 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraPO: A Semi-Supervised Reinforcement Learning Framework for Boosting LLM Reasoning
Dec 15, 2025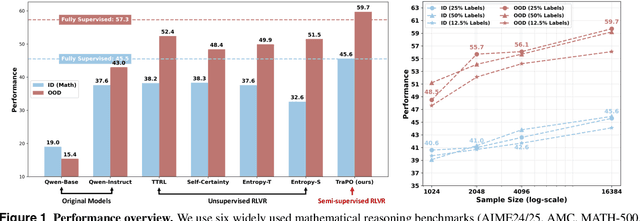
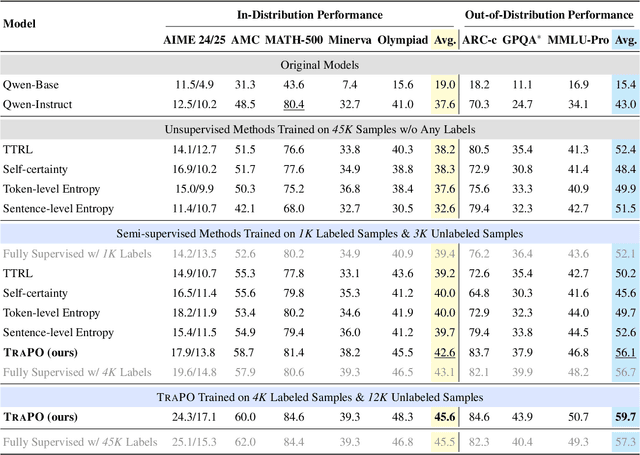
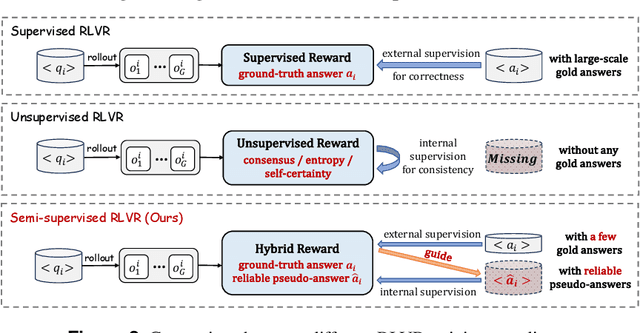
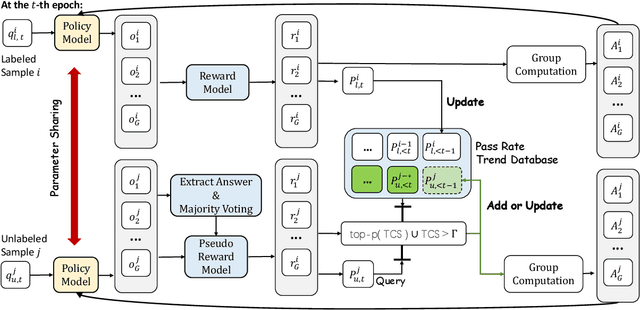
Reinforcement learning with verifiable rewards (RLVR) has proven effective in training large reasoning models (LRMs) by leveraging answer-verifiable signals to guide policy optimization, which, however, suffers from high annotation costs. To alleviate this problem, recent work has explored unsupervised RLVR methods that derive rewards solely from the model's internal consistency, such as through entropy and majority voting. While seemingly promising, these methods often suffer from model collapse in the later stages of training, which may arise from the reinforcement of incorrect reasoning patterns in the absence of external supervision. In this work, we investigate a novel semi-supervised RLVR paradigm that utilizes a small labeled set to guide RLVR training on unlabeled samples. Our key insight is that supervised rewards are essential for stabilizing consistency-based training on unlabeled samples, ensuring that only reasoning patterns verified on labeled instances are incorporated into RL training. Technically, we propose an effective policy optimization algorithm, TraPO, that identifies reliable unlabeled samples by matching their learning trajectory similarity to labeled ones. Building on this, TraPO achieves remarkable data efficiency and strong generalization on six widely used mathematical reasoning benchmarks (AIME24/25, AMC, MATH-500, Minerva, and Olympiad) and three out-of-distribution tasks (ARC-c, GPQA-diamond, and MMLU-pro). With only 1K labeled and 3K unlabeled samples, TraPO reaches 42.6% average accuracy, surpassing the best unsupervised method trained on 45K unlabeled samples (38.3%). Notably, when using 4K labeled and 12K unlabeled samples, TraPO even outperforms the fully supervised model trained on the full 45K labeled samples on all benchmarks, while using only 10% of the labeled data. The code is available via https://github.com/ShenzhiYang2000/TRAPO.
KBQA-R1: Reinforcing Large Language Models for Knowledge Base Question Answering
Dec 10, 2025Knowledge Base Question Answering (KBQA) challenges models to bridge the gap between natural language and strict knowledge graph schemas by generating executable logical forms. While Large Language Models (LLMs) have advanced this field, current approaches often struggle with a dichotomy of failure: they either generate hallucinated queries without verifying schema existence or exhibit rigid, template-based reasoning that mimics synthesized traces without true comprehension of the environment. To address these limitations, we present \textbf{KBQA-R1}, a framework that shifts the paradigm from text imitation to interaction optimization via Reinforcement Learning. Treating KBQA as a multi-turn decision process, our model learns to navigate the knowledge base using a list of actions, leveraging Group Relative Policy Optimization (GRPO) to refine its strategies based on concrete execution feedback rather than static supervision. Furthermore, we introduce \textbf{Referenced Rejection Sampling (RRS)}, a data synthesis method that resolves cold-start challenges by strictly aligning reasoning traces with ground-truth action sequences. Extensive experiments on WebQSP, GrailQA, and GraphQuestions demonstrate that KBQA-R1 achieves state-of-the-art performance, effectively grounding LLM reasoning in verifiable execution.
SecBench: A Comprehensive Multi-Dimensional Benchmarking Dataset for LLMs in Cybersecurity
Dec 30, 2024



Evaluating Large Language Models (LLMs) is crucial for understanding their capabilities and limitations across various applications, including natural language processing and code generation. Existing benchmarks like MMLU, C-Eval, and HumanEval assess general LLM performance but lack focus on specific expert domains such as cybersecurity. Previous attempts to create cybersecurity datasets have faced limitations, including insufficient data volume and a reliance on multiple-choice questions (MCQs). To address these gaps, we propose SecBench, a multi-dimensional benchmarking dataset designed to evaluate LLMs in the cybersecurity domain. SecBench includes questions in various formats (MCQs and short-answer questions (SAQs)), at different capability levels (Knowledge Retention and Logical Reasoning), in multiple languages (Chinese and English), and across various sub-domains. The dataset was constructed by collecting high-quality data from open sources and organizing a Cybersecurity Question Design Contest, resulting in 44,823 MCQs and 3,087 SAQs. Particularly, we used the powerful while cost-effective LLMs to (1). label the data and (2). constructing a grading agent for automatic evaluation of SAQs.Benchmarking results on 13 SOTA LLMs demonstrate the usability of SecBench, which is arguably the largest and most comprehensive benchmark dataset for LLMs in cybersecurity. More information about SecBench can be found at our website, and the dataset can be accessed via the artifact link.
DiffUTE: Universal Text Editing Diffusion Model
May 19, 2023Diffusion model based language-guided image editing has achieved great success recently. However, existing state-of-the-art diffusion models struggle with rendering correct text and text style during generation. To tackle this problem, we propose a universal self-supervised text editing diffusion model (DiffUTE), which aims to replace or modify words in the source image with another one while maintaining its realistic appearance. Specifically, we build our model on a diffusion model and carefully modify the network structure to enable the model for drawing multilingual characters with the help of glyph and position information. Moreover, we design a self-supervised learning framework to leverage large amounts of web data to improve the representation ability of the model. Experimental results show that our method achieves an impressive performance and enables controllable editing on in-the-wild images with high fidelity. Our code will be avaliable in \url{https://github.com/chenhaoxing/DiffUTE}.