 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConditional Prototype Rectification Prompt Learning
Paper and Code
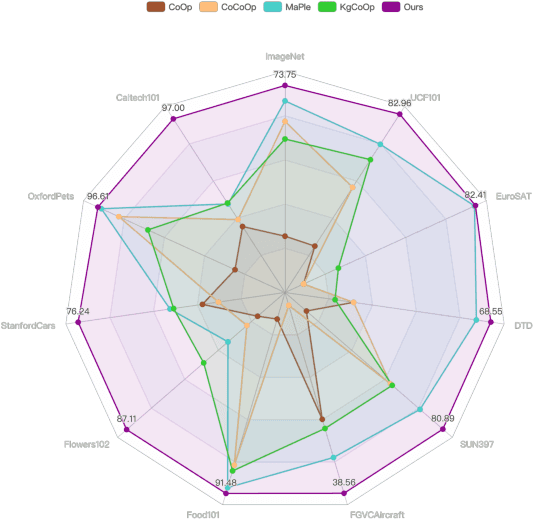

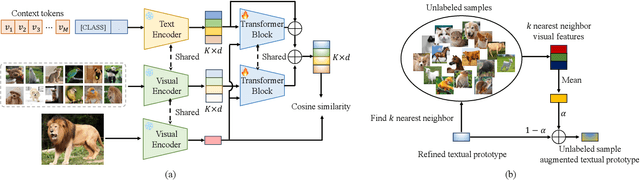

Pre-trained large-scale vision-language models (VLMs) have acquired profound understanding of general visual concepts. Recent advancements in efficient transfer learning (ETL) have shown remarkable success in fine-tuning VLMs within the scenario of limited data, introducing only a few parameters to harness task-specific insights from VLMs. Despite significant progress, current leading ETL methods tend to overfit the narrow distributions of base classes seen during training and encounter two primary challenges: (i) only utilizing uni-modal information to modeling task-specific knowledge; and (ii) using costly and time-consuming methods to supplement knowledge. To address these issues, we propose a Conditional Prototype Rectification Prompt Learning (CPR) method to correct the bias of base examples and augment limited data in an effective way. Specifically, we alleviate overfitting on base classes from two aspects. First, each input image acquires knowledge from both textual and visual prototypes, and then generates sample-conditional text tokens. Second, we extract utilizable knowledge from unlabeled data to further refine the prototypes. These two strategies mitigate biases stemming from base classes, yielding a more effective classifier. Extensive experiments on 11 benchmark datasets show that our CPR achieves state-of-the-art performance on both few-shot classification and base-to-new generalization tasks. Our code is avaliable at \url{https://github.com/chenhaoxing/CPR}.