream approaches often introduce additional parameter modules to capture temporal information. While the increased model capacity brought by these additional parameters helps better fit the video-specific inductive biases, existing methods require learning a large number of parameters and are prone to catastrophic forgetting of the original generalizable knowledge. In this paper, we propose a simple yet effective Multi-modal Spatio-Temporal Adapter (MSTA) to improve the alignment between representations in the text and vision branches, achieving a balance between general knowledge and task-specific knowledge. Furthermore, to mitigate over-fitting and enhance generalizability, we introduce a spatio-temporal description-guided consistency constraint. This constraint involves feeding template inputs (i.e., ``a video of $\{\textbf{cls}\}$'') into the trainable language branch, while LLM-generated spatio-temporal descriptions are input into the pre-trained language branch, enforcing consistency between the outputs of the two branches. This mechanism prevents over-fitting to downstream tasks and improves the distinguishability of the trainable branch within the spatio-temporal semantic space. We evaluate the effectiveness of our approach across four tasks: zero-shot transfer, few-shot learning, base-to-novel generalization, and fully-supervised learning. Compared to many state-of-the-art methods, our MSTA achieves outstanding performance across all evaluations, while using only 2-7\% of the trainable parameters in the original model. Code will be avaliable at https://github.com/chenhaoxing/ETL4Video.
PC$^2$: Pseudo-Classification Based Pseudo-Captioning for Noisy Correspondence Learning in Cross-Modal Retrieval
Aug 02, 2024



In the realm of cross-modal retrieval, seamlessly integrating diverse modalities within multimedia remains a formidable challenge, especially given the complexities introduced by noisy correspondence learning (NCL). Such noise often stems from mismatched data pairs, which is a significant obstacle distinct from traditional noisy labels. This paper introduces Pseudo-Classification based Pseudo-Captioning (PC$^2$) framework to address this challenge. PC$^2$ offers a threefold strategy: firstly, it establishes an auxiliary "pseudo-classification" task that interprets captions as categorical labels, steering the model to learn image-text semantic similarity through a non-contrastive mechanism. Secondly, unlike prevailing margin-based techniques, capitalizing on PC$^2$'s pseudo-classification capability, we generate pseudo-captions to provide more informative and tangible supervision for each mismatched pair. Thirdly, the oscillation of pseudo-classification is borrowed to assistant the correction of correspondence. In addition to technical contributions, we develop a realistic NCL dataset called Noise of Web (NoW), which could be a new powerful NCL benchmark where noise exists naturally. Empirical evaluations of PC$^2$ showcase marked improvements over existing state-of-the-art robust cross-modal retrieval techniques on both simulated and realistic datasets with various NCL settings. The contributed dataset and source code are released at https://github.com/alipay/PC2-NoiseofWeb.
E-ANT: A Large-Scale Dataset for Efficient Automatic GUI NavigaTion
Jun 20, 2024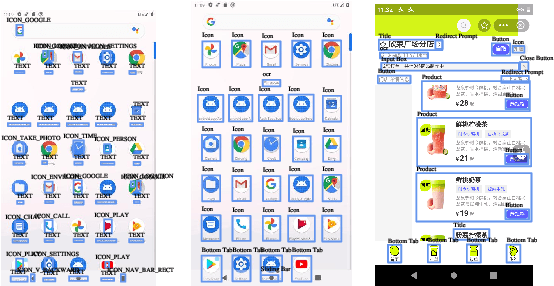
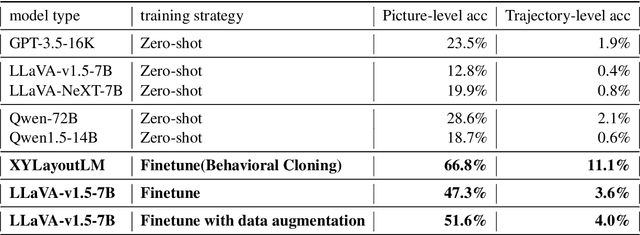
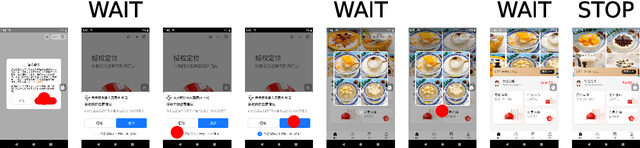
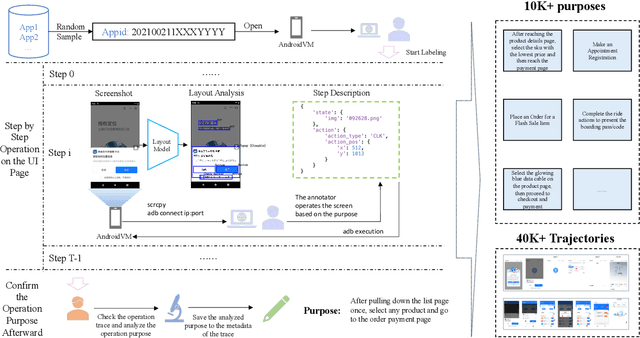
Online GUI navigation on mobile devices has driven a lot of attention recent years since it contributes to many real-world applications. With the rapid development of large language models (LLM), multimodal large language models (MLLM) have tremendous potential on this task. However, existing MLLMs need high quality data to improve its abilities of making the correct navigation decisions according to the human user inputs. In this paper, we developed a novel and highly valuable dataset, named \textbf{E-ANT}, as the first Chinese GUI navigation dataset that contains real human behaviour and high quality screenshots with annotations, containing nearly 40,000 real human traces over 5000+ different tinyAPPs. Furthermore, we evaluate various powerful MLLMs on E-ANT and show their experiments results with sufficient ablations. We believe that our proposed dataset will be beneficial for both the evaluation and development of GUI navigation and LLM/MLLM decision-making capabilities.
DeMamba: AI-Generated Video Detection on Million-Scale GenVideo Benchmark
May 30, 2024
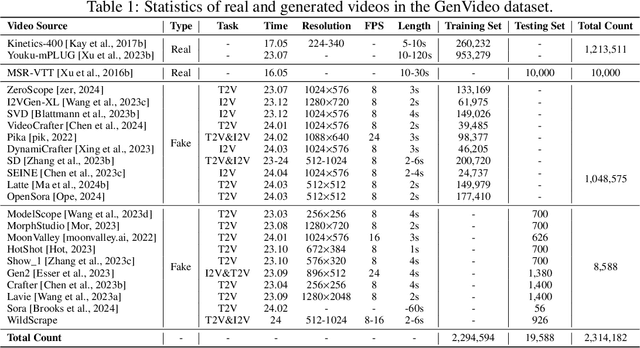
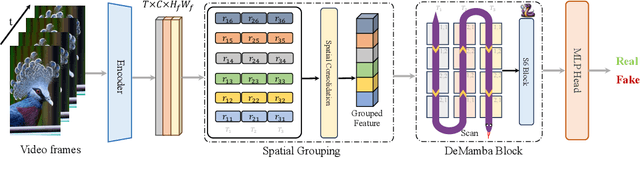
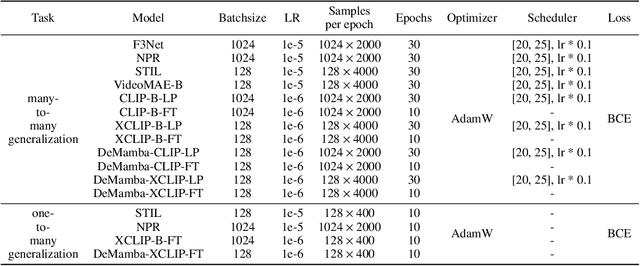
Recently, video generation techniques have advanced rapidly. Given the popularity of video content on social media platforms, these models intensify concerns about the spread of fake information. Therefore, there is a growing demand for detectors capable of distinguishing between fake AI-generated videos and mitigating the potential harm caused by fake information. However, the lack of large-scale datasets from the most advanced video generators poses a barrier to the development of such detectors. To address this gap, we introduce the first AI-generated video detection dataset, GenVideo. It features the following characteristics: (1) a large volume of videos, including over one million AI-generated and real videos collected; (2) a rich diversity of generated content and methodologies, covering a broad spectrum of video categories and generation techniques. We conducted extensive studies of the dataset and proposed two evaluation methods tailored for real-world-like scenarios to assess the detectors' performance: the cross-generator video classification task assesses the generalizability of trained detectors on generators; the degraded video classification task evaluates the robustness of detectors to handle videos that have degraded in quality during dissemination. Moreover, we introduced a plug-and-play module, named Detail Mamba (DeMamba), designed to enhance the detectors by identifying AI-generated videos through the analysis of inconsistencies in temporal and spatial dimensions. Our extensive experiments demonstrate DeMamba's superior generalizability and robustness on GenVideo compared to existing detectors. We believe that the GenVideo dataset and the DeMamba module will significantly advance the field of AI-generated video detection. Our code and dataset will be aviliable at \url{https://github.com/chenhaoxing/DeMamba}.
Conditional Prototype Rectification Prompt Learning
Apr 15, 2024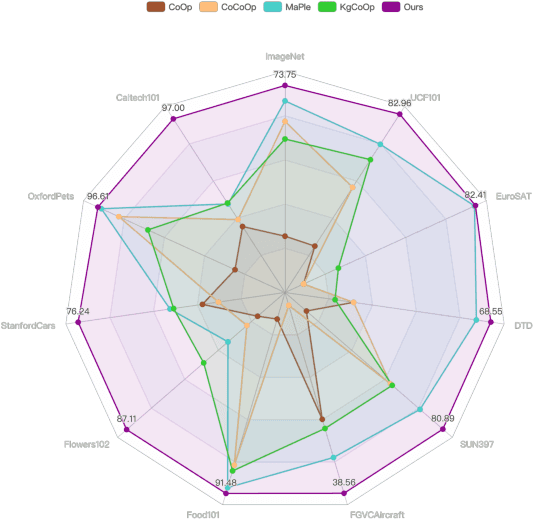

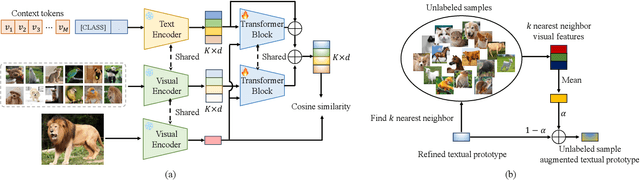

Pre-trained large-scale vision-language models (VLMs) have acquired profound understanding of general visual concepts. Recent advancements in efficient transfer learning (ETL) have shown remarkable success in fine-tuning VLMs within the scenario of limited data, introducing only a few parameters to harness task-specific insights from VLMs. Despite significant progress, current leading ETL methods tend to overfit the narrow distributions of base classes seen during training and encounter two primary challenges: (i) only utilizing uni-modal information to modeling task-specific knowledge; and (ii) using costly and time-consuming methods to supplement knowledge. To address these issues, we propose a Conditional Prototype Rectification Prompt Learning (CPR) method to correct the bias of base examples and augment limited data in an effective way. Specifically, we alleviate overfitting on base classes from two aspects. First, each input image acquires knowledge from both textual and visual prototypes, and then generates sample-conditional text tokens. Second, we extract utilizable knowledge from unlabeled data to further refine the prototypes. These two strategies mitigate biases stemming from base classes, yielding a more effective classifier. Extensive experiments on 11 benchmark datasets show that our CPR achieves state-of-the-art performance on both few-shot classification and base-to-new generalization tasks. Our code is avaliable at \url{https://github.com/chenhaoxing/CPR}.
Segment Anything Model Meets Image Harmonization
Dec 20, 2023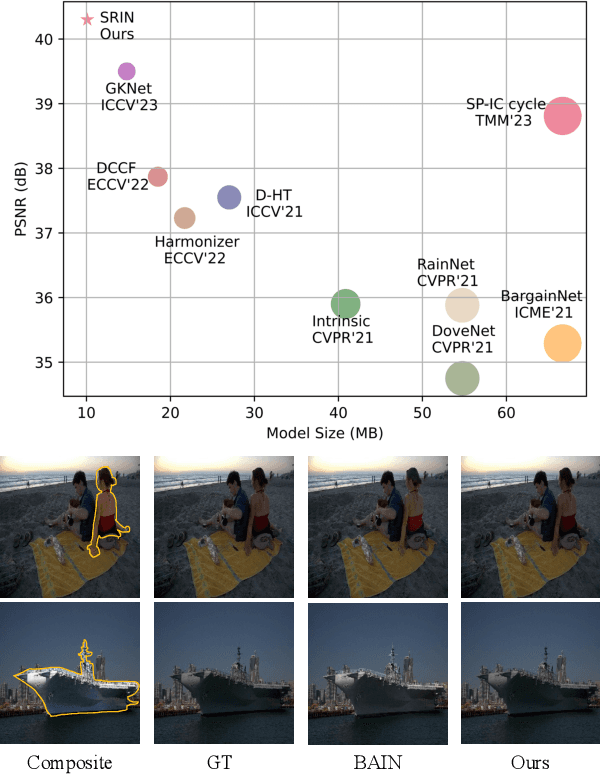
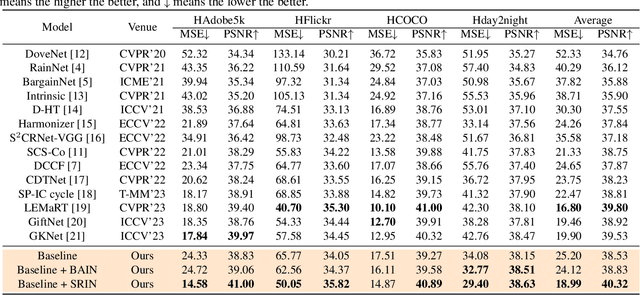
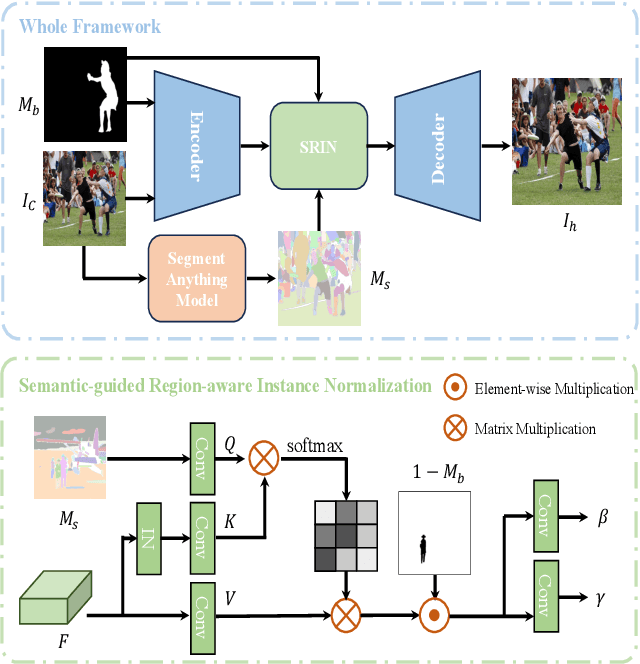
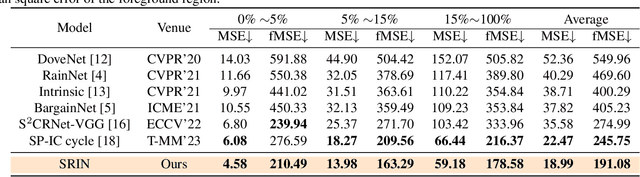
Image harmonization is a crucial technique in image composition that aims to seamlessly match the background by adjusting the foreground of composite images. Current methods adopt either global-level or pixel-level feature matching. Global-level feature matching ignores the proximity prior, treating foreground and background as separate entities. On the other hand, pixel-level feature matching loses contextual information. Therefore, it is necessary to use the information from semantic maps that describe different objects to guide harmonization. In this paper, we propose Semantic-guided Region-aware Instance Normalization (SRIN) that can utilize the semantic segmentation maps output by a pre-trained Segment Anything Model (SAM) to guide the visual consistency learning of foreground and background features. Abundant experiments demonstrate the superiority of our method for image harmonization over state-of-the-art methods.
Boosting Audio-visual Zero-shot Learning with Large Language Models
Nov 21, 2023



Audio-visual zero-shot learning aims to recognize unseen categories based on paired audio-visual sequences. Recent methods mainly focus on learning aligned and discriminative multi-modal features to boost generalization towards unseen categories. However, these approaches ignore the obscure action concepts in category names and may inevitably introduce complex network structures with difficult training objectives. In this paper, we propose a simple yet effective framework named Knowledge-aware Distribution Adaptation (KDA) to help the model better grasp the novel action contents with an external knowledge base. Specifically, we first propose using large language models to generate rich descriptions from category names, which leads to a better understanding of unseen categories. Additionally, we propose a distribution alignment loss as well as a knowledge-aware adaptive margin loss to further improve the generalization ability towards unseen categories. Extensive experimental results demonstrate that our proposed KDA can outperform state-of-the-art methods on three popular audio-visual zero-shot learning datasets. Our code will be avaliable at \url{https://github.com/chenhaoxing/KDA}.
Backpropagation Path Search On Adversarial Transferability
Aug 15, 2023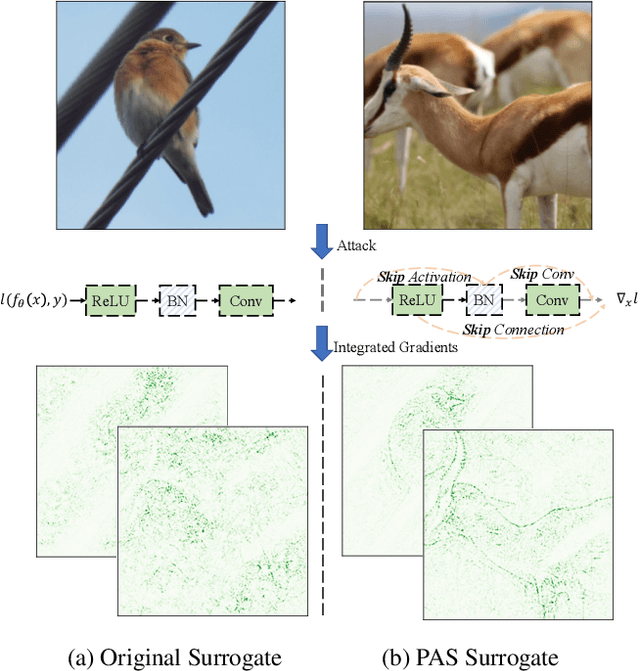



Deep neural networks are vulnerable to adversarial examples, dictating the imperativeness to test the model's robustness before deployment. Transfer-based attackers craft adversarial examples against surrogate models and transfer them to victim models deployed in the black-box situation. To enhance the adversarial transferability, structure-based attackers adjust the backpropagation path to avoid the attack from overfitting the surrogate model. However, existing structure-based attackers fail to explore the convolution module in CNNs and modify the backpropagation graph heuristically, leading to limited effectiveness. In this paper, we propose backPropagation pAth Search (PAS), solving the aforementioned two problems. We first propose SkipConv to adjust the backpropagation path of convolution by structural reparameterization. To overcome the drawback of heuristically designed backpropagation paths, we further construct a DAG-based search space, utilize one-step approximation for path evaluation and employ Bayesian Optimization to search for the optimal path. We conduct comprehensive experiments in a wide range of transfer settings, showing that PAS improves the attack success rate by a huge margin for both normally trained and defense models.